Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Introduction to Streaming Data Pipelines



Tim Berglund
VP Developer Relations
Introduction to Streaming Data Pipelines
A streaming pipeline is where we send data from a source to a target as the data happens, in a stream. Contrast this to a batch world where we wait for a period of time (maybe hours or days) before collecting a bunch of the data and then sending it to the target.
There are several good reasons for wanting to use a streaming pipeline, including:
-
Ensuring more accurate data in the target system
-
Reacting to data as it changes, while it is current and relevant
-
Spreading the processing load and avoiding resource shortages from a huge influx of data
In the context of Apache Kafka, a streaming data pipeline means ingesting the data from sources into Kafka as it's created and then streaming that data from Kafka to one or more targets. In this example, we're offloading transactional data from a database to an object store, perhaps for analytical purposes.

Because Kafka is a distributed system, it's highly scalable and resilient. By decoupling the source from the target, and by using Kafka to do this, we gain some great benefits.
If the target system goes offline, there's no impact to the pipeline; when the target comes back online, it just resumes from where it got to before, because Kafka stores the data. If the source system goes offline, the pipeline also is unimpacted. The target doesn't even realize that the source is down; it just sees that there's no data. When the source comes back online, data will start to flow again.
If the target can't keep up with the rate of data being sent to it, Kafka will take the backpressure.
Pipelines built around Kafka can evolve gracefully. Because Kafka stores data, we can send the same data to multiple targets independently. We can also replay the data, either to back-populate new copies of a target system or to recover a target system after a failure.
Pipelines aren't just about streaming the same data from one place to another. Of course, you can use it to do this. (You can also just use an iPhone to make a telephone call.)
Consider a typical transactional relational database. The data is probably normalized. Events (facts) in one table. Reference information on several others. For analytics, you need to denormalize that data so that you can say for each event (such as an order) what were the additional pieces of information about it (such as the customer who placed it).
You could do this on the target system, but in practice, it makes a lot of sense to do this as part of the stream itself instead of as a batch process later on. This is where the second part of streaming pipelines comes in: stream processing—not just getting data from one place to another, but modifying the data as it passes through.
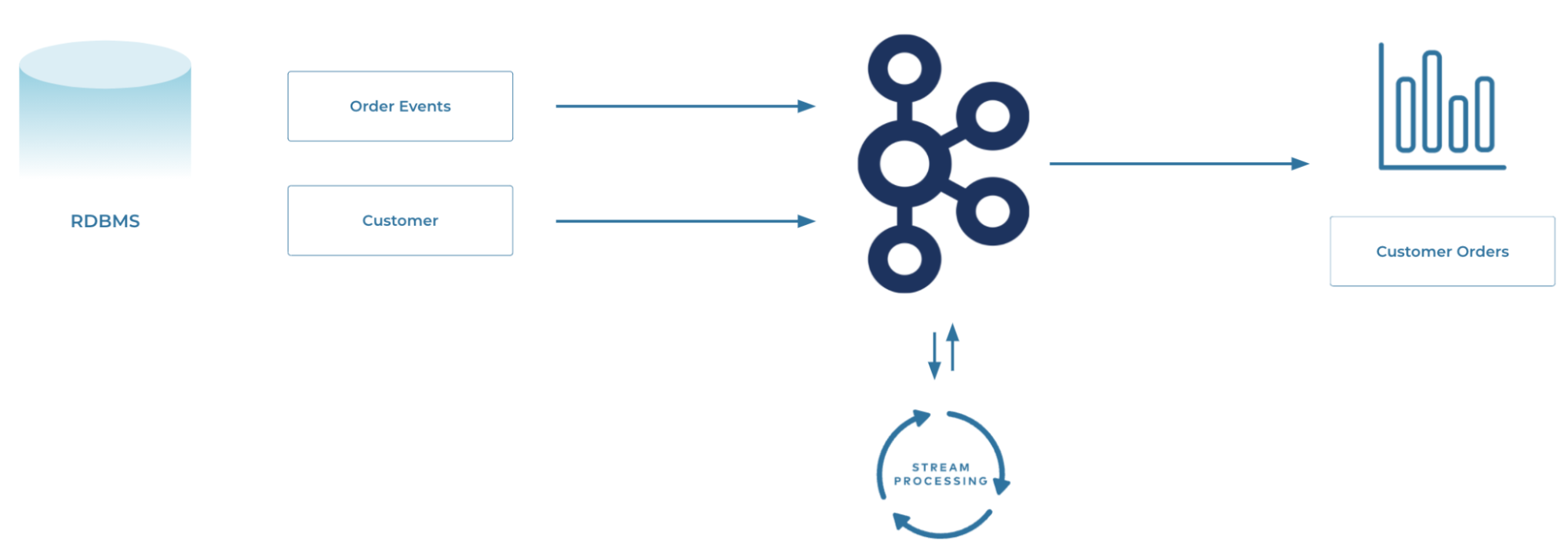
This could be joining data together, filtering it, deriving new values, applying calculations, aggregating it…all the kinds of things that we do to data to apply business logic to drive processes and analytics.
