Introduction to Streaming Data Pipelines



Tim Berglund
VP Developer Relations



Robin Moffatt
Principal Developer Advocate (Author)
Introduction to Streaming Data Pipelines
A streaming pipeline is where we send data from a source to a target as the data happens, in a stream. Contrast this to a batch world where we wait for a period of time (maybe hours or days) before collecting a bunch of the data and then sending it to the target.
There are several good reasons for wanting to use a streaming pipeline, including:
-
Ensuring more accurate data in the target system
-
Reacting to data as it changes, while it is current and relevant
-
Spreading the processing load and avoiding resource shortages from a huge influx of data
In the context of Apache Kafka, a streaming data pipeline means ingesting the data from sources into Kafka as it's created and then streaming that data from Kafka to one or more targets. In this example, we're offloading transactional data from a database to an object store, perhaps for analytical purposes.

Because Kafka is a distributed system, it's highly scalable and resilient. By decoupling the source from the target, and by using Kafka to do this, we gain some great benefits.
If the target system goes offline, there's no impact to the pipeline; when the target comes back online, it just resumes from where it got to before, because Kafka stores the data. If the source system goes offline, the pipeline also is unimpacted. The target doesn't even realize that the source is down; it just sees that there's no data. When the source comes back online, data will start to flow again.
If the target can't keep up with the rate of data being sent to it, Kafka will take the backpressure.
Pipelines built around Kafka can evolve gracefully. Because Kafka stores data, we can send the same data to multiple targets independently. We can also replay the data, either to back-populate new copies of a target system or to recover a target system after a failure.
Pipelines aren't just about streaming the same data from one place to another. Of course, you can use it to do this. (You can also just use an iPhone to make a telephone call.)
Consider a typical transactional relational database. The data is probably normalized. Events (facts) in one table. Reference information on several others. For analytics, you need to denormalize that data so that you can say for each event (such as an order) what were the additional pieces of information about it (such as the customer who placed it).
You could do this on the target system, but in practice, it makes a lot of sense to do this as part of the stream itself instead of as a batch process later on. This is where the second part of streaming pipelines comes in: stream processing—not just getting data from one place to another, but modifying the data as it passes through.
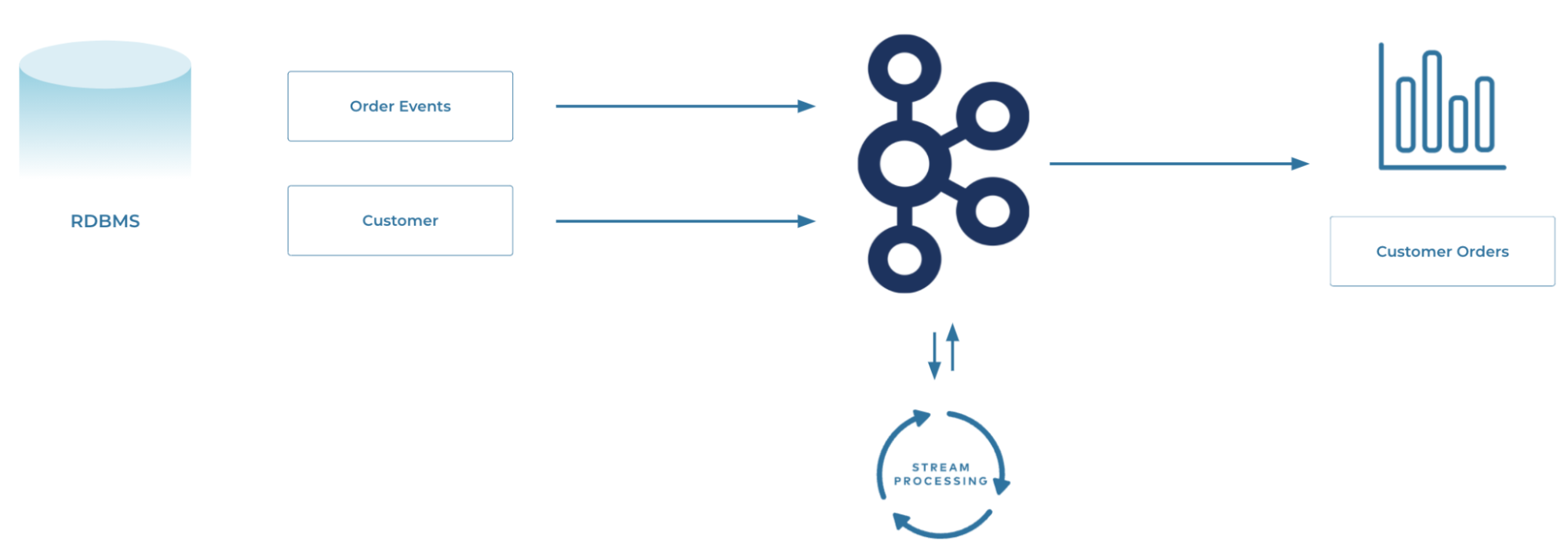
This could be joining data together, filtering it, deriving new values, applying calculations, aggregating it…all the kinds of things that we do to data to apply business logic to drive processes and analytics.
Using Kafka for all of this makes even more sense when we consider the logical evolution of computer systems. What starts off as a single system one day evolves over the months and years into a group of polyglot systems. With Kafka, we can take the same logical data and simply wire it up to different sources and targets as they change.
Errata
- The Confluent Cloud signup process illustrated in this video includes a step to enter payment details. This requirement has been eliminated since the video was recorded. You can now sign up without entering any payment information.
- Previous
- Next
Use the promo code PIPELINES101 to receive $25 of free Confluent Cloud usage
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.