Enhance your career, get Certified as a Data Streaming Engineer | Get Certified
Introduction to Kafka Connect



Danica Fine
Senior Developer Advocate (Presenter)
Ingest Data from Upstream Systems
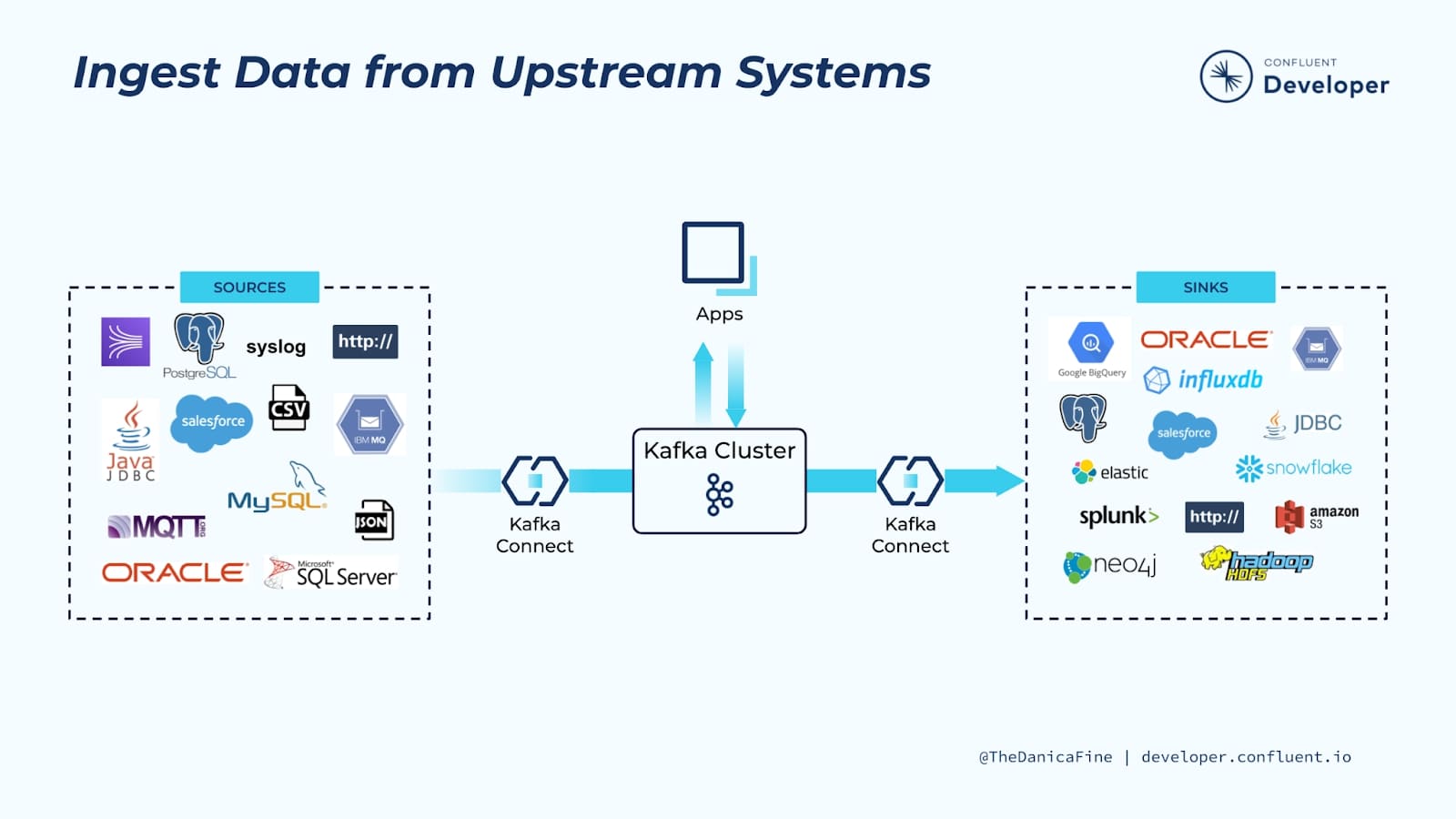
Kafka Connect is a component of Apache Kafka® that’s used to perform streaming integration between Kafka and other systems such as databases, cloud services, search indexes, file systems, and key-value stores.
If you’re new to Kafka, you may want to take a look at the Apache Kafka 101 course before you get started with this course.
