Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Hands-on Exercise: Stream Processing With Flink SQL

Gilles Philippart
Principal Software Practice Lead
Flink SQL Tutorial: Real-Time Event Filtering and Aggregation
In this exercise, you’ll learn how to manipulate your data using Apache Flink® SQL. Up until now, we’ve been producing data to and reading data from an Apache Kafka® topic without any intermediate steps. With stream processing, we can do so much more!
In a previous exercise, we created a Datagen Source Connector to generate a stream of orders to a Kafka topic in AVRO format. This exercise relies on the data produced by that connector, so make sure to complete it before proceeding.
Before we start, ensure that your Datagen Source Connector is still up and running.
When using Confluent Cloud, each Kafka topic is automatically turned into a Flink table that leverages any associated schema. Besides, working with Flink SQL streams is easy and often shorter than writing Java or Python programs. Just follow these steps and see by yourself!
-
From your cluster overview page, navigate to the orders topic.
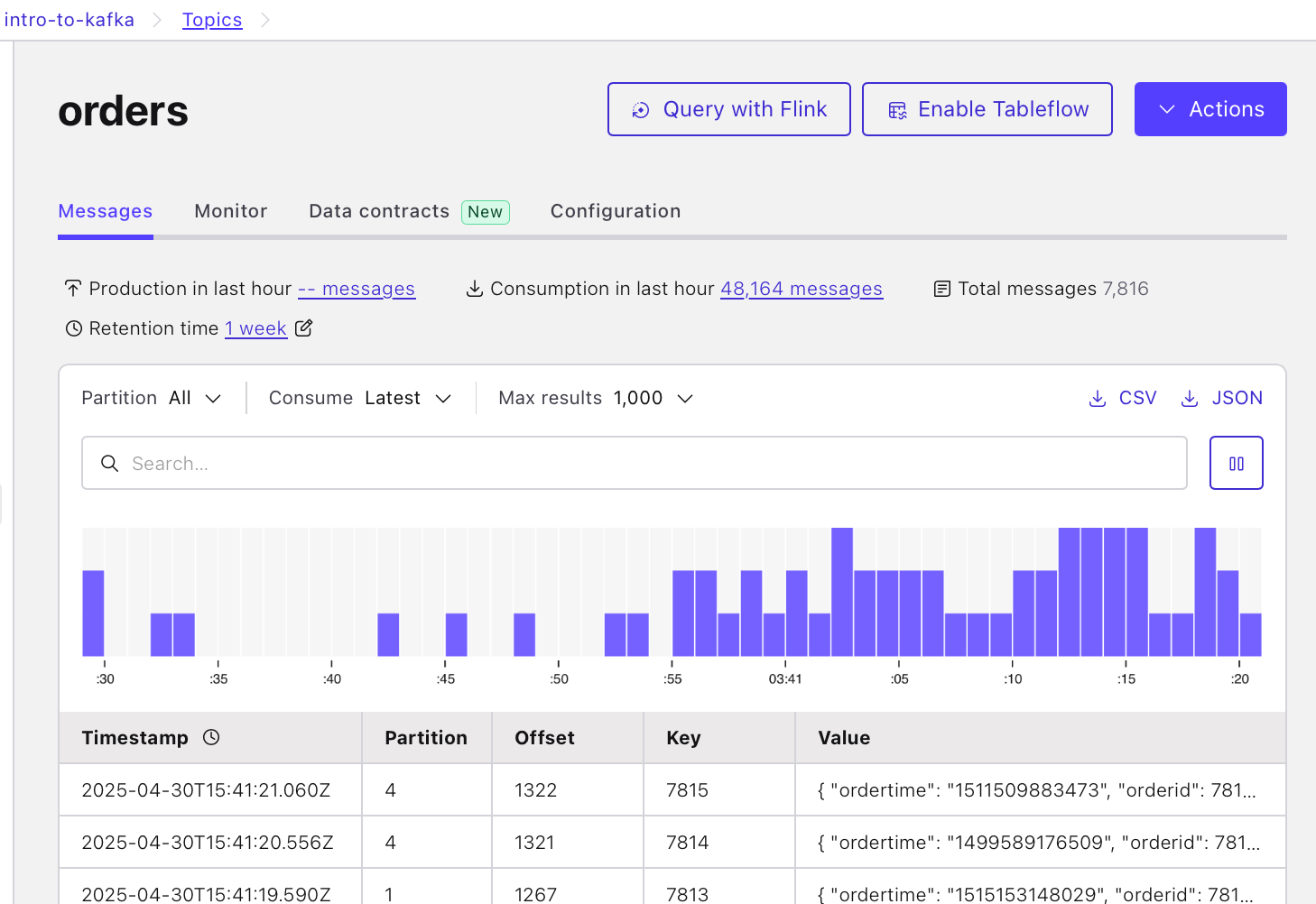
-
Click on the "Query with Flink" button at the top.
