Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Integrating Kafka with External Systems



Tim Berglund
VP Developer Relations
Integrating Kafka with external systems
As we saw in the previous lesson, streaming pipelines are made up of at least two—and often three—components: ingest, egress, and optionally processing. Streaming ingest and egress between Kafka and external systems is usually performed using an Apache Kafka component called Kafka Connect.
Using Kafka Connect, you can create streaming integration with numerous different technologies, including:
-
Cloud object stores, such as Amazon S3, Azure Blob Storage, and Google Cloud Storage
-
Document stores like Elasticsearch
-
SaaS platforms such as Salesforce
-
…and so many more
There are lots of connectors available on Confluent Cloud. These connectors are fully managed, which means you have zero infrastructure to operate, monitor, and upgrade; you only need to configure them with the necessary settings, using the graphical interface, API, or command line.
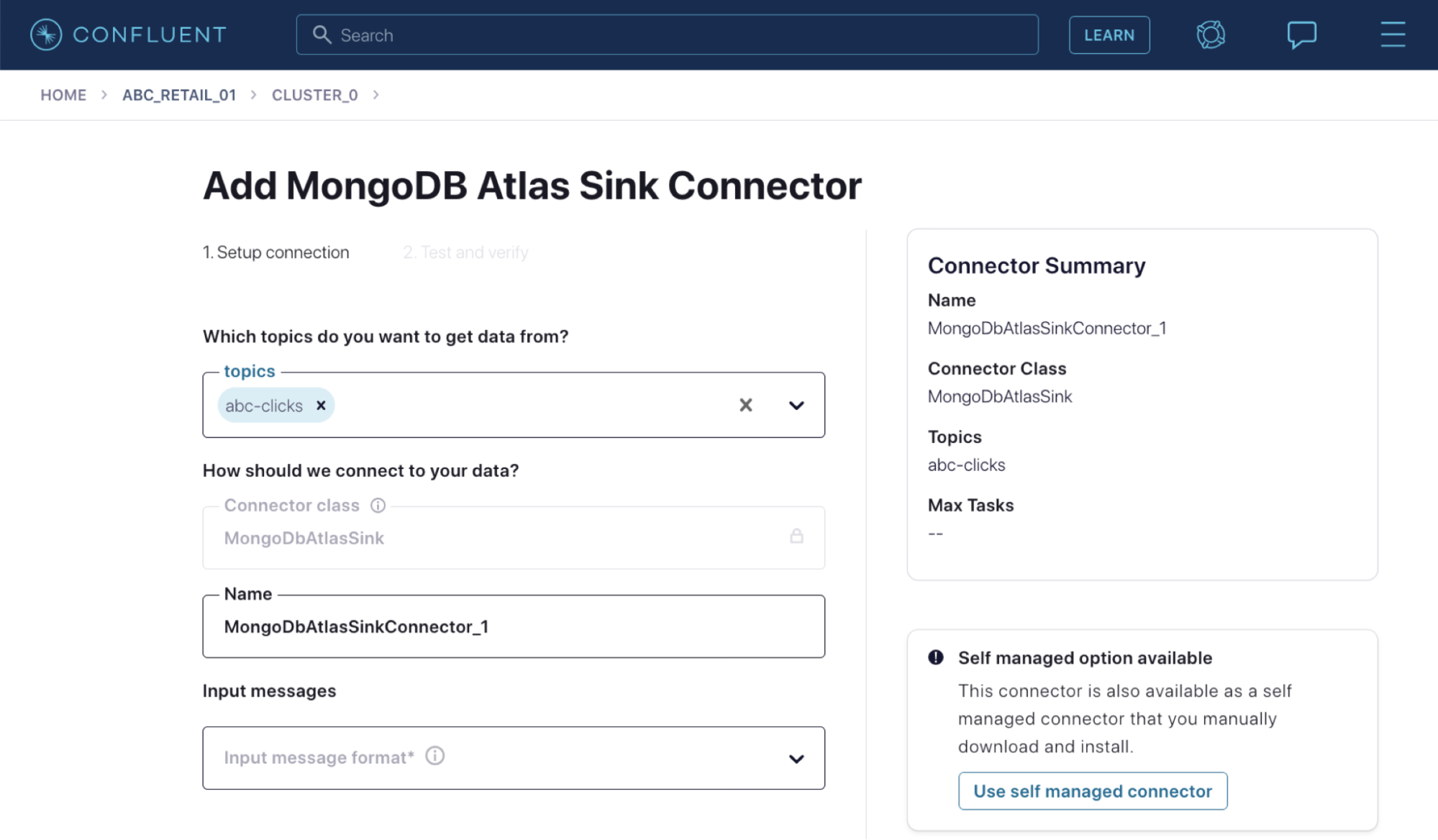
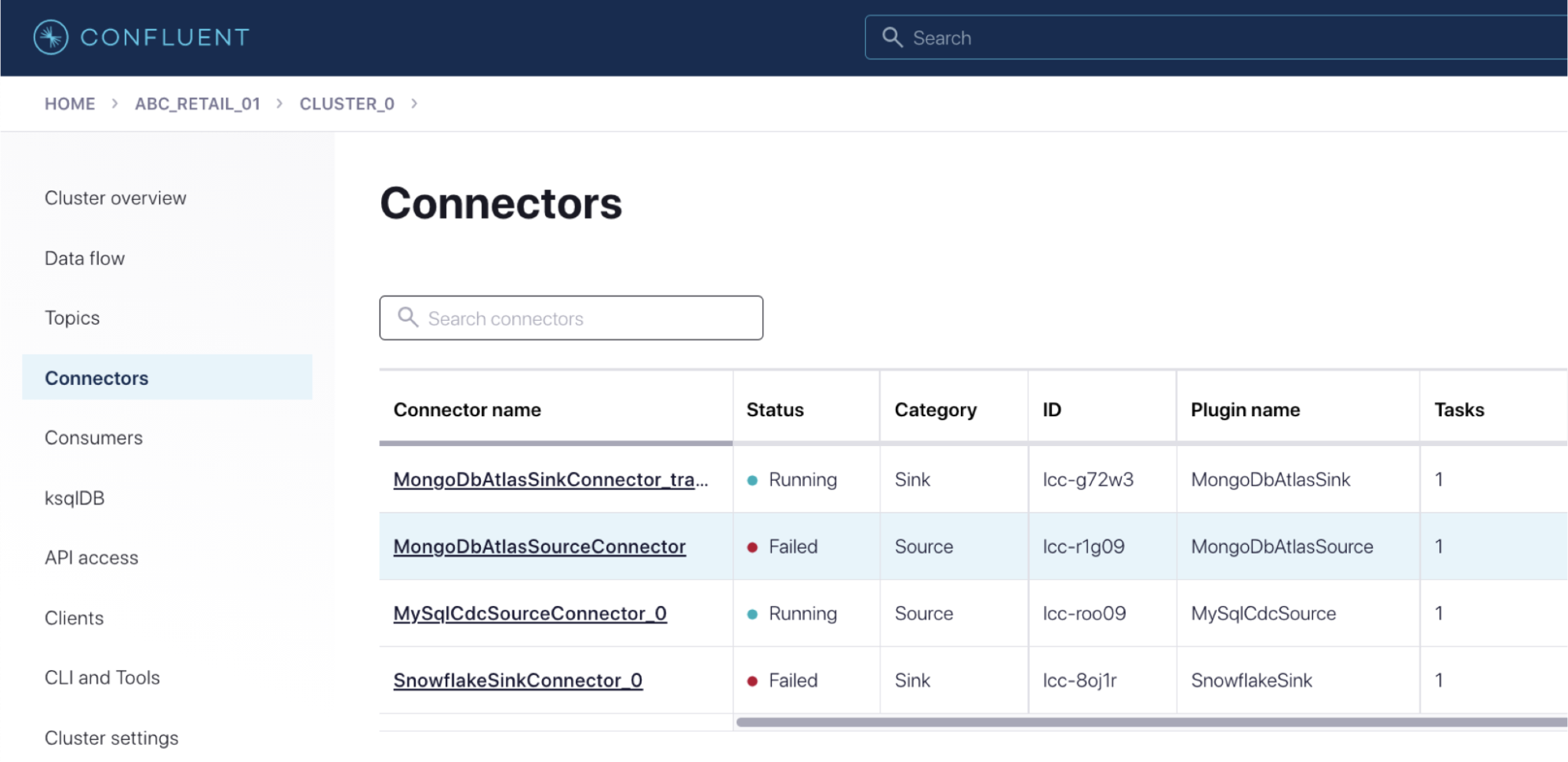