Kafka Connect makes it easy to stream data from numerous sources into Kafka, and stream data out of Kafka to numerous targets. The diagram you see here shows a small sample of these sources and sinks (targets). There are literally hundreds of different connectors available for Kafka Connect. Some of the most popular ones include:
- RDBMS (Oracle, SQL Server, Db2, Postgres, MySQL)
- Cloud object stores (Amazon S3, Azure Blob Storage, Google Cloud Storage)
- Message queues (ActiveMQ, IBM MQ, RabbitMQ)
- NoSQL and document stores (Elasticsearch, MongoDB, Cassandra)
- Cloud data warehouses (Snowflake, Google BigQuery, Amazon Redshift)
Confluent Cloud Managed Connectors
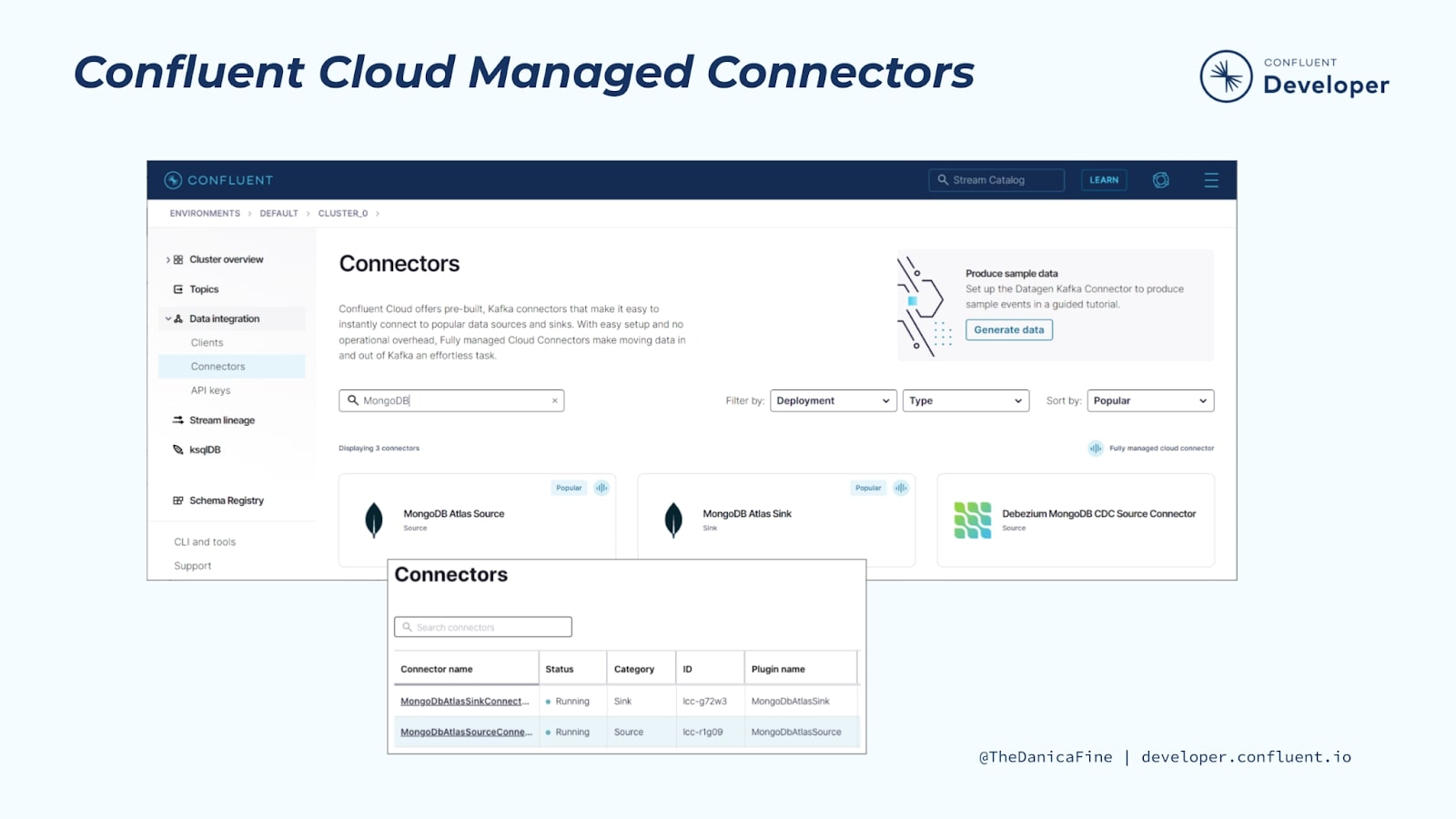
We’ll be focusing on running Kafka Connect more in the course modules that follow, but, for now, you should know that one of the cool features of Kafka Connect is that it’s flexible.
You can choose to run Kafka Connect yourself or take advantage of the numerous fully managed connectors provided in Confluent Cloud for a totally cloud-based integration solution. In addition to managed connectors, Confluent provides fully managed Apache Kafka, Schema Registry, and stream processing with ksqlDB.
How Kafka Connect Works
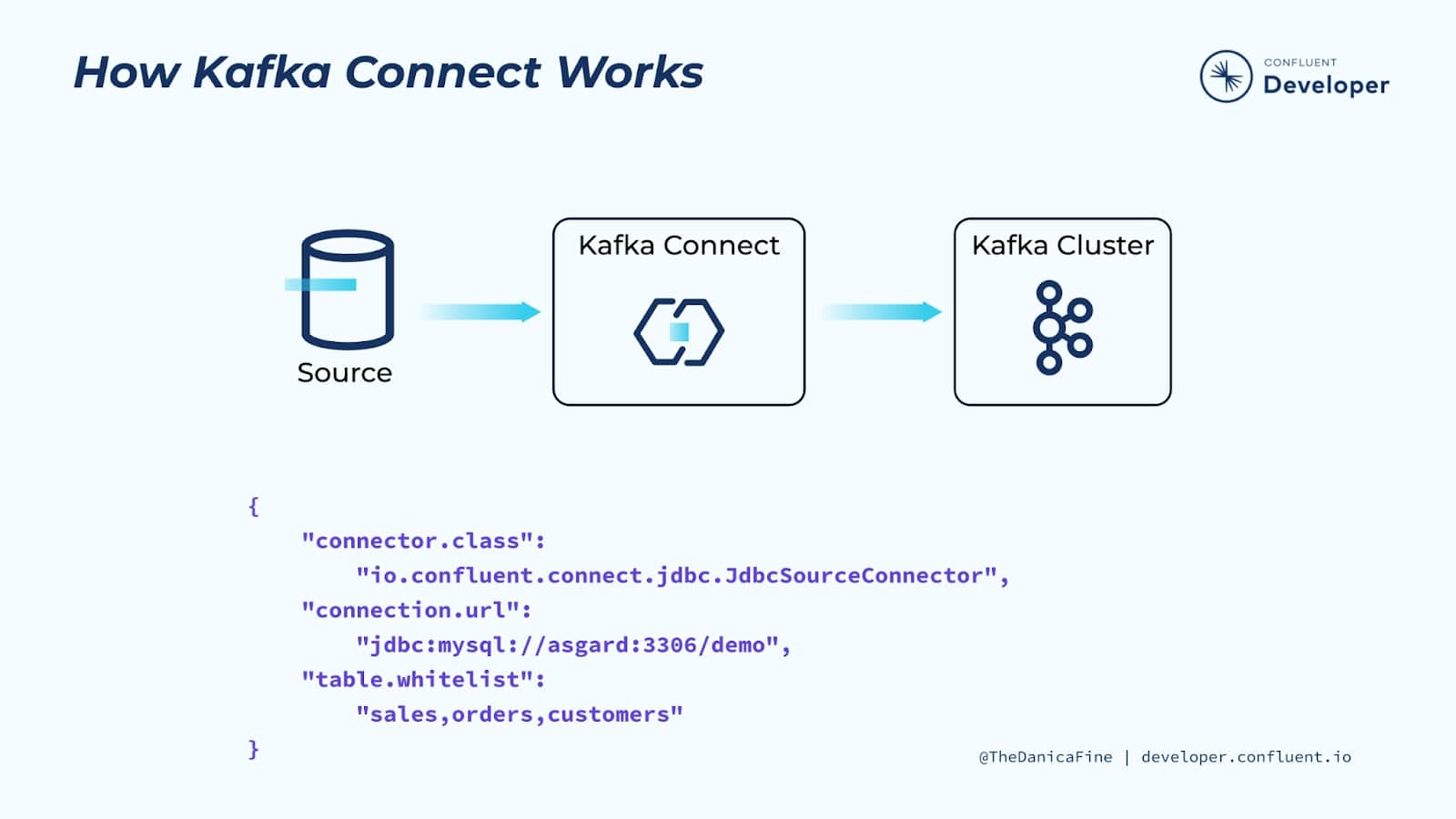
Kafka Connect runs in its own process, separate from the Kafka brokers. It is distributed, scalable, and fault tolerant, giving you the same features you know and love about Kafka itself.