-
Run the query displayed by default, for example (adjust for your cluster name):
SELECT * FROM `demos`.`intro-to-kafka`.`orders` LIMIT 10;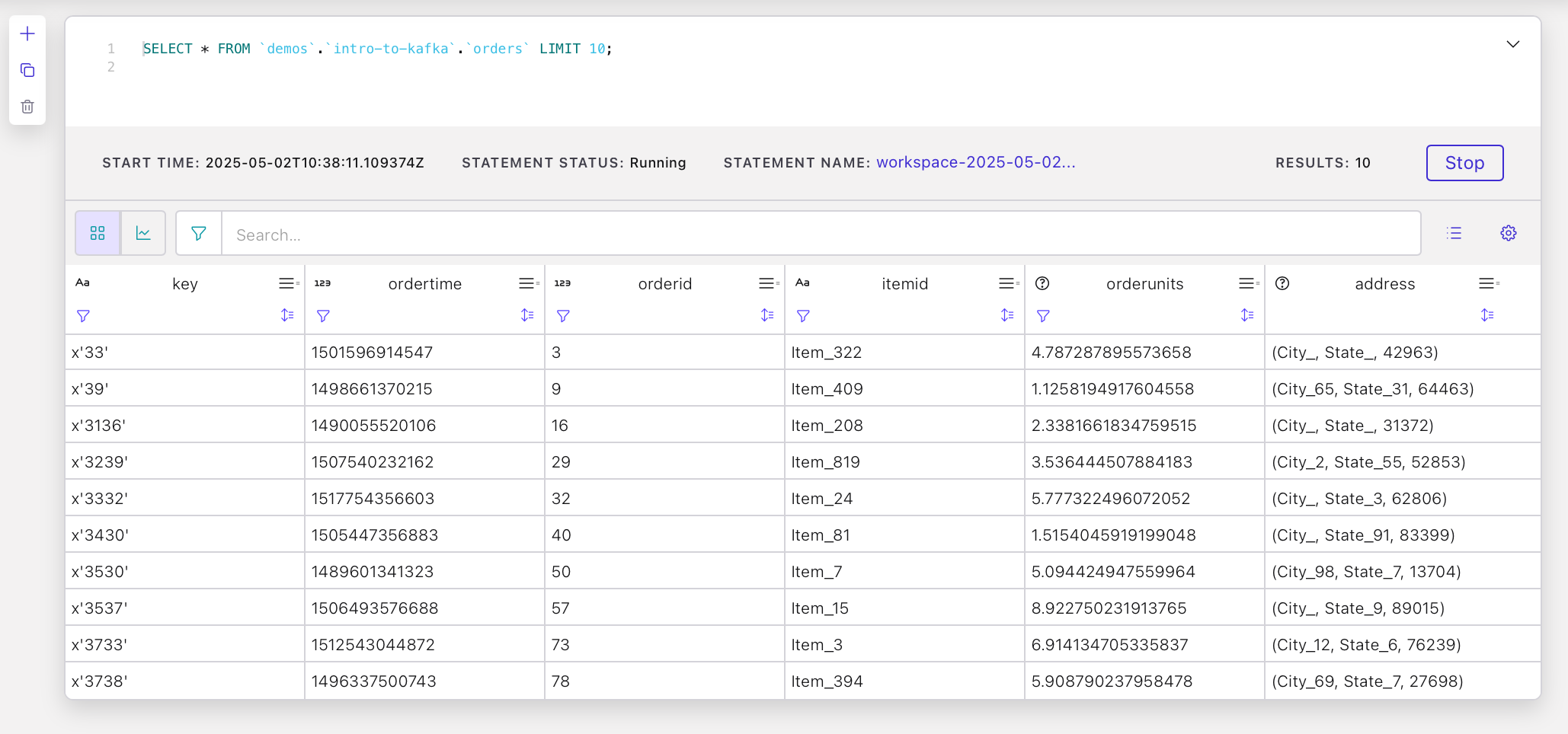
-
For this exercise, we want to apply a filter and see only the orders that sold more than 2 units:
SELECT address.state as state, orderunits FROM orders WHERE orderunits > 2;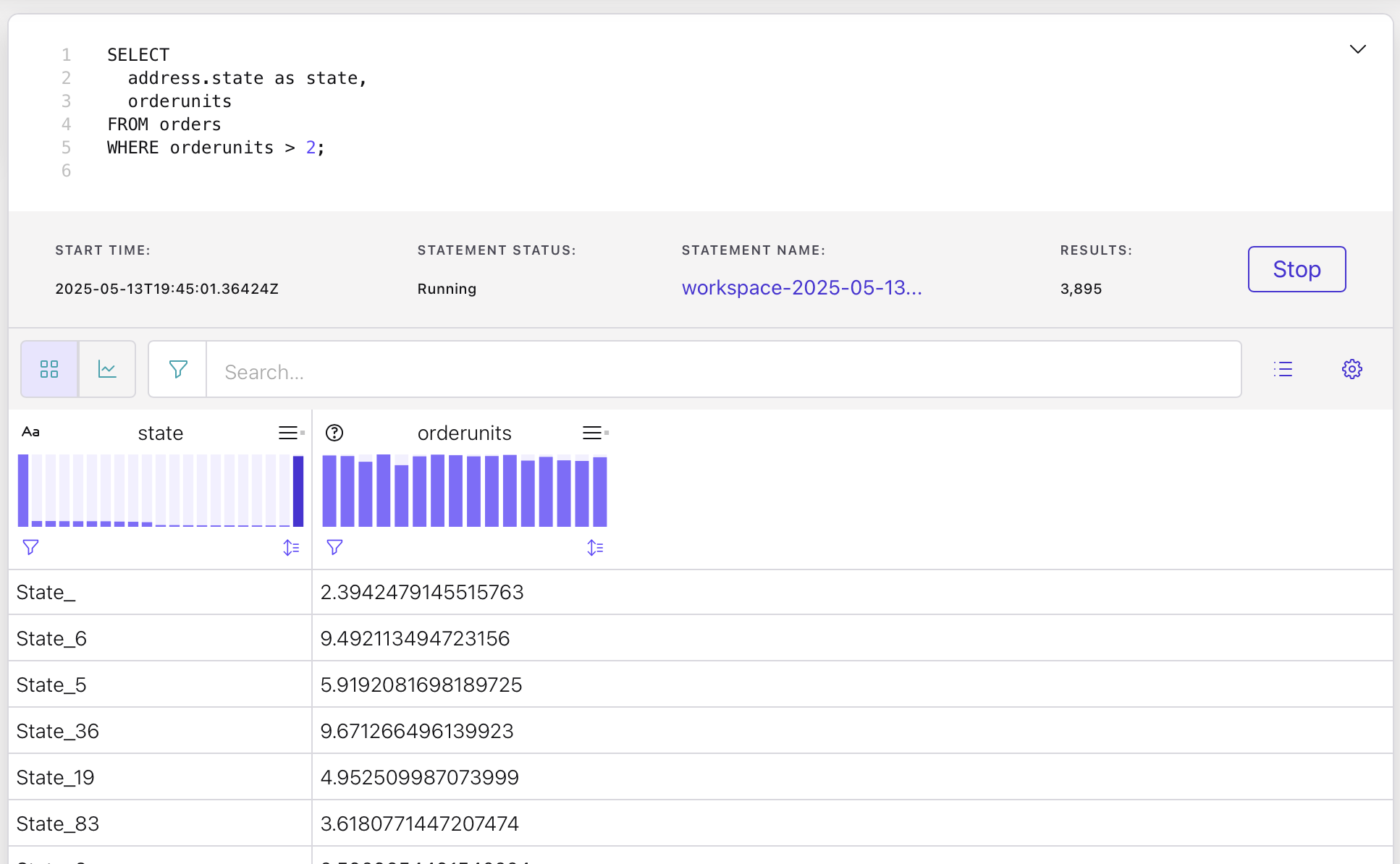
-
Did you notice the row counter in the top-right of your SQL cell? it keeps climbing because you’re running a continuous, never-ending streaming query. Although you’re now seeing the results you want, they exist only in this session: once you close the screen, the query will stop and the data will vanish. To make your filtering and projection permanent, wrap your statement in a CREATE TABLE ... AS clause. That way Confluent Cloud will create a persistent query that will feed a live materialized table, preserving your results even after you close the SQL workspace.
CREATE TABLE high_selling_orders AS SELECT address.state as state, orderunits FROM orders WHERE orderunits > 2; -
Let's now query the new Flink table:
SELECT * FROM high_selling_orders;
You should see exactly the same results as before, the difference is that you can now create new queries based on the high_selling_orders table.
