Hands-on Exercise: Confluent Schema Registry

Gilles Philippart
Software Practice Lead
Hands On: Manage Schemas in Kafka with Avro
In this hands-on exercise, we are going to set up a source connector in Apache Kafka® using Avro to write and serialize data, and leveraging Schema Registry to manage our schemas.
The good news is that a Schema Registry is automatically provisioned in each Confluent Cloud environment.
We just need to create an API key and secret to use it via the Confluent CLI or from within a streaming application.
-
Go to your Confluent Cloud home page, select the "Environments" icons on the left, and choose your environment.
-
Click on the "Schema Registry" menu.
-
Click the "API keys" link on the right hand side.
-
On the API screen, press the "Add API key" button on the top right corner. Store this API key and secret for use in a later step.

-
Navigate to the cluster overview page. Then, click on "Connectors" in the menu.
-
If you have no connectors, you'll be taken directly to the connector search page—skip to step 7. Otherwise, select "Add connector" to access the search page.
-
On the connector search page, search for "Datagen" and select the "Datagen Source" connector.
-
Pick the "Orders" option and click on "Additional configuration".
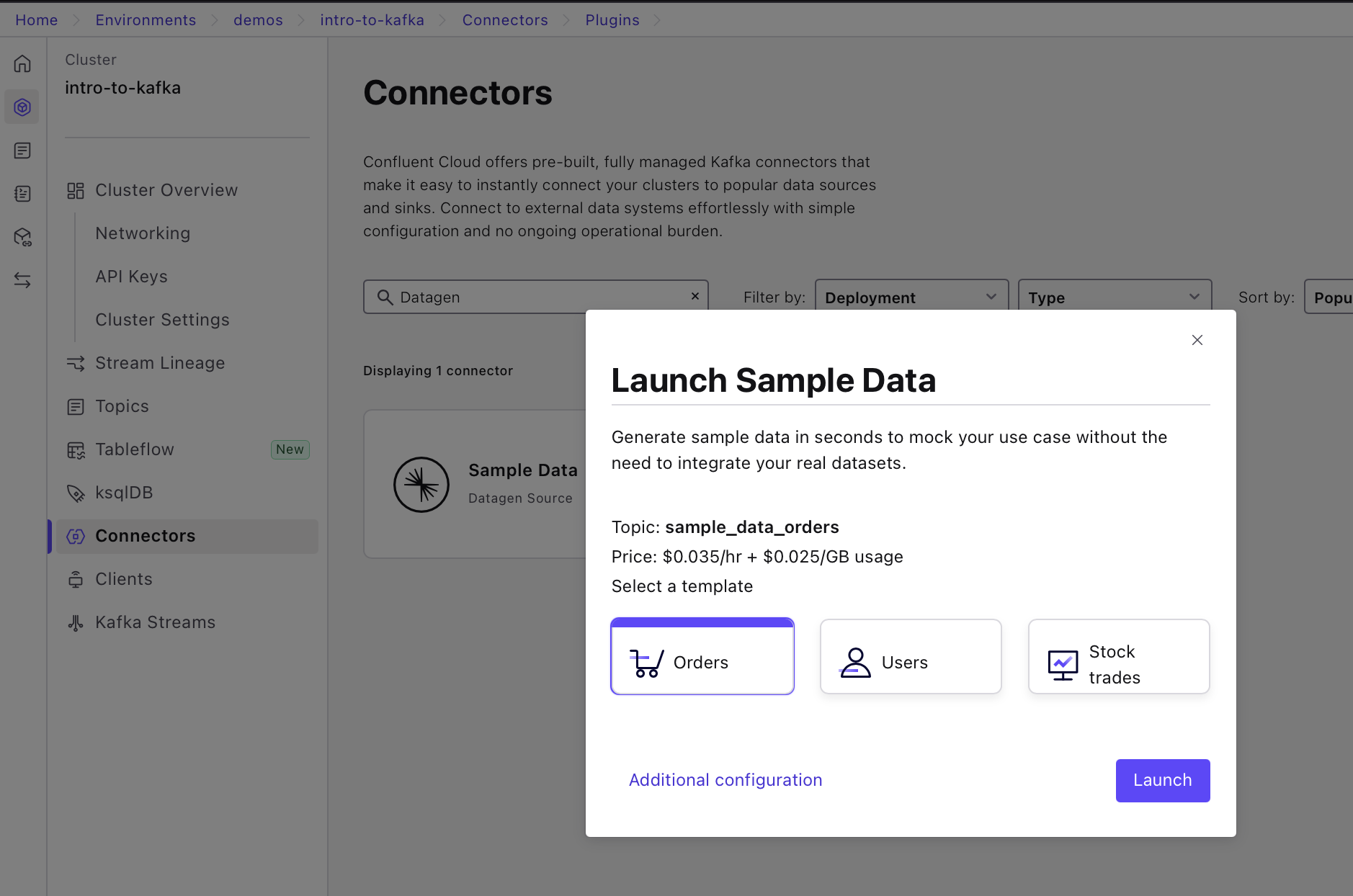
-
Select "Add a new topic", name it orders, and click "Create with defaults".