But the best part of Kafka Connect is that using it requires no programming. It’s completely configuration-based, making it available to a wide range of users—not just developers. In addition to ingest and egress of data, Kafka Connect can also perform lightweight transformations on the data as it passes through.
Anytime you are looking to stream data into Kafka from another system, or stream data from Kafka to elsewhere, Kafka Connect should be the first thing that comes to mind. Let’s take a look at a few common use cases where Kafka Connect is used.
Streaming Pipelines
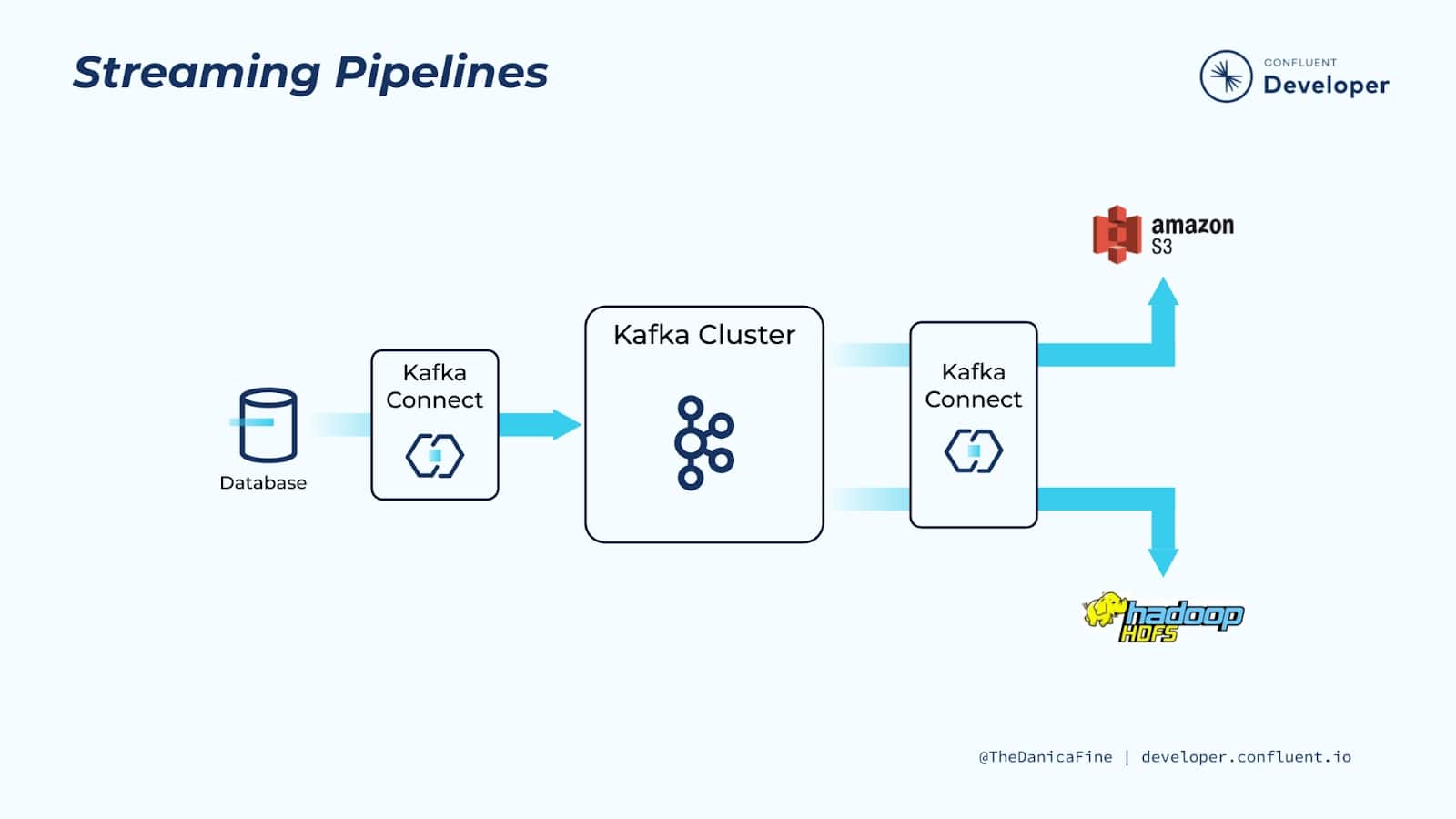
Kafka Connect can be used to ingest real-time streams of events from a data source and stream them to a target system for analytics. In this particular example, our data source is a transactional database.