-
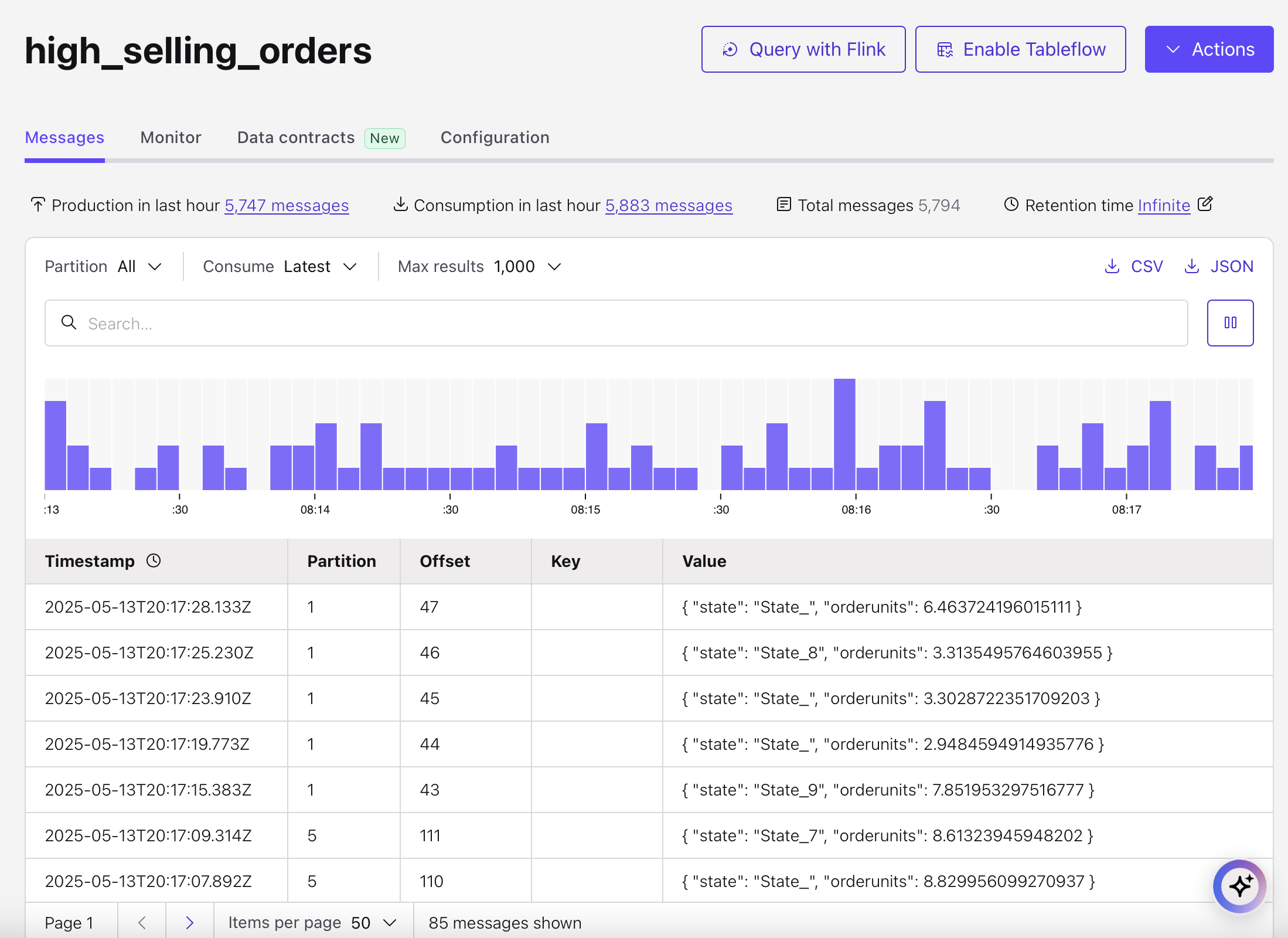
Confluent Cloud for Flink automatically creates a matching Kafka topic for each Flink table. If you navigate to the topics section, you'll notice a new high_selling_orders Kafka topic that you can use to build application or sink to a external datastore with Kafka Connect. The possibilities are endless!





Note
A final note to you as we wrap up the exercises for this course: Don’t forget to delete your resources and cluster in order to avoid exhausting the free Confluent Cloud usage that is provided to you. Delete the connectors, Flink workspace, and finally the cluster.
Flink SQL has much more to offer than we've covered here! If you're curious about the power of Flink, check out these courses:
Use the promo codes KAFKA101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud storage and skip credit card entry.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.