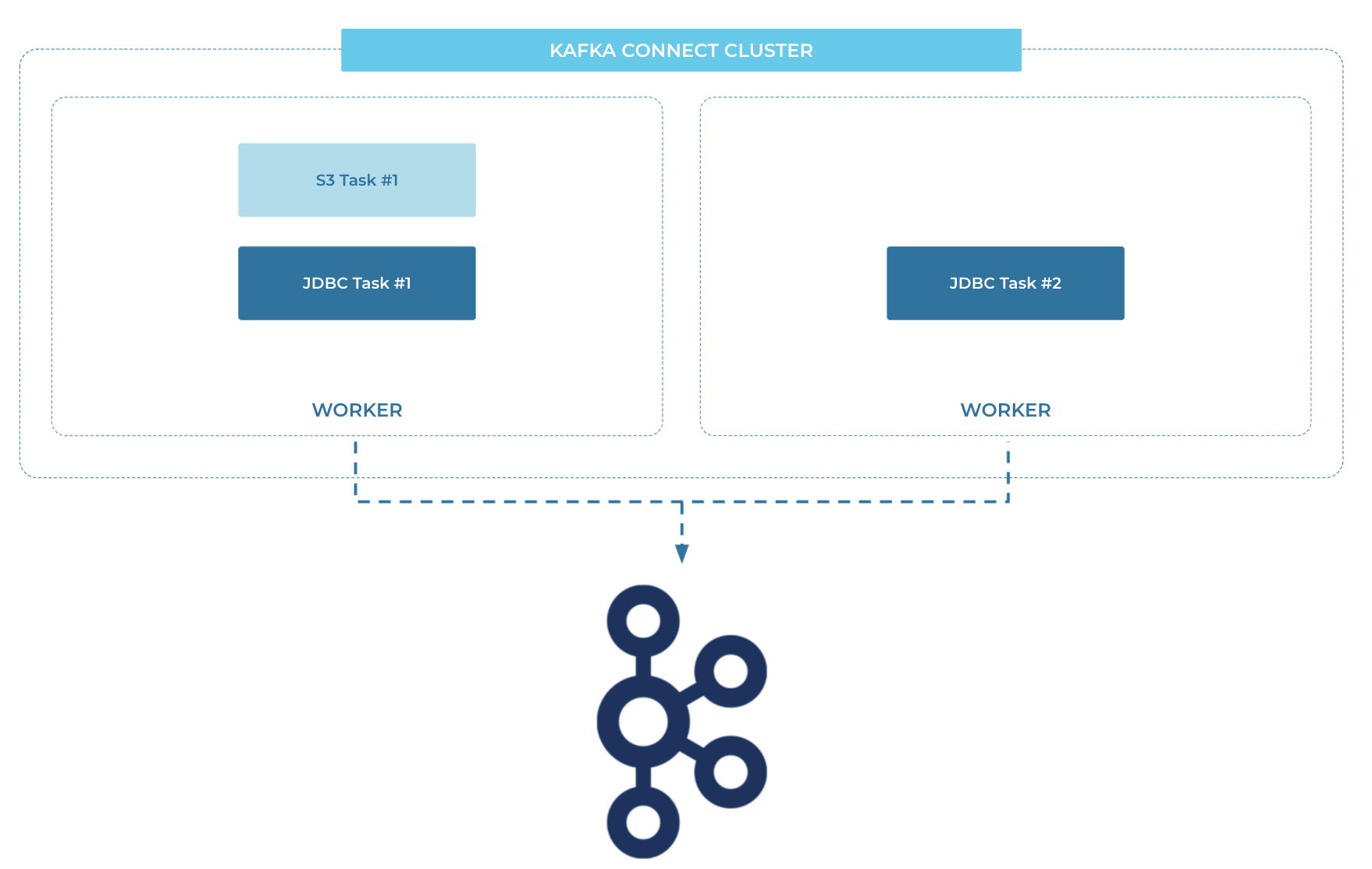
You can also run Kafka Connect yourself. It's a fully distributed system, making it scalable and resilient. You might choose to run your own Kafka Connect cluster if you also run your own Kafka brokers, or if you are using Confluent Cloud but need a particular connector that's not offered on it yet (such as a custom connector you have built yourself).
You can use the Confluent UI to configure Kafka Connect, and you can also use the Kafka Connect REST API to send it configuration in JSON.