We have a Kafka connector polling the database for updates and translating the information into real-time events that it produces to Kafka.
That in and of itself is great, but there are several other useful things that we get by adding Kafka to the mix:
- First of all, having Kafka sits between the source and target systems means that we’re building a loosely coupled system. In other words, it’s relatively easy for us to change the source or target without impacting the other.
- Additionally, Kafka acts as a buffer for the data, applying back pressure as needed.
- And also, since we’re using Kafka, we know that the system as a whole is scalable and fault tolerant.
Because Kafka stores data up to a configurable time interval per data entity (topic), it’s possible to stream the same original data to multiple downstream targets. This means that you only need to move data into Kafka once while allowing it to be consumed by a number of different downstream technologies for a variety of business requirements or even to make the same data available to different areas of a business.
Writing to Datastores from Kafka
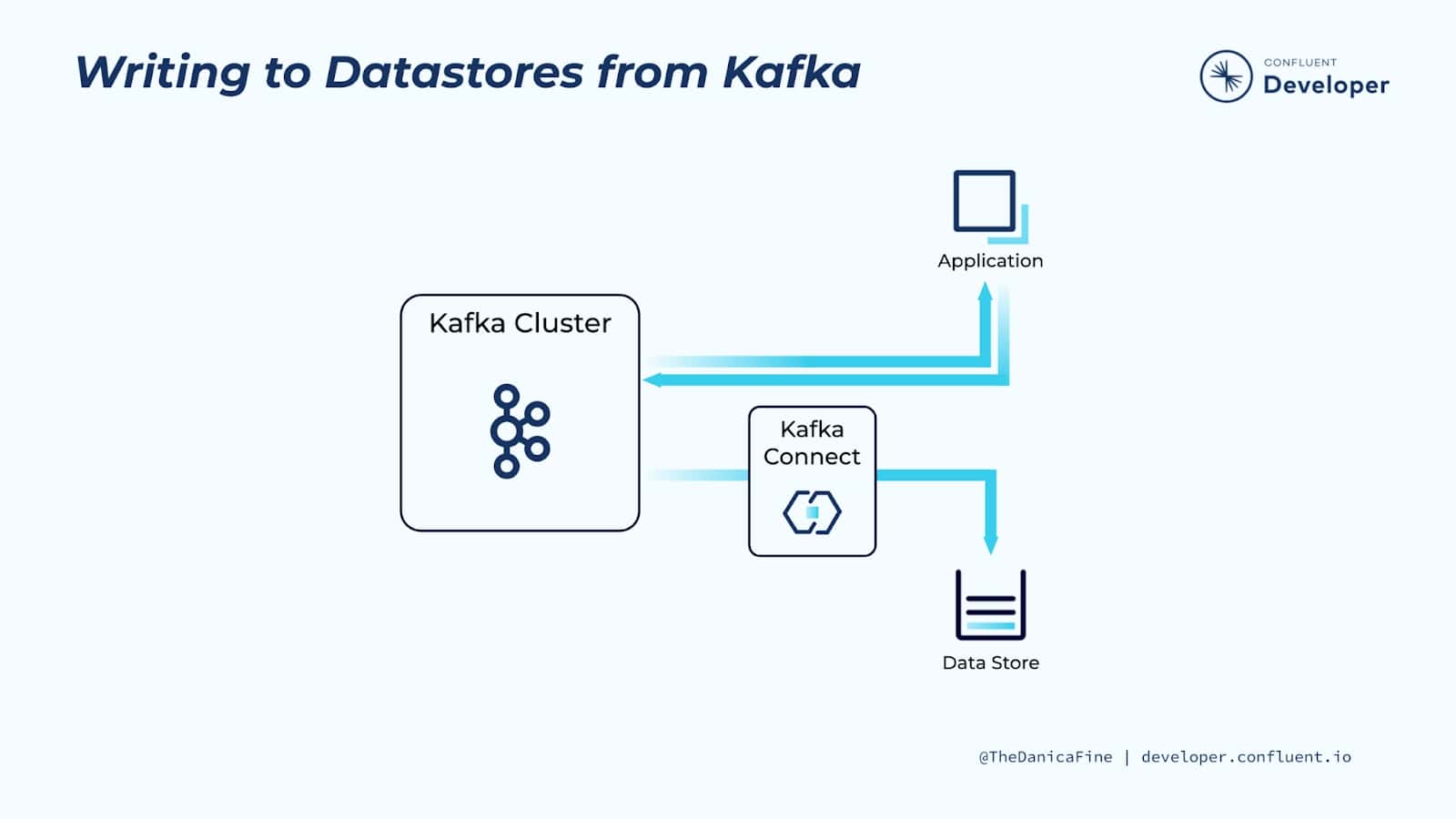
As another use case, you may want to write data created by an application to a target system. This of course could be a number of different application use cases, but suppose that we have an application producing a series of logging events, and we’d like those events to also be written to a document store or persisted to a relational database.
Imagine that you added this logic to your application directly. You’d have to write a decent amount of boilerplate code to make this happen, and whatever code you do add to your application to achieve this will have nothing to do with the application’s business logic. Plus, you’d have to maintain this extra code, determine how to scale it along with your application, how to handle failures, restarts, etc.
Instead, you could add a few simple lines of code to produce the data straight to Kafka and allow Kafka Connect to handle the rest. As we saw in the last example, by moving the data to Kafka, we’re free to set up Kafka connectors to move the data to whatever downstream datastore that we need, and it’s fully decoupled from the application itself.