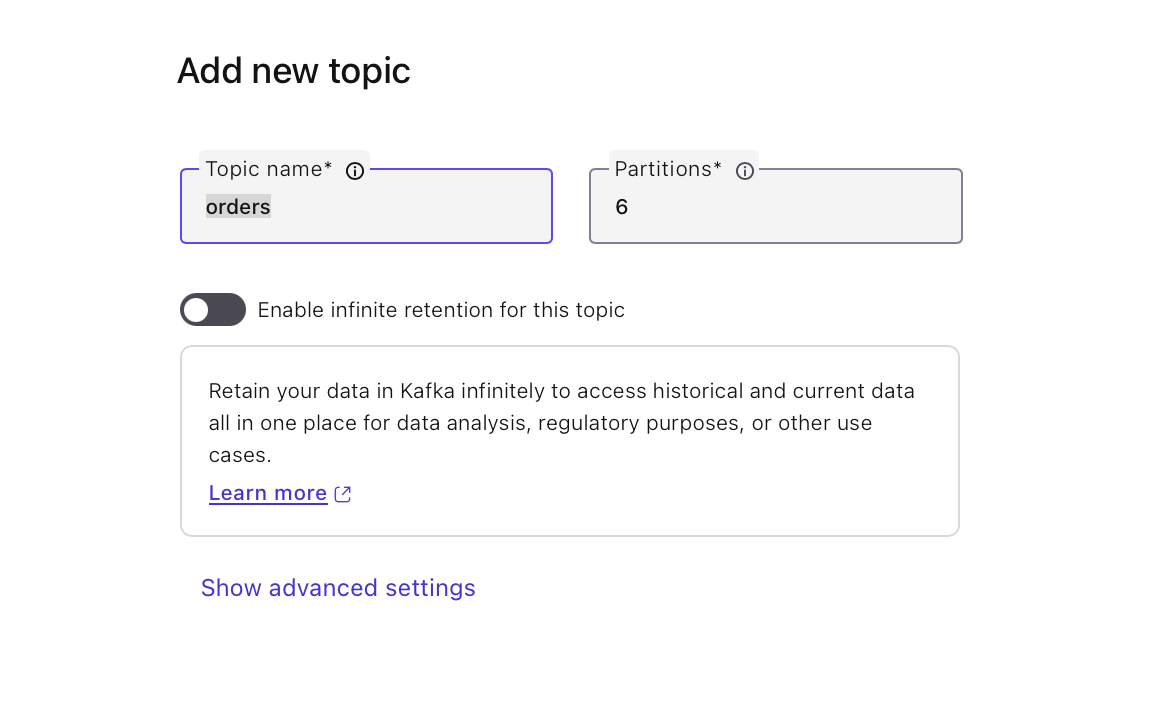
-
Refresh the page if needed, select the new orders topic and click "Continue".
