Enhance your career, get Certified as a Data Streaming Engineer | Get Certified
Stateful Fault Tolerance



Sophie Blee-Goldman
Senior Software Engineer (Presenter)


Bill Bejeck
Integration Architect (Author)
Stateful Fault Tolerance
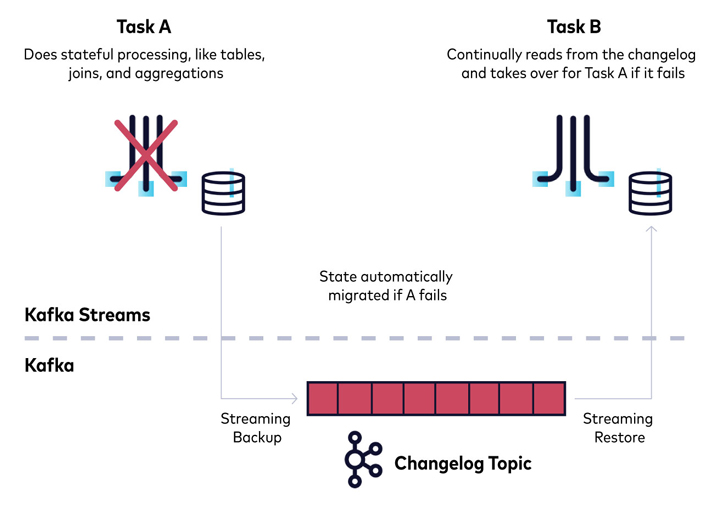
State stores in Kafka Streams are either persistent or in-memory. Both types are backed by changelog topics for durability. When a Kafka Streams application is starting up, it detects a stateful node, and if it determines that data is missing, it will restore from the changelog topic.
In-memory stores don't retain records across restarts, so they need to fully restore from the changelog topic after restarts. In contrast, persistent state stores may need little to no restoration.
Compaction
Changelog topics use compaction, whereby the oldest records for each key are deleted, safely leaving the most recent records. This means that your changelog topics won't endlessly grow in size.
Stateful Fault Tolerance
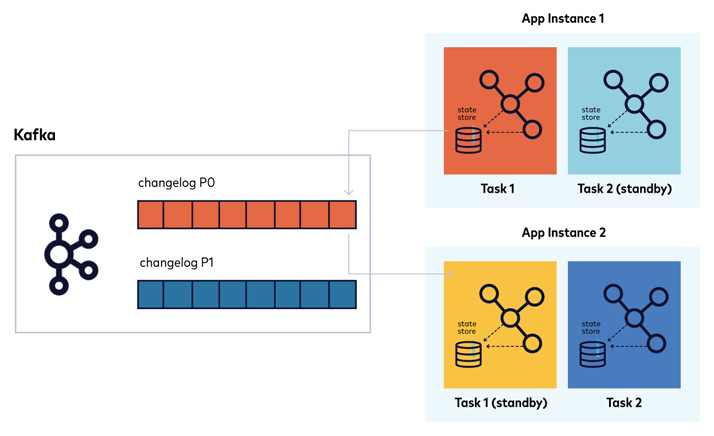
A full restore of stateful operations can take time. For this reason, Kafka Streams offers stand-by tasks. When you set num.standby.replicas to be greater than the default setting of zero, Kafka Streams designates another application instance as a standby. The standby instance keeps a mirrored store in sync with the original by reading from the changelog. When the primary instance goes down, the standby takes over immediately.
Use the promo code STREAMS101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Stateful Fault Tolerance
Hi, I'm Sophie Blee-Goldman with Confluent. In this module, we're going to talk about fault tolerance. So, Kafka Streams has stateless as well as stateful operations. For the stateful operations, obviously we need to be keeping track of some state. These are things like aggregations and joins that we discussed in earlier modules. Now, state stores themselves can be either persistent or in memory. Kafka Streams provides some out of the box, persistent state stores in the form of rock CB or just a generic in-memory state store that you can use to plug in. Now, of course, persistent stores are not actually fault tolerant by themselves, as you can always lose a disk or an entire node. And in-memory stores, obviously suffer from the same problems. So for fault tolerance, Kafka Streams has each state store backed by what we call a changelog topic for durability. And this changelog topic is what sounds like. It just writes all of the events that get sent to the state store, to this changelog topic. It is a log of the changes, and they really just serves as the source of truth for the records that are in this state store. So if you ever lose a machine with the state store, you might lose just an in-memory store, or you might have a full corrupted disk. You don't have to worry because your data is not actually gone. Your data is stored in Kafka and Kafka provides the data replication that we discussed earlier to make sure that this data itself is never going to go away just because of a single-node failure or even multi-node. So let's say you actually did lose a machine with the state store. Now, how do you get this data back out from the changelog topic? Well, when you start up, Kafka Streams will detect, first of all, that it's a stateful node. And second of all, whether there is any existing data in the changelog topic. In the case of a new application, obviously, there's no changelog topic or any data in it and you would just begin processing from an empty state. However, if there is changelog topic data, then in that case, Kafka Streams will need to fully restore all the data out of the changelog topic, and by that we just mean read the events from the changelog topic and insert them into the local state store, whether that be persistent rocks DB store, an in-memory store, or a custom user-defined store. Now in-memory stores, obviously, don't retain records across restarts. So between in-memory stores and persistent stores, you have this trade-off where, in general, in-memory's going to be faster than writing out to disk, but in the event of a failure, you're going to have to restore this in-memory store entirely from the changelog topic. So it might have longer startup times, which is a trade-off between the just general faster processing that you might get from storing something only in memory. So changelog topics use what's called compaction to delete the records without worrying about deleting information that Kafka Streams might still need. In a compacted topic the oldest records by a certain key are deleted, which means only the latest event with that same key is retained. And since for a changelog topic, we only care about what the latest, updated value for that state store is, we don't care about any of the older values. It's perfectly fine to erase or compact away all of that older data, as long as we've kept the recent record for that key. So making sure that your changelog topic uses compaction is essential. Kafka Streams will create the changelog topics for you with compaction, but if you are ever messing around with the topic configs yourself, it's important to make sure that compaction is always used for changelog topics. With the stateful operation, restoring the full amount of state from the beginning of time in this changelog can still take a lot of time, even if compaction is used. For this, Kafka Streams offers what's called standby tasks. So, this is something that you can configure Kafka Streams to use to help speed up the time that it will take to actually get in a running state after it might have to restore from a changelog and you do this by setting the num.standby.replicas config to any number greater than the default setting of zero. So for general fault tolerance and availability, we recommend setting a num.standby.replicas to something like one or greater, depending on how many nodes you have running. For a single-node Kafka Streams application using standby replicas is not going to do anything because these replicas will have nowhere to replicate to. And this is because the way standbys work is by Kafka Streams designating another instance of this application as the standby for a specific task. So you have the active task, which is actually doing the processing that you define in the processing topology and then you have what's called a standby task, which is just keeping the state for that same task up to speed from the changelog topic without doing any of the actual processing itself. So it just sits there. It reads from the changelog topic into the local state store, keeping it in sync without doing any processing. That means when the primary or the active node goes down, the standby can take over for that operation and just start resuming the processing from wherever it left off without taking the downtime to fully restore it from the changelog topic. That's how fault tolerance works in Kafka Streams and how you can get around the availability trade-offs by configuring it to use standby replicas.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.