Evolve Processing from Old Systems to New
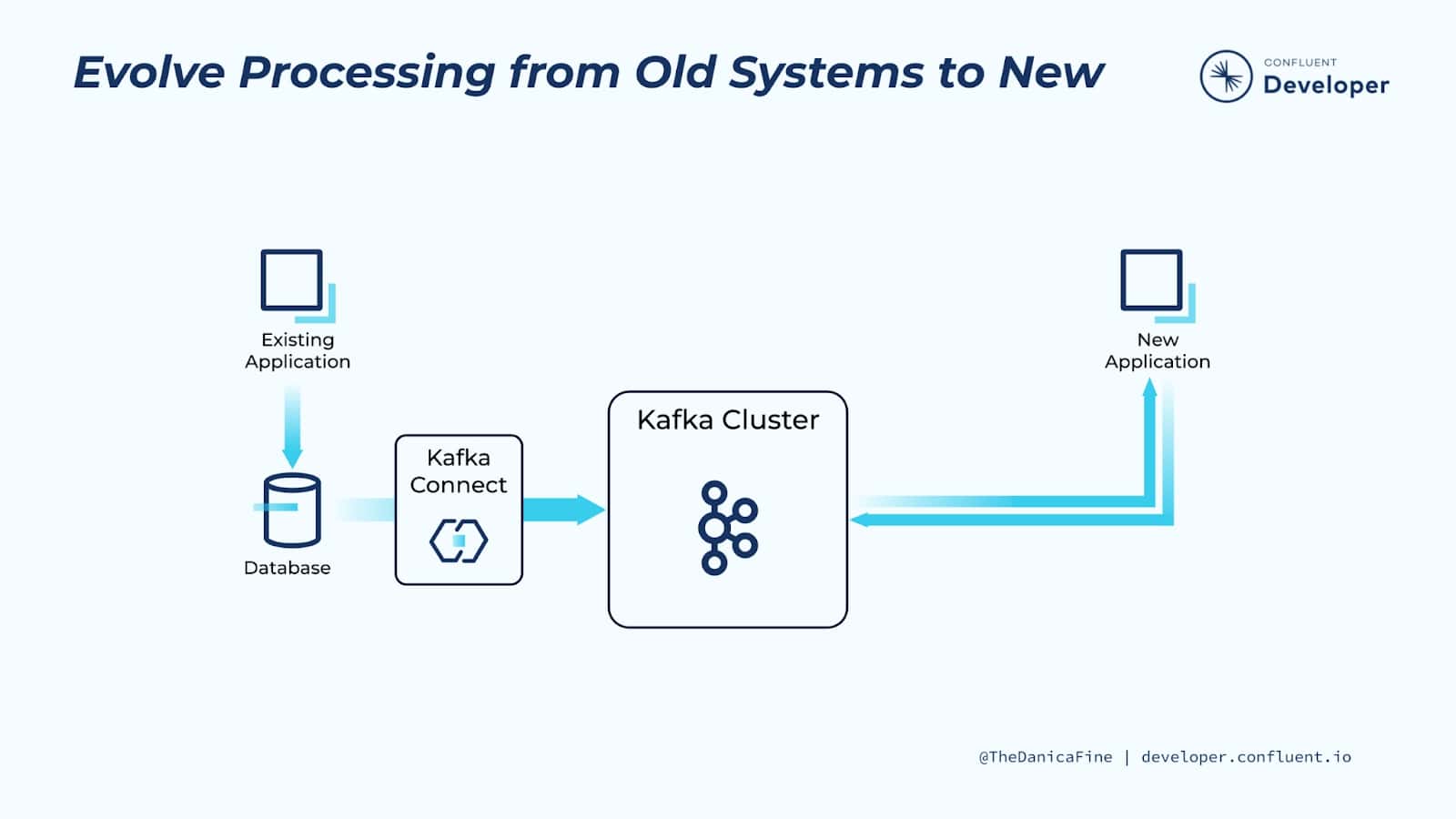
Before the advent of more recent technologies (such as NoSQL stores, event streaming platforms, and microservices) relational databases (RDBMS) were the de facto place to which all application data was written. These datastores still have a hugely important role to play in the systems that we build—but… not always. Sometimes we will want to use Kafka to serve as the message broker between independent services as well as the permanent system of record. These two approaches are very different, but unlike technology changes in the past, there is a seamless route between the two.
By utilizing change data capture (CDC), it’s possible to extract every INSERT, UPDATE, and even DELETE from a database into a stream of events in Kafka. And we can do this in near-real time. Using underlying database transaction logs and lightweight queries, CDC has a very low impact on the source database, meaning that the existing application can continue to run without any changes, all the while new applications can be built, driven by the stream of events captured from the underlying database. When the original application records something in the database—for example, an order is accepted—any application subscribed to the stream of events in Kafka will be able to take an action based on the events—for example, a new order fulfillment service.
For more information, see Kafka data ingestion with CDC.