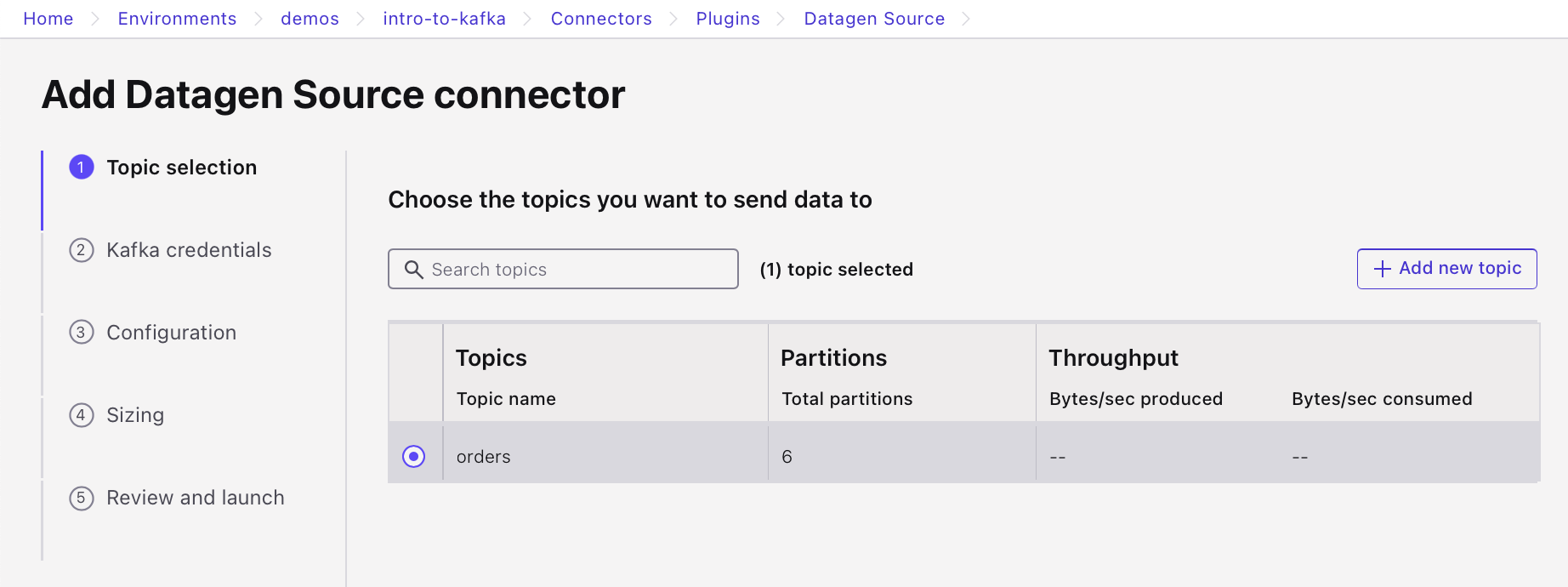
-
Create a new API key for the connector to communicate with the Kafka cluster.
 . Select "My account" and "Generate API key & Download". Click "Continue".
. Select "My account" and "Generate API key & Download". Click "Continue". -
The Datagen Source Connector can auto-generate several predefined datasets. Set the output record value format to AVRO and select the "Orders" schema.