Using Kafka for all of this makes even more sense when we consider the logical evolution of computer systems. What starts off as a single system one day evolves over the months and years into a group of polyglot systems. With Kafka, we can take the same logical data and simply wire it up to different sources and targets as they change.
Errata
- The Confluent Cloud signup process illustrated in this video includes a step to enter payment details. This requirement has been eliminated since the video was recorded. You can now sign up without entering any payment information.
- Previous
- Next
Use the promo code PIPELINES101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Introduction to Streaming Data Pipelines
Hi, I'm Tim Berglund with Confluent. Welcome to streaming data pipelines lesson one introduction. Well, one might begin by asking what even is a streaming pipeline. I think that would be a fair question. Fundamentally it's where we send data from a source to a target as the data happens in real-time as a stream. And there may be some things we do in the middle from between that source and target also. You wanna contrast that with the batch world, where we would wait for some time, maybe hours or a day or something like that before collecting a bunch of data, that's sitting statically all in one place and then sending it to the target. So in a pipeline, we're doing it piece by piece as things happen. Now, there are a bunch of good reasons for wanting to do this including you can get more accurate and more up to date data in the target system. 'Cause you don't wait except for how long it takes data to propagate through the pipeline. You get to react to data as it changes when it's current and relevant and probably more valuable to some business that might be operating this pipeline. It lets you scale the pieces of the processing load with a little bit more control. And avoids the kinds of resource shortages that can happen when there's a huge influx of data in this big batch job that you only need the compute in the IO every so often. You just get potentially more economical use of your computing and storage resources. In the context of Kafka, a streaming data pipeline means ingesting the data from some source system into Kafka as the data is created. That's very abstract, we'll make it more concrete as we go on, don't worry. And then streaming that data from Kafka to one or more target systems. In this example, we're offloading transactional data from a database. So stuff is happening in a business, transactions are being committed and that's getting offloaded to an object store maybe for some offline analytical operations to happen. Because Kafka is a distributed system. It's very scalable, it's very resilient. There's all kinds of great things happening with Kafka as a distributed log there. And by decoupling the source from the target and using Kafka as a durable log in between, there are a few pretty cool benefits. Number one, Kafka stores the data for as long as we'd like, that's configurable, I've purposely called it a log. It's not a queue. It's actually a data storage system. So if the target system goes down, then there isn't any longterm permanent impact to the pipeline. It might be bad for the target system to go down at any moment that could have business impact, but the pipeline is okay, that data is being logged in Kafka. And as soon as the target system comes back up, it presumes and is able to catch up from right before when it went down. If the source system goes offline, the pipeline is still fine. Now somebody might be sad, right? There might be slack messages. There might be incident response teams getting into gear, but the pipeline is okay. That's not something anybody needs to worry about. The target doesn't even know that the source is down. It just sees that there's less traffic or no traffic. And when the source comes back, online, data will start to flow again, more or less automatically. Pipelines built around Kafka can evolve gracefully a piece at a time. Because Kafka stores data, remember, it's a log. We can send that same store data to multiple targets independently. We can also replay the data you can rewind to an earlier point in the log either to back populate new copies of a new target system or to recover from some kind of failure, maybe a bug was deployed and in some kind of analysis being done in the target and you wanna rewind and try again, those things are all pretty easy to do with Kafka. Pipelines aren't about just streaming data from point a to point B unmodified. Now you can do that. It's not bad, but it's kind of entry level pipeline use. The least value add. I mean, you could also so own an iPhone and only make voice telephone calls with it. Maybe that would be something you do. And I could imagine a little peace cardboard on a piece of tape or you could flip it open and make it feel like a flip phone. You could do that, that wouldn't, I don't think anybody should judge you for that. But we can potentially grow into more. So consider a typical transactional relational database. So this is an OLTP system. The data's probably normalized, it sort of ought to be and transactions or entities or events there's lots of different ways to think about it, but they're probably entities, right? They are stored in a table. And then reference information is in several