Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Event Sourcing



Anna McDonald
Principal Customer Success Technical Architect (Presenter)


Ben Stopford
Lead Technologist, Office of the CTO (Author)
Thinking in Events
In this course, you'll learn about how events can be used as the storage model for your applications, whether they're individual applications or an ecosystem of microservices. This first module introduces a way of thinking about system design that is likely different from the more traditional one you are used to. You’ll learn about event modeling using data at rest and data in motion techniques: event sourcing, CQRS, and event streaming.
After you finish this course, you can learn more about its core ideas in the O'Reilly publication Designing Event-Driven Systems.
The Real World Modelled in Software
When you design and build a software system, you're creating a model that corresponds to a real-world system, whether it's for booking taxis, buying hightops, or completing financial transactions:
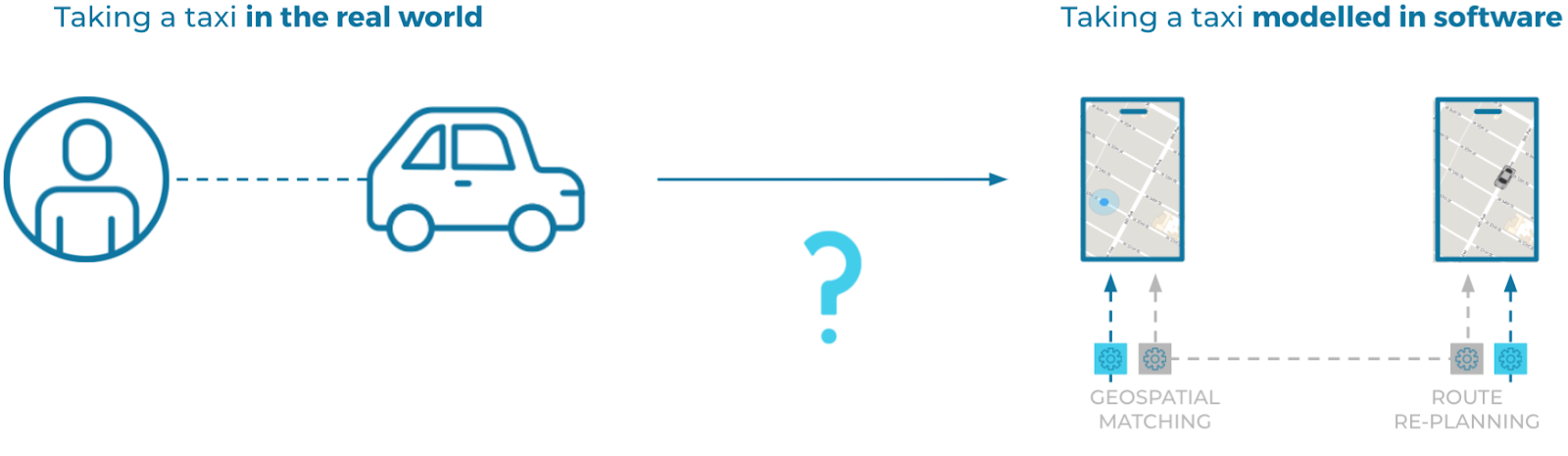
To build your model, you need some kind of coordinate system that you can use to map the real-world system to its software equivalent, analogous to the way that science maps the outside world using mathematics.