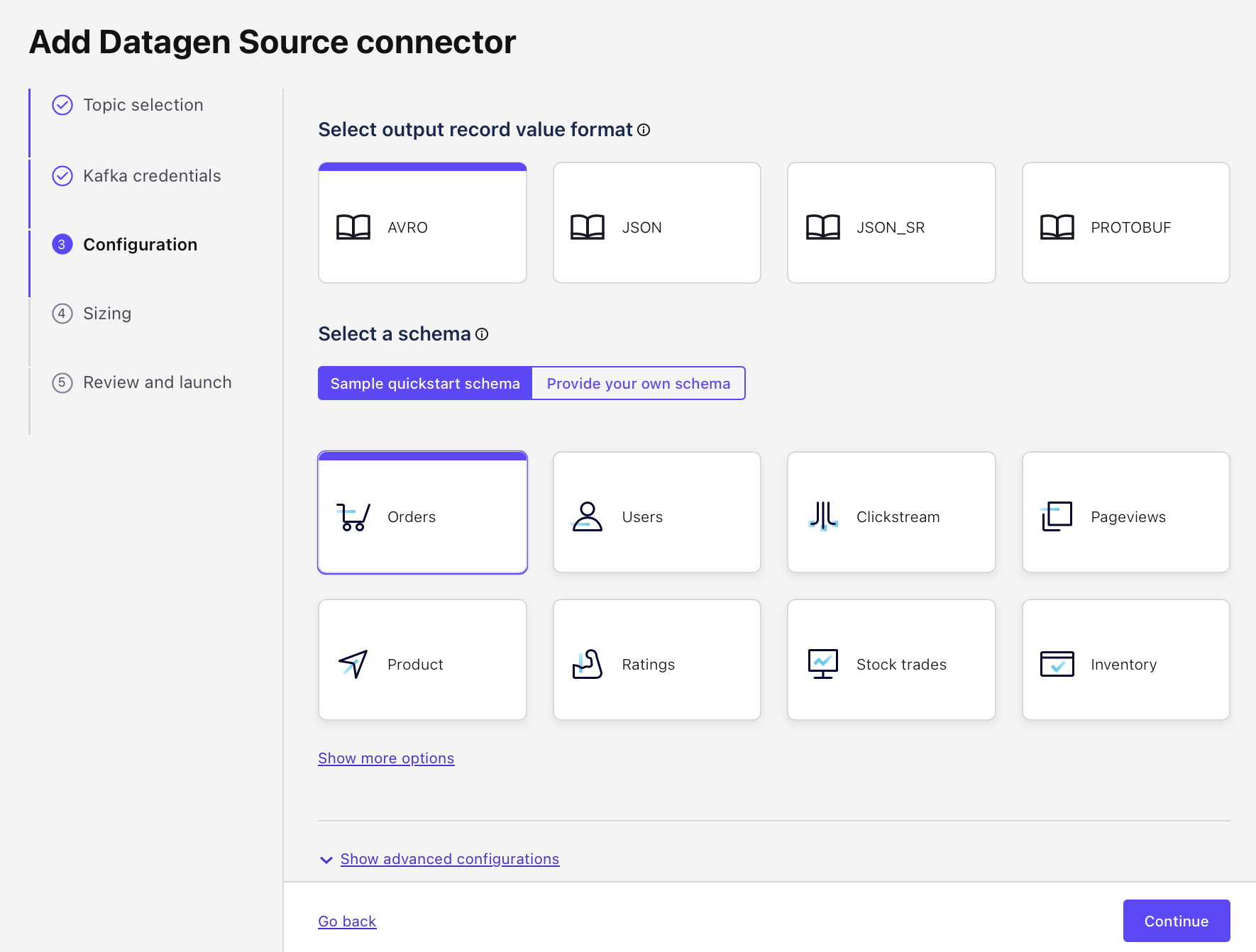
-
Click Continue to review the cost of the connector.
-
Give the connector a meaningful name such as "OrdersGenerator", review the configuration, and click Continue.
-
It may take a few minutes for the connector to be provisioned.