Make Systems Real Time
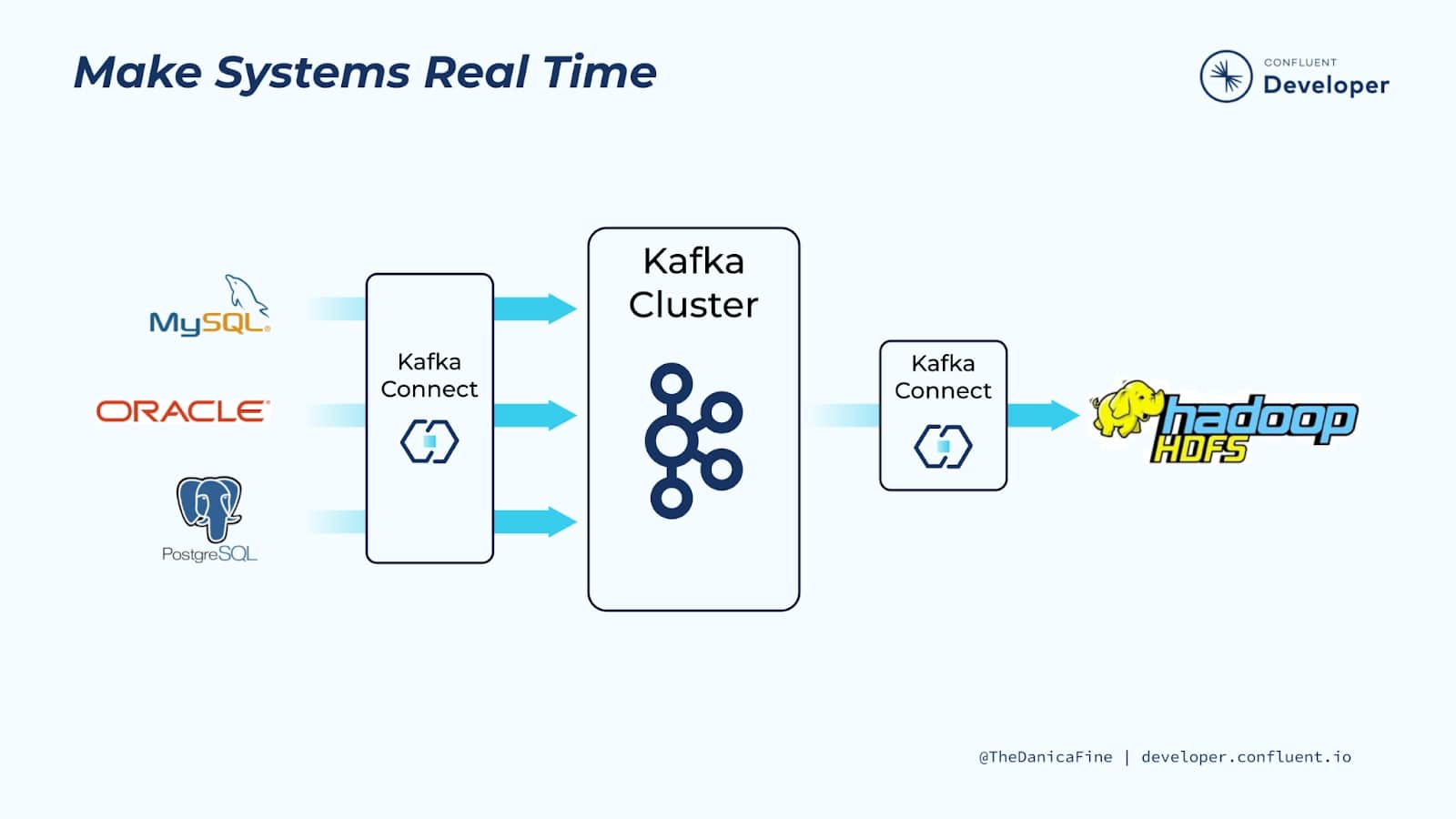
Making systems real time is incredibly valuable because many organizations have data at rest in databases and they’ll continue to do so!
But the real value of data lies in our ability to access it as close to when it is generated as possible. By using Kafka Connect to capture data soon after it’s written to a database and translating it into a stream of events, you can create so much more value. Doing so unlocks the data so you can move it elsewhere, for example, adding it to a search index or analytics cluster. Alternatively, the event stream can be used to trigger applications as the data in the database changes, say to recalculate an account balance or make a recommendation.
Why Not Write Your Own Integrations?
All of this sounds great, but you’re probably asking, “Why Kafka Connect? Why not write our own integrations?”
Apache Kafka has its own very capable producer and consumer APIs and client libraries available in many languages, including C/C++, Java, Python, and Go. So it makes sense for you to wonder why you wouldn’t just write your own code to move data from a system and write it to Kafka—doesn’t it make sense to write a quick bit of consumer code to read from a topic and push it to a target system?
The problem is that if you are going to do this properly, then you need to be able to account for and handle failures, restarts, logging, scaling out and back down again elastically, and also running across multiple nodes. And that’s all before you’ve thought about serialization and data formats. Of course, once you’ve done all of these things, you’ve written something that is probably similar to Kafka Connect, but without the many years of development, testing, production validation, and community that exists around Kafka Connect. Even if you have built a better mousetrap, is all the time that you’ve spent writing that code to solve this problem worth it? Would your effort result in something that significantly differentiates your business from anyone else doing similar integration?
The bottom line is that integrating external data systems with Kafka is a solved problem. There may be a few edge cases where a bespoke solution is appropriate, but by and large, you’ll find that Kafka Connect will become the first thing you think of when you need to integrate a data system with Kafka.
Start Kafka in Minutes with Confluent Cloud
Throughout this course, we’ll introduce you to Kafka Connect through hands-on exercises that will have you produce data to and consume data from Confluent Cloud. If you haven’t already signed up for Confluent Cloud, sign up now so when your first exercise asks you to log in, you are ready to do so.
- Browse to the sign-up page: https://www.confluent.io/confluent-cloud/tryfree/ and fill in your contact information and a password. Then click the Start Free button and wait for a verification email.
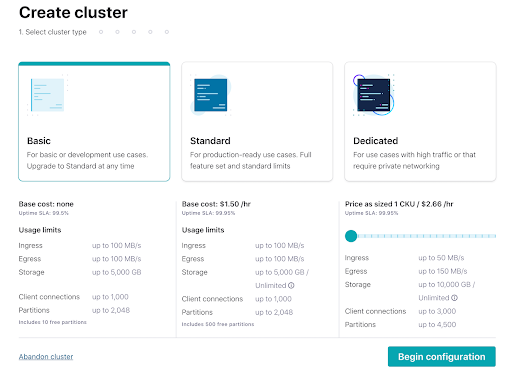
- Click the link in the confirmation email and then follow the prompts (or skip) until you get to the Create cluster page. Here you can see the different types of clusters that are available, along with their costs. For this course, the Basic cluster will be sufficient and will maximize your free usage credits. After selecting Basic, click the Begin configuration button.