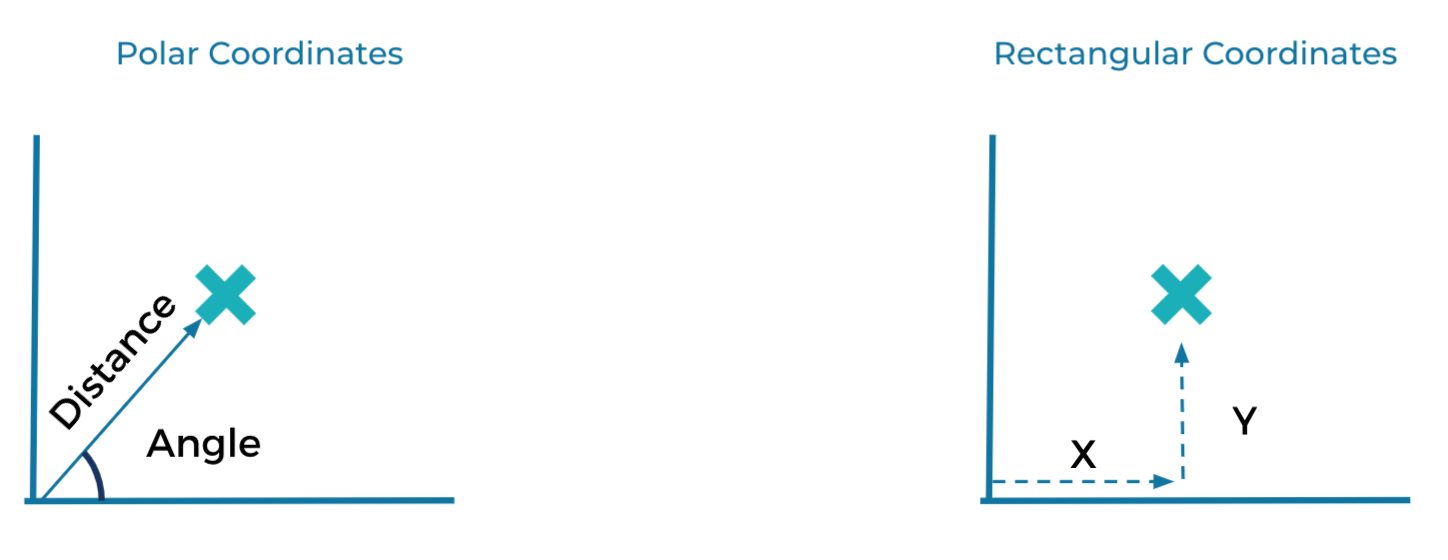
In mathematics, the two dominant systems are polar coordinates and rectangular, or Cartesian coordinates. With polar coordinates, you model a position by an angle and a distance, much like how a fighter pilot calls out a bogey as being "a half-mile up at 4 o'clock." Conversely, with Cartesian coordinates, you model a position using two perpendicular dimensions, similar to making a point on a map using longitude and latitude.
All future problems you might face can in fact be solved using either coordinate system, but some problems are a much better fit for one than for the other. For example, modeling the motion of planets around the sun is much simpler using the polar coordinates system—the math just works out better.
State-Based vs. Event-Based Systems
Similarly, software has two coordinate systems: state-based and event-based. A state-based model of a taxicab system uses a database and synchronous network calls to coordinate state in the system. An event-based model, however, uses continuous and asynchronous streams of immutable events. As with mathematics, you can solve nearly any problem you might face with either software system, but some problems are better solved with one instead of the other.

Illustrating Event-Based vs. State-Based Systems with Chess
Modeling the current state of a chess game is a problem that can help to demonstrate the differences between the state-based and event-based approaches. To describe a point in a chess game using a state-based approach, you would need to go through all of the chess pieces one by one, and record their positions as X and Y coordinates:
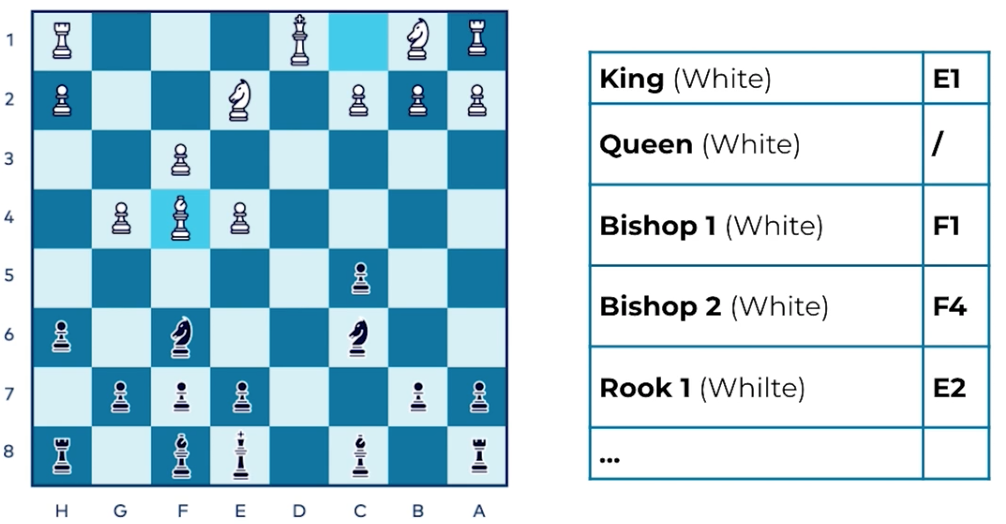
In this approach, you are essentially taking a snapshot of the board that can be saved for later. This is exactly how state-based modelling works using a database: you record the current position of all of the actors in the system, and store those positions in a database table.