-
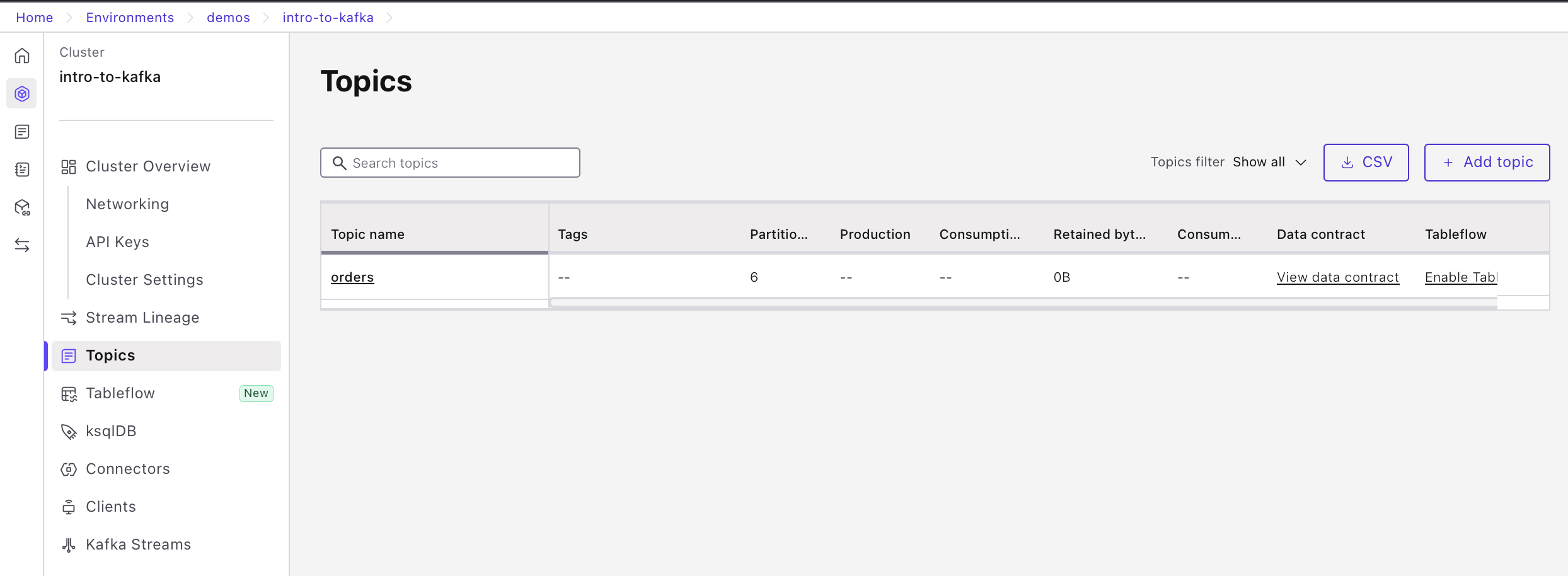
Once the connector is running, go to the topic list, locate the orders topic and click the "View Data Contract" link in the "Data contract" column.










- Inspect the schema for the order value.

-
From a terminal window, consume messages from the orders topic. If you’re curious, start with the same consume command as in the previous exercise.
confluent kafka topic consume --from-beginning ordersYou might notice that the output appears as gibberish with a few recognizable strings. That’s because the data is serialized using Avro. Without deserialization, it’s read as plain text, which results in unreadable output.
-
To properly read the data, tell the consumer to fetch the Avro schema from Schema Registry and deserialize the data:
confluent kafka topic consume --value-format avro --schema-registry-api-key {API Key} --schema-registry-api-secret {API Secret} ordersYou’ll see the deserialized data being output.
Starting Kafka Consumer. Use Ctrl-C to exit. %6|1746023777.371|GETSUBSCRIPTIONS|Confluent-CLI_v4.26.0#consumer-1| [thrd:main]: Telemetry client instance id changed from AAAAAAAAAAAAAAAAAAAAAA to x8i6qYr8ThquA0Ig3czOlw {"address":{"city":"City_26","state":"State_","zipcode":17060},"itemid":"Item_214","orderid":74,"ordertime":1513588686709,"orderunits":2.5232762555903254} % Headers: [task.generation="0" task.id="0" current.iteration="74"] {"address":{"city":"City_","state":"State_62","zipcode":82411},"itemid":"Item_92","orderid":75,"ordertime":1496362736834,"orderunits":9.612325492383405} % Headers: [task.generation="0" task.id="0" current.iteration="75"] {"address":{"city":"City_","state":"State_74","zipcode":46327},"itemid":"Item_946","orderid":76,"ordertime":1499675318828,"orderunits":8.530168404110228} % Headers: [task.generation="0" task.id="0" current.iteration="76"] ...