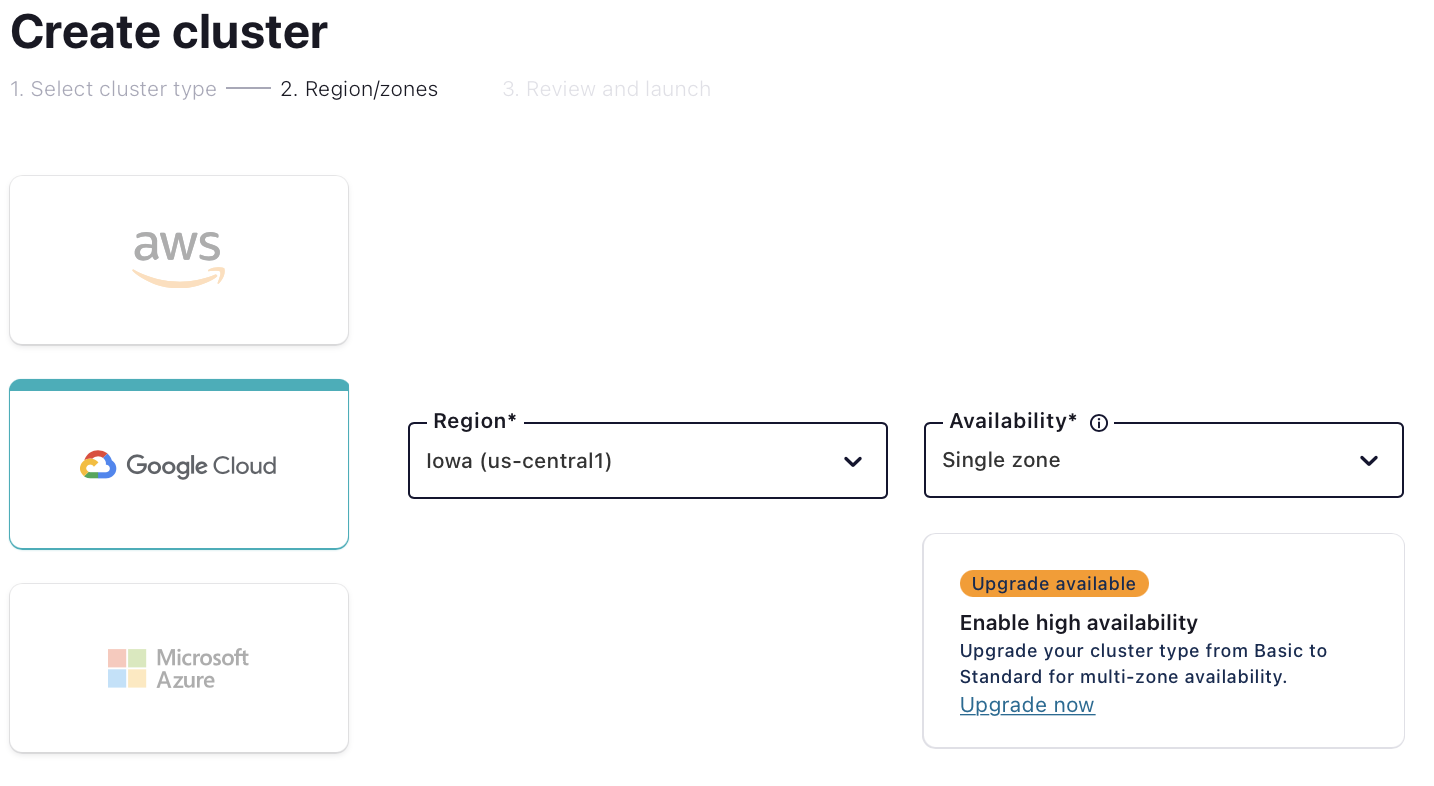
- Choose your preferred cloud provider and region, and click Continue.
-
Review your selections and give your cluster a name, then click Launch cluster. This might take a few minutes.
-
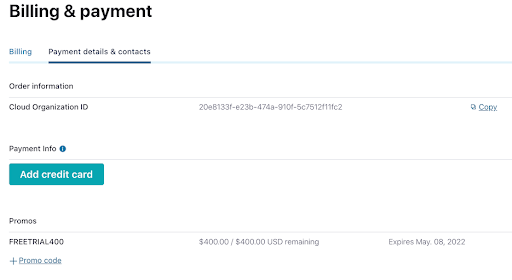
While you’re waiting for your cluster to be provisioned, be sure to add the promo code 101CONNECT to get an additional $25 of free usage (details). From the menu in the top right corner, choose Administration | Billing & Payments, then click on the Payment details tab. From there click on the +Promo code link, and enter the code.
You’re now ready to complete the upcoming exercises as well as take advantage of all that Confluent Cloud has to offer!
- Previous
- Next
Use the promo code 101CONNECT & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Introduction to Kafka Connect
Hi, I'm Danica Fine with Confluent. And today, I'm gonna tell you a little bit about Kafka Connect. Kafka Connect is a component of Apache Kafka that's used to perform streaming integration between Kafka and other systems, such as databases, cloud services, search indices, file systems, and key value stores. And before we dive more into this subject, if you're new to Apache Kafka, I highly recommend that you take a look at the Apache Kafka 101 course, and do this to familiarize yourself so that you can really hit the ground running with this material. Ingest Data from Upstream Systems Kafka Connect makes it easy to stream data from numerous sources into Kafka and stream data out of Kafka to numerous targets. The diagram you see here shows a small sample of these sources and targets. There are literally hundreds of different connectors available for Kafka Connect. Some of the most popular ones include relational databases, cloud object stores, message queues, NoSQL and document stores, and of course cloud data warehouses. We'll be focusing on running Kafka Connect more in the course modules that follow. But for now, you should know that one of the really cool features of Kafka Connect is that it's flexible. Confluent Cloud Managed Connectors You can choose to run Kafka Connect yourself or take advantage of the numerous fully-managed connectors provided in Confluent Cloud for a fully cloud-based integration solution. In addition to managed connectors, Confluent also provides fully-managed Apache Kafka, schema registry, and of course stream processing with KSQL. How Kafka Connect Works Kafka Connect runs in its own process, separate from the Kafka brokers. It's distributed, scalable, and fault tolerant, giving you the same features we know and love about Kafka itself. But the best part of Kafka Connect is that using it requires no programming. It's completely configuration-based, making it available to a wide range of users, not just developers. In addition to ingest and egress of data, Kafka Connect can also perform lightweight transformations on the data as it passes through. So anytime you're looking to stream data into Kafka from another system or stream data from Kafka elsewhere, Kafka Connect should be the first thing that comes to mind. Let's take a look at a few common use cases where Kafka Connect is used. Streaming Pipelines Kafka Connect can be used to ingest real time streams of events from data source and stream it to a target system for analytics. In this particular example, our data source is a transactional database. We have a Kafka Connector pulling the database for updates, and then translating that information into real time events that it then produces to Kafka. Now that in and of itself is great, but there are several other useful things that we can get by adding Kafka into the mix. First of all, having Kafka sit between the source and target systems means that we're building a loosely coupled system. In other words, it's relatively easy for us to change the source or the target without impacting the other. Additionally, Kafka acts as a buffer for the data, applying back pressure as needed. And also since we're using Kafka, we know that the system as a whole is scalable and fault tolerant. Because Kafka stores data up to a configurable time interval per data entity or Kafka topic, it's possible to stream the same original data to multiple downstream targets. So this means that you only need to move data into Kafka once, while allowing it to be consumed by a number of different downstream technologies for a variety of business requirements or even to make the same data available to different areas in the business. As another use case, you may want to write data created by an application to a target system. This of course could be a number of different application use cases, but suppose that we have an application producing a series of logging events, and we would like those events to also be written to a document store or even persisted to a relational database. Writing to Datastores from Kafka Imagine that you added this logic to your application directly, you'd have to write a decent amount of boiler plate code to make this happen. And whatever code you do add to your application to achieve this will have nothing to do with the application's business logic. Plus, you'd have to maintain this extra code, determine how to scale it along with your application, how to handle failures, restarts, and more. Now, instead of doing that, you could add a few simple lines of code to produce the data straight to Kafka and allow Kafka Connect to handle the rest. As we saw in the last example, by moving the data to Kafka, we're free to set up Kafka Connectors to move the data to whatever downstream data store that we need. And it's fully decoupled from the application itself. Before the advent of more recent technologies like NoSQL stores events-driven