Event modeling is quite different when applied to a chess match. To reach the current state of the board, rather than taking a snapshot, you would replay each move from the start to the present, one at a time:
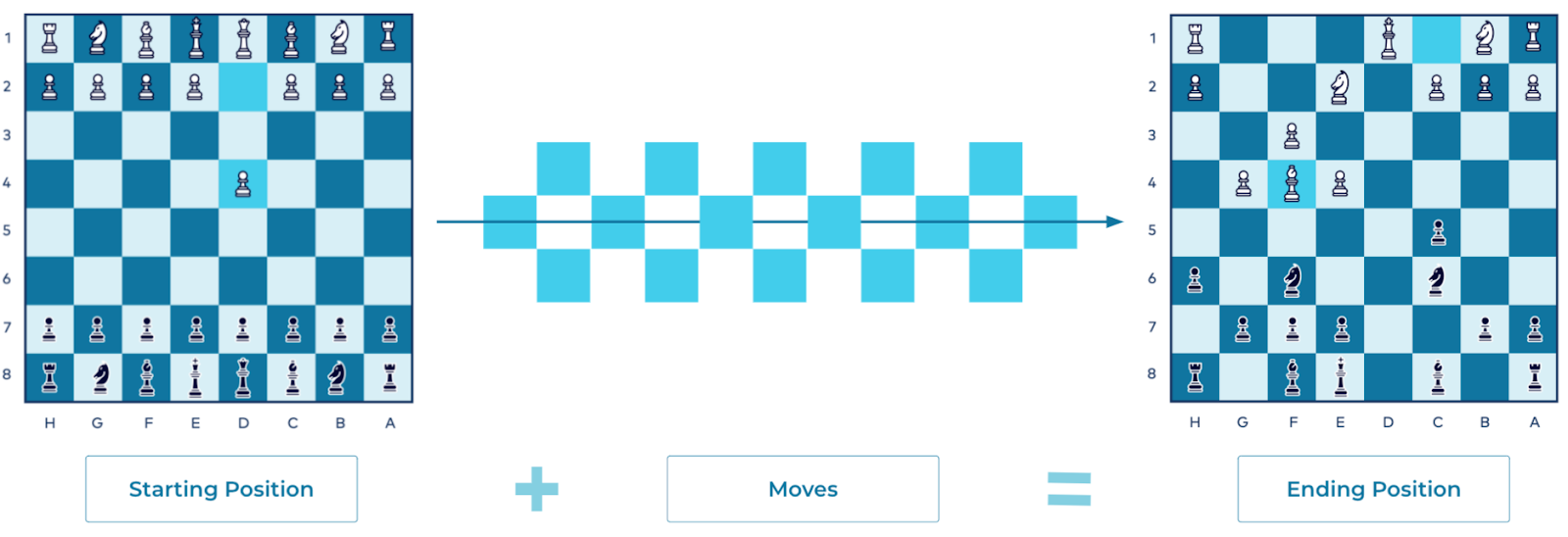
You can recreate any point in the game using this method. Each chess move is an event, a transition from one state to the next. The event doesn't need to contain information about the other pieces on the board (although it could), but unlike with the state-based approach, you need the entire stream of events to derive the current position of all of the pieces on the board. (Note that this process can be accomplished with a traditional database approach, but it's far less natural to do so.)
Generally, events and transitions work best when you're modeling how something evolves over time. Additionally, the event-modeling approach is better suited to today's larger systems than the state-based approach, since they tend to include a greater number of separate parts.
Setting Up Confluent Cloud
Later in the course, you'll get to try out event sourcing yourself, with a client of your choice and ksqlDB. If you provision your cluster now, you can be sure that it will be up and running when you reach the exercise.
You can get extra free cloud time using the promo code EVENTS101. You can also use the promo code CONFLUENTDEV1 to delay entering a credit card for 30 days. To get started, visit https://cnfl.io/confluent-cloud (details) and click Try Free. Enter your name, email address, and password. You will use these later to log in to Confluent Cloud. Select the Start Free button and watch your inbox for a confirmation email to continue.
The link in your confirmation email will lead you to the next step for creating a Kafka cluster, where you should choose a Basic cluster. Click Begin Configuration to choose your preferred cloud provider, region, and availability zone and click Continue. Review your selections, give your cluster a name, and then click Launch cluster. This might take a few minutes.
Finally, from your new cluster, create a new ksqlDB application using the Global Access control option along with a size of 4 Confluent Streaming Units (CSUs), and name the application shopping_cart_database. Starting the process of provisioning the ksqlDB application now will ensure that it is ready for hands-on modules later in the course.
Note that you should be careful to delete your cluster and ksqlDB application when you are finished with them or if you aren't using them for a long period of time. Instructions for deleting are given in Hands-On: Trying Out Event Sourcing.
Errata
- The Confluent Cloud signup process illustrated in this video includes a step to enter payment details. This requirement has been modified. Use the promo code EVENTS101 to receive $25 of free Confluent Cloud usage. Use the promo code CONFLUENTDEV to delay entering a credit card for 30 days.
