Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Hands On: Joining an Event Stream with a Table on Confluent Cloud



Michael Drogalis
Principal Product Manager (Presenter)
Hands On: Joining an Event Stream with a Table on Confluent Cloud
In this exercise, you will build and observe the behavior of a stream-table join in ksqlDB.
Before continuing, ensure that you have access to a Confluent Cloud cluster and a ksqlDB application within it. If you don’t, see below.
-
Go to Confluent Cloud and sign up for an account if you don't already have one. You can use the promo code KSQLDB101 for $25 of free usage (details). This will be enough to follow this exercise as written, but please make sure to delete your cluster and particularly your ksqlDB instance when you are finished so that you don't incur extra charges, as outlined below. You can also use the promo code CONFLUENTDEV1 to delay entering a credit card for 30 days.
-
Create a new cluster in Confluent Cloud. For the purposes of this exercise you can use the Basic type. Name the cluster inside-ksqldb.

-
Now go to the ksqlDB page within your Confluent Cloud cluster and click Add application.
If prompted, select Create application myself.
Leave the access control set to Global access. Give application name as inside-ksqldb, and leave the number of streaming units set to 4.
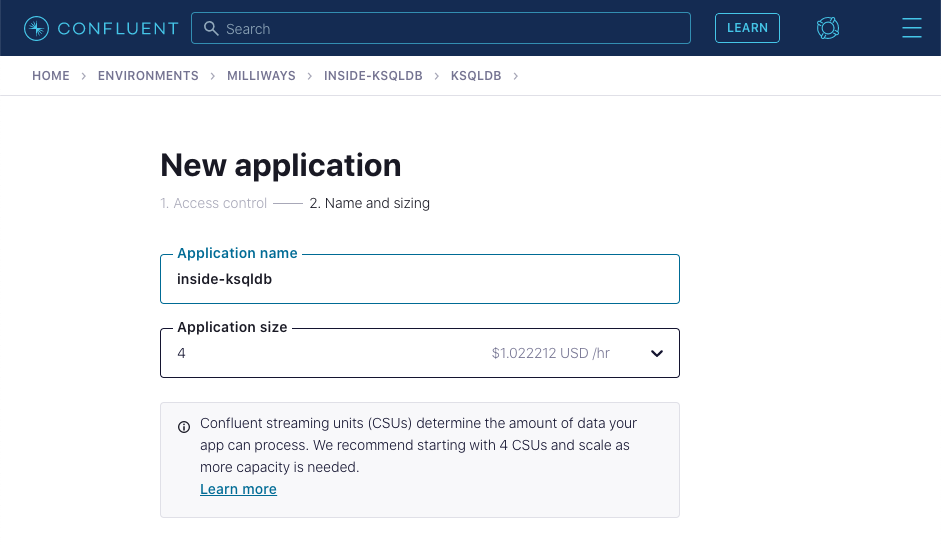
The ksqlDB application will take a few minutes to provision.
-
Navigate to the ksqlDB application.


Create the source objects
Run the following two ksqlDB statements in the ksqlDB editor and confirm that both complete successfully.

-
A stream of events holding data about readings received from a sensor:
CREATE STREAM readings ( sensor VARCHAR KEY, reading DOUBLE, area VARCHAR ) WITH ( kafka_topic='readings', value_format='json', partitions=3 ); -
A table holding information about the brand name of different sensors:
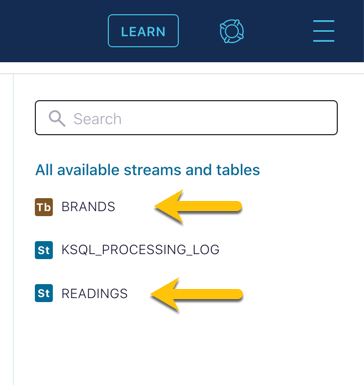
CREATE TABLE brands ( sensor VARCHAR PRIMARY KEY, brand_name VARCHAR ) WITH ( kafka_topic='brands', value_format='json', partitions=3 );On the right hand side of the ksqlDB editor you should see the new stream and table listed:

Populate the table
A table in ksqlDB is often populated using data streamed into a Kafka topic from another application or Kafka Connect. Tables can also be populated directly, using the INSERT INTO statement, which is what we’ll do here. Run the following statements in ksqlDB. You can run them individually or as multiple statements together.
INSERT INTO brands (sensor, brand_name) VALUES ('sensor-1','Cassin Inc');
INSERT INTO brands (sensor, brand_name) VALUES ('sensor-2','Carroll Ltd');
INSERT INTO brands (sensor, brand_name) VALUES ('sensor-3','Hirthe Inc');
INSERT INTO brands (sensor, brand_name) VALUES ('sensor-4','Walker LLC');You can check that the data has been written to the table by querying it. Make sure you have set auto.offset.reset to earliest using the drop down menu:
SELECT *
FROM brands
EMIT CHANGES;
Note that it can take around thirty seconds for the data to be returned to the screen. When it is, you can switch between how it is rendered using the icons to the top right of the data.

Populate the stream
Insert some events into the readings stream by running the following:
INSERT INTO readings (sensor, reading, area) VALUES ('sensor-1',45,'wheel');
INSERT INTO readings (sensor, reading, area) VALUES ('sensor-2',41,'motor');
INSERT INTO readings (sensor, reading, area) VALUES ('sensor-1',92,'wheel');
INSERT INTO readings (sensor, reading, area) VALUES ('sensor-2',13,'engine');Run the stream-table join query
Now you can run the stream-table join and see it in action.
Tell ksqlDB to processes all messages from the beginning of the stream by setting auto.offset.reset to earliest in the drop down menu:

SELECT r.reading,
r.area,
b.brand_name
FROM readings r
INNER JOIN brands b
ON b.sensor = r.sensor
EMIT CHANGES;Click on Run query. This executes the stream-table join, and you should shortly see the results of the join. Observe that for each reading the brand name of the sensor from which the reading was taken is included in the output, having been determined by a join to the brands table on the common sensor column.