{
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url" : "jdbc:mysql://asgard:3306/demo",
"table.whitelist": "sales,orders,customers"
[…]
}
Whichever way you configure Kafka Connect, and whether you use fully managed connectors or self-managed, there is no coding required to integrate between Kafka and these other systems—it's just configuration!
Use the promo code PIPELINES101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Integrating Kafka with External Systems
Hi, I'm Tim Berglund with Confluent. Welcome to data pipelines lesson two, integrating Kafka with external systems. Now, as we well in the introductory lesson, streaming pipelines are made up of two, potentially three components. There's ingress and egress, that's the two and optionally computation or stream processing in the middle. Which I hope that you're availing yourself of that option too. So streaming ingest and egress between Kafka and an external source system or sink system is usually done using a component of the Kafka ecosystem called Kafka Connect. Using Kafka Connect, you can create streaming integration with a number of different things. These are things that are not Kafka, right? Unfortunately, there are these things in the world that aren't Kafka and we need to talk to them. Things like relational databases, Oracle, Postgres, MySQL, Message queues, Active MQ, IBM MQ , JMS thing providers, whatever you might have. Cloud data warehouses like BigQuery and Snowflake, very common sink systems, no SQL stores like Cassandra, MongoDB, SaaS platforms like Salesforce. There's all kinds of things we might want to read from Salesforce and do interesting computation on it and put those computed events somewhere else. We've got a course elsewhere that explains Kafka Connect and its architecture and how to use it and how to troubleshoot it and all kinds of things like that. Suffice it to say for now that Kafka Connect is this thing into which we plug connectors and a connector is what reads from a source system or writes to a sink system. And there are lots of those connectors available on Confluent Cloud. It's a constantly growing think of it as a little family, a family of a lot of different things that's expanding all the time. And these are managed as a part of the cloud product you just click on one and configure it. And it looks kinda like this. If I clicked on the MongoDB sink connector, I'd type in a host name and some credentials and maybe the name of a topic and the name of a collection in the sink database and all the, whatever the configuration parameters I'd need for that given connector, I've got this nice web UI that lets me do that and then I've got a list of connectors off you go that connector is running in the fully managed cloud infrastructure with just so many things you don't have to worry about. If you've taken the connect course, or if you go take it after this one, it really is. If you wanna dive deep into data pipeline stuff you should be good at connect. So that's a good adjunct to this. And then you'll appreciate everything that's going on here behind this nice web form and this polite little list of connectors. There's really a lot of stuff being managed for you in Confluent Cloud. But of course you can run Kafka Connect yourself. It's a fully distributed system on its own. It's scalable, it's fault tolerant can run your own connect cluster. So you'll deploy some sort of server instance and run this JVM process that is Kafka Connect. And, that's your connect cluster. If you're using Confluent Cloud and the connector that you wanna use is a fully managed option in Confluent Cloud, there's no reason you do that. You really wouldn't want to run it on your own, but if you're not using cloud, if you manage your own infrastructure. Because of a personal conviction or a regulatory reason or whatever the reason is. Or you wanna use cloud, but you're using a connector, that's not offered there yet then you can run your own connect cluster. Again, if you are into the self-managed life, for whatever reason, you can find hundreds of connectors at the Confluent Hub. And that's just a hub.confluent.io or confluent.io/hub, they both get you there. And it looks kind of like this you can type in a keyword to search on say you wanna find a connector for, some SaaS application that you need to extract data from. Maybe it's there or you're curious is Postgres there spoiler Postgres is definitely there. You can just search for that you find the relevant matching connectors. Tells you about their license, some of them are open source some of them are community licensed. Some of them are commercial and they're available, but you'll have to pay for a license to use them under production conditions or whatever the conditions of the license are. That's all there on Confluent Hub. It's nice to have that kind of semi curated set of things with all of that metadata develop and searchable. It beats looking around on GitHub and for code that you're gonna go then, mvn clean install, actually, of course we know you'd may have been verify you wouldn't mvn clean install but you take my point. In this course, we're gonna concentrate on pipelines that we can build with Kafka Connect and more to the point with managed Kafka Connect in Confluent Cloud. So I'll say again, go take that Kafka Connect course, if you really want to deep dive when you're done with this course. But you don't need it now, you really are getting enough of connect if you're brand new to this stuff, to be able to think about data pipelines in Confluent Cloud, and that's what we're gonna do in the next exercise, in the following lessons, we're gonna build one out. So stick with us and we'll learn what these pieces are.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.