- Previous
- Next
Use the promo code EVENTS101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Event Sourcing
Welcome to this course on Event Sourcing and Event Storage with Apache Kafka. In it, we'll learn about how events can be used as a storage model for the applications we build, be they individual applications or an ecosystem of microservices. In this first module, we're going to introduce a different way of thinking about system design than the more traditional one you may be used to. This course accompanies the book, "Designing Event Driven Systems." If you'd like to look further into the subject matter, there's a link below where you can download the book for free. When you design and build a software system, you're creating a model that describes a real-world system. The real-world system can be anything. Someone booking a taxi, buying a new pair of high-tops, completing a financial transaction. In fact, just about anything. To build your model, you need some kind of coordinate system, which you can use to map the real world into your software. This is analogous to the way science models the outside world using mathematics. In mathematics, the two dominant coordinate systems are polar coordinates and rectangular or Cartesian coordinates. In polar coordinates, you model a position by an angle and a distance, much like a fighter pilot might communicate a bogey being at a half a mile off four o'clock. In Cartesian coordinates, you model position using two perpendicular dimensions, like making a point on a map using longitude and latitude. All problems you face can be solved in either coordinate system, but some problems are a much better fit for one versus the other. For example, modeling the motion of the planets around the sun is much simpler using the polar coordinate system. The math just works out better. Similarly, the design of software system has two coordinate systems: state-based and event-based. For example, a state-based model of a taxi cab system would use a database and synchronous network calls to coordinate the state and the system. The event-based model would use continuous and asynchronous streams of immutable events. You can solve pretty much any problem you might face with either type of model, but just like in mathematics, some problems suit one modeling approach better than the other. In this course, you're gonna get familiar with a second form, modeling with events using data at rest and data in motion techniques, event sourcing, CQRS, event streaming, et cetera. A good place to start this process is to think about a chess game. Say we are mid game and we want to save the position of all the pieces. Chess is another good example of something that offers us two coordinate systems that achieve the same result, the positions of all the pieces, but achieved in wildly different ways. In the first method, you go through all the pieces on the chess board one by one and record their position as X and Y coordinates. So white king is at coordinator E1, white rook is at coordinate E2 and so on. We're essentially taking a kind of snapshot of the state of the board, which can be saved for later, and this is exactly analogous to how state-based modeling works using a database. We record the current position of all the actors in the system and store those positions in a database table. Event modeling is different. Rather than taking a snapshot of the whole board, we noticed that the game of chess has a known starting state, the starting position. From there, a number of moves are made. So if we replay all the moves from the starting position, we can recreate any point in the game. Each chess move is an event. A transition from one state to the next. The event doesn't need to contain information about the positions of other pieces on the board, although there's nothing to stop it from doing so, but unlike the state-based approach, the whole stream of events is required to derive the current position. So in summary, we have two coordinate systems for modeling real-world problems and software. One uses state and is coordinate based, the other uses events and is transition based. You are likely very familiar with the state-based approach if you're familiar with database development, but the event modeling approach, although less popular is better suited to many of today's problems, particularly as systems get larger and incorporate a greater number of separate parts. As a final point, we should ask ourselves this question, "Why do I need this other approach at all?" The answer lies in the chess game itself. If you use events, you will naturally map out the game as it is being played. This can be done with a database, but it's far less natural to do so. Transitions and events work best when you're modeling how something evolves over time. Later in the course, you'll get the opportunity to try out event sourcing yourself with a client of your choice in ksqlDB. If you start your cluster now, it'll ensure it's up and running, ready for you when you get to the exercise module. The promo code will provide you with an extra free cloud time. So make sure you enter it when you log in. To get started, go to the URL on the screen and click the Try Free button. Then, enter your name, email and password. This email and password will be used to log into Confluent Cloud later. So be sure to remember it. Or put it on a post-it note on your monitor. Okay, maybe don't do that. Click the Start Free button and watch your inbox for a confirmation email to continue. The link in your confirmation email will lead you to the next step where you can choose between a basic, standard or dedicated cluster. The associated cost are listed, but the startup amount freely provided to you will more than cover anything you need for this course. Click Begin Configuration to choose your preferred cloud provider, region and availability zone. Cost will vary with these choices, but they're clearly shown on the bottom of the screen. Continue to set up billing info. Here you'll see that you receive $200 of free usage each month for your first three months. Also by entering the promo code, EVENTS101, you receive an additional $101 of free usage to give you plenty of room to try out the things we'll be talking about. Click Review to get one last look at the choices you've made. Then launch your new cluster. While your cluster is provisioning, join me for the next module in this course. In that module, we'll dive right into event sourcing and explain what it is with a more practical and realistic example.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.