other tables related by a foreign keys. For analytics, you need to denormalize that data. You need to basically prejoin it and write that de-normalized thing to a separate database. So that you can say for each event or each entity or order or whatever it is. Let's just say it's an order. What were the additional pieces of information about it? Who was the customer? What were the line items of the order? What was the shipping address? All of these things would be de-normalized and you probably wanna bring that stuff together in one or another for analytics purposes, you wanna pre-join or just de-normalized. You could do that on the target system, but in practice, that's not really how it's done. It gets done in the middle on the part of the stream gets done in the stream, instead of as a batch process later on it just works better to do that. And this is where the second important part of a streaming pipeline comes in. I'm kind of beating around the bush, talking about stream processing. So we'll not just getting data from A to B, but we're doing computation on it in the middle. We extract it from A do things to it to make it more valuable and then export it or one might say load it into B into the sync system. This could just be a joint. Like I was just talking about it, de-normalizing, it could be filtering, could be deriving new values, applying calculations, aggregating, running expensive and fancy ML model. Anything that you might do in between to apply the business logic of the business to that data, to drive the processes and analytics that we wanna do. Using Kafka for this makes even more sense when we consider the logical evolution of computer systems. What starts as a single system may one day evolve over the months and years into a group of polyglot systems. It's gonna happen. I mean, look at this slide, in the slides have been showing you there's a source system and there's Kafka and there's a sync and boy that's like living in a Star Trek episode, right? Everything is beautiful and shiny and high-tech, and it doesn't stay that way. They get much more complicated and using Kafka, you can take the same logical data, that same stuff you've extracted from the source system and write it to different syncs and do different kinds of computation on it and create new derived versions of that stream in the middle there's all kinds of stream processing. You wanna think of them as computational options that you've got in the middle. So that wraps it up for our introduction. Next up, we're gonna take a look at an exercise. And before we do that, you're gonna want to sign up on Confluent Cloud. You're gonna have the opportunity to work along with the things that I'm showing you in the exercises, and they're gonna be happening as much as possible in Confluent Cloud. So use this link I'm showing you right here and this promo code, it'll get you 101 free dollars of Confluent Cloud usage. Go get that stuff, fired up. I do wanna note, since we're using some ksqlDB here, that leaving your ksqlDB app up and running for a long period of time can eat into that $101. So make sure you really sat down at a time that you can really work through all this stuff in a sitting. I think you'll learn a lot. You'll get to use cloud and you shouldn't have to pay a dime for working through these exercises. Follow along and we'll see what we can build. So when you get to this form, enter your name, email and password. The email and password will be used to log in to Confluent Cloud in the web UI later and from the command line. So be sure to remember these credentials then, it's probably obvious, but, put it in a secure password manager or however it is, you keep track of your passwords in a secure way. Then click on the start free button and watch your inbox for a confirmation email to continue. The link in your confirmation email will lead you to the next step where you can choose your cluster type. You'll choose between a basic standard or dedicated cluster. The associated costs are listed for each and the startup amount credit that we've provided here, will be more than enough to cover everything you need for this course. So we're gonna go with standard. Then click begin configuration to choose your preferred cloud provider, region and availability zone. Again, costs will vary with those choices, but at every point we show you what those costs are at the bottom of the screen. And we'll continue to set a billing info here. Here you'll see that you will receive some free cloud credit to get you started, like we were talking about before, and by entering the pipelines 101 promo code that I'd mentioned, you get an extra $101 on top of the standard starting credit. And that should be more than enough to get you through the exercises. Although, let me caution you, in this course, we're using ksqlDB. And if you leave your ksqlDB application running, that can chew up your free credits. So be sure when you do this course, you do the exercises set aside some time to be able to go through all the exercises at once. That way you won't have to pay if you're a new cloud user, you won't have to pay for this learning that you're doing. Click review to get one last look at the choices you've made, then launch your new cluster. So, sign up, get started today. Let's apply this in an exercise.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.