Leave the query running and open a second browser window. In this new window go to the ksqlDB editor and insert some new rows into the readings stream.
INSERT INTO readings (sensor, reading, area) VALUES ('sensor-2',90,'engine');
INSERT INTO readings (sensor, reading, area) VALUES ('sensor-4',95,'motor');
INSERT INTO readings (sensor, reading, area) VALUES ('sensor-3',67,'engine');After a moment you should see the result of the stream-table join appear in the window in which you ran the SELECT statement:

Persist the enriched events to a new stream
In the query above the results of the join were output to the screen. ksqlDB can populate new streams with the results from a continuous query (such as the one we saw above). Let’s do that here.
As before, make sure you have set auto.offset.reset to earliest in the drop-down menu, and then run this query:
CREATE STREAM enriched_readings AS
SELECT r.reading,
r.area,
b.brand_name
FROM readings r
INNER JOIN brands b
ON b.sensor = r.sensor
PARTITION BY r.area
EMIT CHANGES;
With the stream created, you can query it:
SELECT *
FROM enriched_readings
EMIT CHANGES;
With another editor window insert some more events into the readings stream and observe how the events are written to enriched_readings with the brand details added.
INSERT INTO readings (sensor, reading, area) VALUES ('sensor-4',48,'motor');
INSERT INTO readings (sensor, reading, area) VALUES ('sensor-3',19,'engine');
INSERT INTO readings (sensor, reading, area) VALUES ('sensor-2',32,'engine');If you have access to the Data Lineage view on Confluent you can see a visual representation of what you’ve built:

Delete Your Cluster and ksqlDB Application
- Go to Cluster settings on the left-hand side menu, then click Delete cluster. Enter your cluster's name ("inside-ksqldb"), then select Continue.
- To delete your ksqlDB application, click ksqlDB on the left-hand side menu, then select Delete under Actions. Enter your application's name ("inside-ksqldb"), then click Continue.
Use the promo code KSQLDB101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Hands On: Joining an Event Stream with a Table on Confluent Cloud
In this exercise, we're going to join a stream of events with a table in ksqlDB. The stream is of readings from a car and the table is reference information about the sensor from which the readings are taken. We're going to start off by creating the table and stream objects. From your cluster's front page, navigate through to your ksqlDB application. In the ksqlDB editor, run the create stream command. The Kafka topic will be created by ksqlDB if it doesn't already exist. Make sure that the response from the statement running is success, as shown in the text underneath. Now, create the table to hold information about the brand for each sensor. Just like the stream, it's backed by a Kafka topic that is created if it doesn't exist. As before, make sure that it completes successfully. If you look on the right of the screen, you'll see that the brands and readings table and stream are shown there. With the objects created, we're now going to populate them. In practice, the data that ksqlDB processes will usually be written into the underlying Kafka topic by an external application using the producer API or by Kafka Connect or maybe the REST proxy. Here we're going to take advantage of the insert into syntax that ksqlDB supports to write some data directly into the table into the stream. Run these four insert into statements. You can run them as one execution. You won't get immediate feedback that the insert has succeeded, so let's query the table to make sure that the data's there. To query existing data in a stream or table and not just new data that arrives after the query starts, we need to set the auto offset.reset parameter to earliest. In the ksqlDB web UI, you do this with the dropdown menu. Now we're gonna select against the table. It might take a short while to return data. But when it does, you should see the four rows that you inserted. You can toggle between columnar and individual display of the records using the icons on the top right. Let's now write some events to the reading stream. As before, paste the insert into statements into the ksqlDB editor and click run query. If the query from the insert to the table is still running, then click stop first. When you click run query, the command will be executed and you'll see processing query appear briefly but you won't get any other indication that it's run. That's okay because we know that it has and we can verify this in the next step. Let's just double check that the data did get inserted into the stream by running a select on it. We'll make sure that the auto offset.reset parameter is set to earliest too. You can see that sure enough, the events are present on the stream. So now we're gonna go ahead and run the actual stream table join. Here we're using an inner join, although we have the option of using left outer joins instead if that's what we need to get from the data. The join is on the common key column called sensor. For every row on the source stream, the value of sensor is matched to the brand name from the brands table and if a match found, the brand name is returned with the readings data. We can now open a second browser window and use it to insert some events into the reading stream. They appear in the query output of the join since that's still running at the top of the screen. So far, we've just been writing the output of the join to the screen, which is useful for prototyping and refining a query. What we really wanna do though is to write this in rich data for all of the events already in the stream and every new one that arrives onto a new stream. For that, we can use the create stream as statement on the front of our existing SQL. As before, we'll make sure that the auto offset.reset parameter is set to earliest. Once the stream is successfully created, we can query it. The results are the same as we saw before when we ran the query join first. The difference this time is that the messages we see are coming from the enriched stream itself to which the join results have been written by ksqlDB. To show that the enriched stream that we're querying at the top is processing new events on the source too, we'll insert a new event in the second window at the bottom of the screen. As the event arrives on the source stream, it's written almost straightaway to the enriched stream and shown in the output at the top of the screen. One of the nice things that Confluent offers is the data lineage view. From here we can see how each topic relates to one another. This makes it easier to understand how your stream processing apps all connect to each other.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.