Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
How to get the top (or bottom) N events with Flink SQL
How to get the top (or bottom) N events with Flink SQL
Suppose you monitor some service or product, and you want to see the top uses from an event stream. For example, consider working as an analyst for a video streaming service like Netflix or Hulu. You want to see the top three movies by max number of views in real time. To do this ranking, you can use a Top-N query.
Setup
Let's assume the following DDL for our base movie_views table:
TABLE movie_views (
id INT,
title STRING,
genre STRING,
num_views BIGINT
);Compute the Top-N views
Given the movie_views table definition above, we can retrieve the top three movies by genre that have max views in real time.
SELECT title, genre, num_views, category_rank
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY genre ORDER BY num_views DESC) as category_rank
FROM movie_views
)
WHERE category_rank <= 3;The subquery here is doing the heavy lifting, so let's take a detailed look at it. The subquery orders the movies by the number of views (descending) and assigns a unique number to each row. This process makes it possible to rank movies where the row number is less than or equal to three. Let’s discuss the critical parts of the subquery:
- ROW_NUMBER() starting at one, this assigns a unique, sequential number to each row which we've labeled category_rank
- PARTITION BY specifies how to partition the data. By using a partition you'll get the ranking per genre. If you left off the PARTITION BY clause you would get the top 3 ranking of all movies across all categories.
- ORDER BY orders by the provided column. By default ORDER BY puts rows in ascending (ASC) order. By using ASC order you’ll get the least viewed movies, but since you want the top viewed the query uses DESC.
Running the example
You can run the example backing this tutorial in one of three ways: a Flink Table API-based JUnit test, locally with the Flink SQL Client against Flink and Kafka running in Docker, or with Confluent Cloud.
Flink Table API-based test
Prerequisites
- Java 17, e.g., follow the OpenJDK installation instructions here if you don't have Java.
- Docker running via Docker Desktop or Docker Engine
Run the test
Clone the confluentinc/tutorials GitHub repository (if you haven't already) and navigate to the tutorials directory:
git clone git@github.com:confluentinc/tutorials.git
cd tutorialsRun the following command to execute FlinkSqlTopNTest#testTopN:
./gradlew clean :top-N:flinksql:testThe test starts Kafka and Schema Registry with Testcontainers, runs the Flink SQL commands above against a local Flink StreamExecutionEnvironment, and ensures that the aggregation results are what we expect.
Flink SQL Client CLI
Prerequisites
- Docker running via Docker Desktop or Docker Engine
- Docker Compose. Ensure that the command docker compose version succeeds.
Run the commands
Clone the confluentinc/tutorials GitHub repository (if you haven't already) and navigate to the tutorials directory:
git clone git@github.com:confluentinc/tutorials.git
cd tutorialsStart Flink and Kafka:
docker compose -f ./docker/docker-compose-flinksql.yml up -dNext, open the Flink SQL Client CLI:
docker exec -it flink-sql-client sql-client.shFinally, run following SQL statements to create the movie_views table backed by Kafka running in Docker, populate it with test data, and run the Top-N query.
CREATE TABLE movie_views (
id INT,
title STRING,
genre STRING,
num_views BIGINT
) WITH (
'connector' = 'kafka',
'topic' = 'movie_views',
'properties.bootstrap.servers' = 'broker:9092',
'scan.startup.mode' = 'earliest-offset',
'key.format' = 'raw',
'key.fields' = 'id',
'value.format' = 'json',
'value.fields-include' = 'EXCEPT_KEY'