platforms and microservices, relational databases were the defacto place to which all application data was written. Evolve Processing from Old Systems to New These data stores still have a hugely important role to play in the systems that we build, but not always. Sometimes we'll want to use Kafka to serve as the message broker between independent services, as well as the permanent system of record. These two approaches are very different. But unlike technology changes in the past, there is a seamless route between the two of them. By utilizing change data capture, it's possible to extract every insert, update, and even delete from a database, and move that into a stream of events in Kafka. And we can do this in near real time. Using the underlying database transaction logs and lightweight queries, CDC has a very low impact on the source database, meaning that the existing application can continue running without any changes. All the while, new applications can be built driven by the stream of events captured from the underlying database. When the original application records something in the database, for example, say an order is accepted, any application subscribed to the stream of events in Kafka will be able to take in action based on those events. So for example, a new order fulfillment service. And this is an incredibly valuable thing because many organizations have data at rest in databases and they'll continue to do so. But the real value of data lies in our ability to access it Make Systems Real Time as close to when it's generated as possible. By using Kafka Connect to capture data soon after it's written to a database and then translating it into a stream of events, you can create so much more value. And doing so unlocks the data, so that you can move it elsewhere. For example, adding a search index or analytics cluster. Alternatively, the event stream can be used to trigger applications as the data in the database changes, say to recalculate an account balance or even make a recommendation. Now, all of this sounds great, But I'm sure you're asking, why Kafka Connect? Why not write our own integrations? Why Not Write Your Own Integrations? Apache Kafka has its own very capable producer in consumer APIs and client libraries available in many languages, including C, C++, Java, Python, and Go. So it makes sense for you to wonder why you wouldn't just write your own code to move data from a system and write it to Kafka. Doesn't it make sense to write a quick bit of consumer code to read from a topic and push it to a target system? The problem is that if you're going to do this properly, then you need to be able to account for and handle failures, restarts, logging, scaling out and back down again elastically, and also running across multiple nodes. And that's all before we've thought about serialization and data formats. Of course, once you've done all these things, you've written something that's probably pretty like Kafka Connect, but without the many years of development testing, product validation, and community that exists around Kafka Connect. So even if you have built a better mouse trap, is all the time that you've spent writing that code to solve this problem worth it? Would your effort result in something that significantly differentiates your business from anyone else doing something similar? The bottom line is that integrating external systems with Kafka is a solved problem. There may be a few edge cases where a bespoke solution is appropriate, but by and large, you'll find that Kafka Connect will become the first thing you think of when you need to integrate a data system with Kafka. Throughout this course, we'll be introducing you to Kafka Connect through hands-on exercises that will have you produce data to and consume data from Confluent Cloud. If you haven't already signed up for Confluent Cloud, sign up now so that when the first exercise asks you to log in, you're already ready to do so. Be sure to use the promo code when signing up. First off, you'll want to follow the URL on the screen. On the signup page, enter your name, email, and password. Be sure to remember these sign in details as you'll need them to access your account later. Click the Start free button and wait to receive a confirmation email in your inbox. The link in the confirmation email will lead you to the next step where you'll be prompted to set up your cluster. You can choose between a Basic, Standard, or Dedicated cluster. Basic and Standard clusters are serverless offerings where your free Confluent cloud usage is only exhausted based on what you use, perfect for what we need today. For the exercises in this course, we'll choose the Basic cluster. Usage costs will vary with any of these choices, but they are clearly shown at the bottom of the screen. That being said, once we wrap up these exercises, don't forget to stop and delete any resources that you created to avoid exhausting your free usage. Click review to get one last look at the choices you've made and give your cluster a name, then launch. It may take a few minutes for your cluster to be provisioned, and that's it. You'll receive an email once your cluster is fully provisioned. But in the meantime, let's go ahead and leverage that promo code from settings, choose Billing & payment. You'll see here that you have $400 of free Confluent Cloud usage. But if you select the Payment details & context tab, you can either add a credit card or choose to enter a promo code. And with that done, you're ready to dive in. And with that, you should not only have a pretty high level understanding of Kafka Connect, but you're ready to hit the ground running with the rest of the course modules. See you there.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.