Schemas are a powerful tool for building robust data pipelines and ensuring data correctness across applications. In this exercise, you saw how to serialize data using Avro, manage schemas with Schema Registry, and consume Avro-formatted data using a deserializing consumer.
Now you have all the tools you need to start using Schema Registry in your own applications.
Use the promo codes KAFKA101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud storage and skip credit card entry.
Hands-on Exercise: Confluent Schema Registry
In the last exercise, we set up a Source Connector to generate sample data for us according to a predefined schema, we then formatted that data as JSON on the Kafka topic. Now don't get me wrong, JSON is great for a lot of use cases, but if you're looking to increase the robustness of your data pipelines and ensure data correctness across all areas of your system, you really can't go wrong with a good schema. In this hands on exercise, we'll follow a similar workflow as before, but this time we'll see how we can write and serialize the data using Avro and leverage Confluent Schema Registry to manage our schemas. Let's get started. We'll start off in the Confluent Cloud console where we first need to enable the Schema Registry. In the lower left hand corner of the screen select Schema Registry. Here, you can either walk through the guided setup or set up Schema Registry on your own by selecting your desired cloud region. With that out of the way, we can move on and create another Datagen Source Connector. Navigate to data integration and select Connectors. The first thing we have to do is provide a topic for the Datagen Connector to produce data into. You can either create a topic ahead of time and select it from the list here, or create a new topic right from this screen. Let's create a new topic called orders, and set it with all the default configurations. As usual, in order for our Connector to communicate with our cluster, we need to provide an API key for it. You can use an existing API key and secret or auto create one here. There are a number of quick starts available to you with predefined schemas. We'll select the orders data template, and this time we'll format these output messages using Avro. Let's confirm the Connector configuration and launch it. It can take a few minutes to provision the Connector. While that's happening, I wanted to take a moment to explain in more detail why we're choosing to use schema here. When writing data as JSON, we see that it's a lump of data, but with a schema we could perhaps infer or make assumptions about the data just by eyeballing it. With a serialization format like Avro, we also get the benefit of an explicitly declared schema. So there's no guesswork. All right, now that our Connector is up and running, we can go and have a look at the Avro schema that's been set for this output topic and conveniently stored for us in the Schema Registry. You can see all schemas that are in your environment by going to the Schema Registry tab near the bottom left of the screen. From here, you can view and manage all of your schemas and make changes to them if need be. The schema for the value portion of the messages in our orders topic is called orders-value. Similarly, if we were to provide a schema for the key portion of this topic, it would be called orders-key. Select the schema to see all of the fields, their data types, and any constraints, such as nullability that the Datagen Connector has declared for the schema. Before we can consume these messages in the command line, we first need to create an API key for us to connect to the Schema Registry from the command line. Go back to the previous page and create a new Schema Registry API key and secret, store these safely somewhere. Now we can head over to the terminal where we can consume data from the topic. As an exercise in curiosity, let's see what happens if we use the same consumer command from before. You might have noticed that the data is more or less gibberish with a few recognizable strings. Since the data is serialized to the topic using Avro, before where we can read it, the consumer needs to de-serialize it. What we're seeing here is Avro data, but read as if it's just a regular string. So let's do it the right way and use the value format parameter to tell the consumer to de-serialize the value part of the data as Avro. Since it's Avro we also need to tell the consumer what credentials to use for connecting to the Schema Registry where the actual schema itself is stored. If we incorporate that into the consume command, you should now see the messages in all of their well formatted glory. As I mentioned earlier, schemas are a great addition to your system if you're looking to create a robust data pipeline and ensure data correctness across applications. Through this exercise, we saw a bit of this in action. We serialized data from a Source Connector, as Avro, leveraged Schema Registry to store and manage that schema for us, and create a consumer that was able to consume and de-serialize that data after connecting to the Schema Registry. After all of that you have all the tools that you need to start using Schema Registry in your own applications.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.