);INSERT INTO movie_views (id, title, genre, num_views)
VALUES (123, 'The Dark Knight', 'Action', 100240),
(456, 'Avengers: Endgame', 'Action', 200010),
(789, 'Inception', 'Sci-Fi', 150000),
(147, 'Joker', 'Drama', 120304),
(258, 'The Godfather', 'Drama', 300202),
(369, 'Casablanca', 'Romance', 400400),
(321, 'The Shawshank Redemption', 'Drama', 500056),
(654, 'Forrest Gump', 'Drama', 350345),
(987, 'Fight Club', 'Drama', 250250),
(135, 'Pulp Fiction', 'Crime', 160160),
(246, 'The Godfather: Part II', 'Crime', 170170),
(357, 'The Departed', 'Crime', 180180),
(842, 'Toy Story 3', 'Animation', 190190),
(931, 'Up', 'Animation', 200200),
(624, 'The Lion King', 'Animation', 210210),
(512, 'Star Wars: The Force Awakens', 'Sci-Fi', 220220),
(678, 'The Matrix', 'Sci-Fi', 230230),
(753, 'Interstellar', 'Sci-Fi', 240240),
(834, 'Titanic', 'Romance', 250250),
(675, 'Pride and Prejudice', 'Romance', 260260);SELECT title, genre, num_views, category_rank
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY genre ORDER BY num_views DESC) as category_rank
FROM movie_views
)
WHERE category_rank <= 3;The query output should look like this:
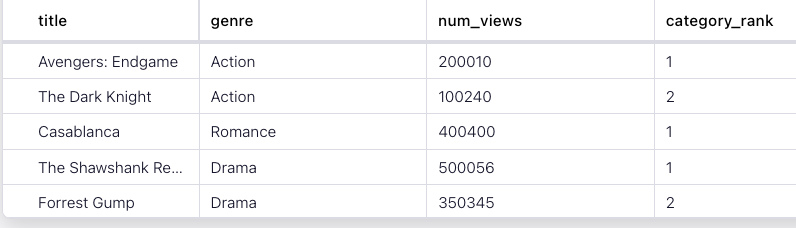
title genre num_views category_rank
Avengers: Endgame Action 200010 1
The Dark Knight Action 100240 2
Casablanca Romance 400400 1
The Shawshank Redemption Drama 500056 1
Forrest Gump Drama 350345 2
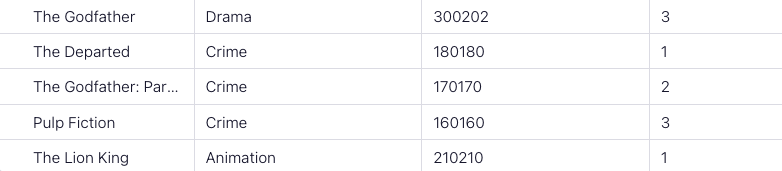
The Godfather Drama 300202 3
The Departed Crime 180180 1
The Godfather: Part II Crime 170170 2
Pulp Fiction Crime 160160 3
The Lion King Animation 210210 1
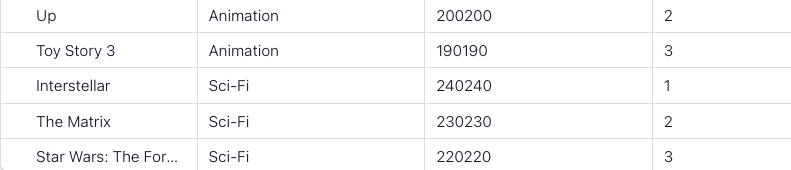
Up Animation 200200 2
Toy Story 3 Animation 190190 3
Interstellar Sci-Fi 240240 1
The Matrix Sci-Fi 230230 2
Star Wars: The Force Awakens Sci-Fi 220220 3
Pride and Prejudice Romance 260260 2
Titanic Romance 250250 3 When you are finished, clean up the containers used for this tutorial by running:
docker compose -f ./docker/docker-compose-flinksql.yml downConfluent Cloud
Prerequisites
- A Confluent Cloud account
- A Flink compute pool created in Confluent Cloud. Follow this quick start to create one.
Run the commands
In the Confluent Cloud Console, navigate to your environment and then click the Open SQL Workspace button for the compute pool that you have created.
Select the default catalog (Confluent Cloud environment) and database (Kafka cluster) to use with the dropdowns at the top right.
Finally, run following SQL statements to create the movie_views table, populate it with test data, and run the Top-N query.
CREATE TABLE movie_views (
id INT,
title STRING,
genre STRING,
num_views BIGINT
);INSERT INTO movie_views (id, title, genre, num_views)
VALUES (123, 'The Dark Knight', 'Action', 100240),
(456, 'Avengers: Endgame', 'Action', 200010),
(789, 'Inception', 'Sci-Fi', 150000),
(147, 'Joker', 'Drama', 120304),
(258, 'The Godfather', 'Drama', 300202),
(369, 'Casablanca', 'Romance', 400400),
(321, 'The Shawshank Redemption', 'Drama', 500056),
(654, 'Forrest Gump', 'Drama', 350345),
(987, 'Fight Club', 'Drama', 250250),
(135, 'Pulp Fiction', 'Crime', 160160),
(246, 'The Godfather: Part II', 'Crime', 170170),
(357, 'The Departed', 'Crime', 180180),
(842, 'Toy Story 3', 'Animation', 190190),
(931, 'Up', 'Animation', 200200),
(624, 'The Lion King', 'Animation', 210210),
(512, 'Star Wars: The Force Awakens', 'Sci-Fi', 220220),
(678, 'The Matrix', 'Sci-Fi', 230230),
(753, 'Interstellar', 'Sci-Fi', 240240),
(834, 'Titanic', 'Romance', 250250),
(675, 'Pride and Prejudice', 'Romance', 260260);SELECT title, genre, num_views, category_rank
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY genre ORDER BY num_views DESC) as category_rank
FROM movie_views
)
WHERE category_rank <= 3;The query output should look like this: