Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Connectors, Configuration, Converters, and Transforms



Danica Fine
Senior Developer Advocate (Presenter)
Inside Kafka Connect
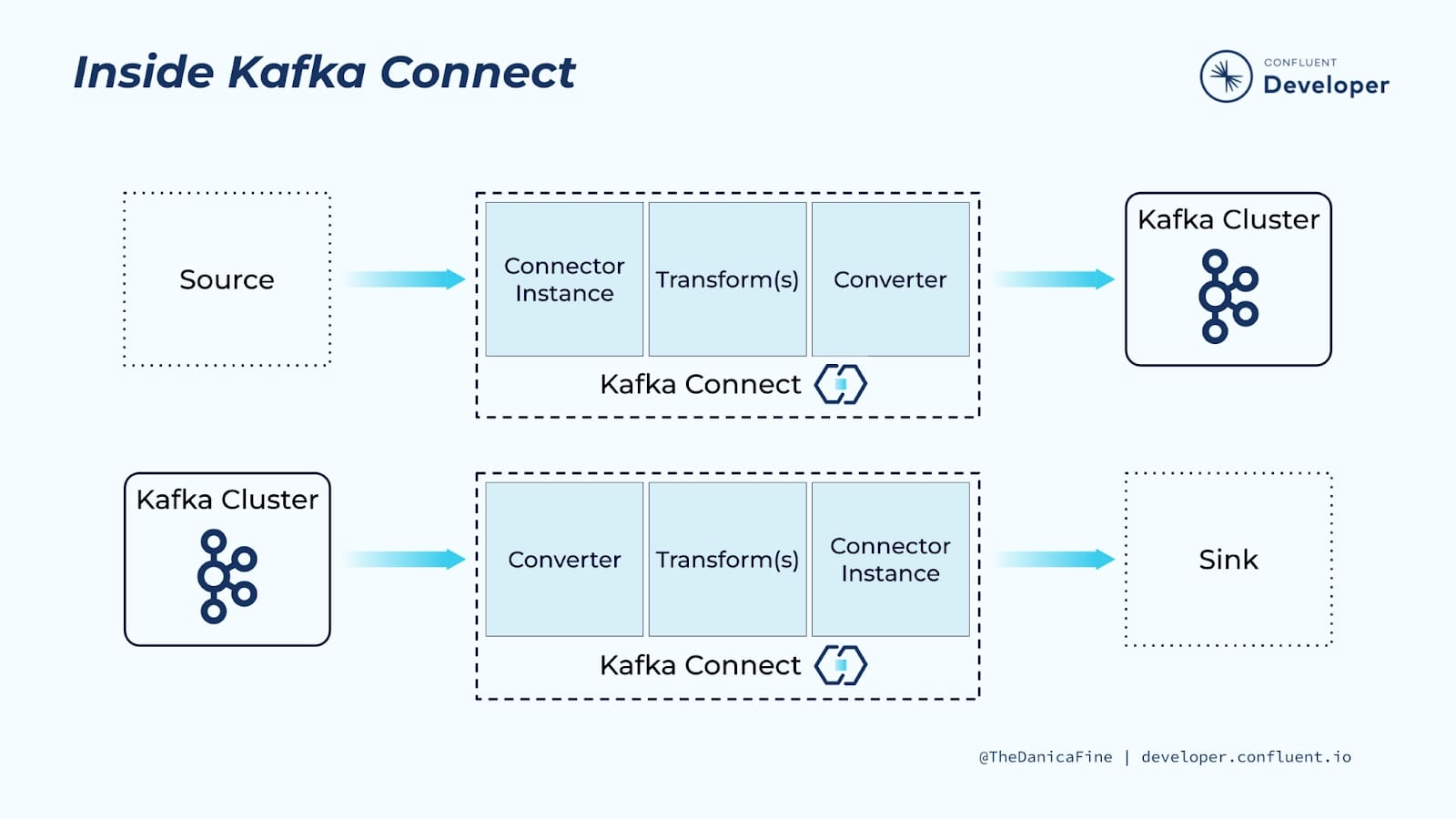
Kafka Connect is built around a pluggable architecture of several components, which together provide very flexible integration pipelines. To get the most out of Kafka Connect it’s important to understand these components and their roles:
- Connectors are responsible for the interaction between Kafka Connect and the external technology it’s being integrated with
- Converters handle the serialization and deserialization of data
- Transformations can optionally apply one or more transformations to the data passing through the pipeline
Connectors

The key component of any Kafka Connect pipeline is a connector instance which is a logical job that defines where data should be copied to and from. All of the classes that implement or are used by a connector instance are defined in its connector plugin. Written by the community, a vendor, or occasionally written bespoke by the user, the plugin integrates Kafka Connect with a particular technology. These plugins are reusable components that you can download, install, and use without writing code.
For example:
- The Debezium MySQL source connector uses the MySQL bin log to read events from the database and stream these to Kafka Connect
- The Elasticsearch sink connector takes data from Kafka Connect, and using the Elasticsearch APIs, writes the data to Elasticsearch
- The S3 connector from Confluent can act as both a source and sink connector, writing data to S3 or reading it back in
A SOURCE connector plugin knows how to talk to a specific SOURCE data system and generate records that Kafka Connect then writes into Kafka. On the downstream side, the connector instance configuration specifies the topics to be consumed and Kafka Connect reads those topics and sends them to the SINK connector that knows how to send those records to a specific SINK data system.
So the connectors know how to work with the records and talk to the external data system, but Kafka Connect workers act as the conductor and take care of the rest. We will define what a worker is shortly.
Add a Connector Instance with the REST API
To specify a connector you include its name in your configuration—each connector's documentation will give you the particular classname string to use. As you may expect, connectors have different configuration properties specific to the technology with which they’re integrating. A cloud connector will need to know the region, the credentials, and the endpoint to use. A database connector will need to know the names of the tables, the database hostname, and so on.
Here’s an example that creates an Elasticsearch sink connector instance with a call to Kafka Connect’s REST API:
curl -X PUT -H "Content-Type:application/json" http://localhost:8083/connectors/sink-elastic-01/config \
-d '{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"topics" : "orders",
"connection.url" : "http://elasticsearch:9200",
"type.name" : "_doc",
"key.ignore" : "false",
"schema.ignore" : "true"
}'Add a Connector Instance with ksqlDB
You can also use ksqlDB to manage connectors.
Here is the syntax for adding the previous Elasticsearch sink connector instance:
CREATE SINK CONNECTOR sink-elastic-01 WITH (
'connector.class' = 'io.confluent.connect.elasticsearch.ElasticsearchSinkConnector',
'topics' = 'orders',
'connection.url' = 'http://elasticsearch:9200',
'type.name' = '_doc',
'key.ignore' = 'false',
'schema.ignore' = 'true'
);Add a Connector Instance with the Console UI

In addition to using the Kafka Connect REST API directly, you can add connector instances using the Confluent Cloud console.
What Is the Role of the Connector?

It’s important to understand that the connector plugins themselves don't read from or write to (consume/produce) Kafka itself. The plugins just provide the interface between Kafka and the external technology. This is a deliberate design.
- Source connectors interface with the source API and extract the payload + schema of the data, and pass this internally as a generic representation of the data.
- Sink connectors work in reverse—they take a generic representation of the data, and the sink connector plugin writes that to the target system using its API.
Kafka Connect and its underlying components take care of writing data received from source connectors to Kafka topics as well as reading data from Kafka topics and passing it to sink connectors.
Now, this is all hidden from the user—when you add a new connector instance, that’s all you need to configure and Kafka Connect does the rest to get the data flowing. Converters are the next piece of the puzzle and it is important to understand them to help you avoid common pitfalls with Kafka Connect. Technically, transforms sit between connectors and converters, but we’ll visit those later.
Converters Serialize/Deserialize the Data

Converters are responsible for the serialization and deserialization of data flowing between Kafka Connect and Kafka itself. You’ll sometimes see similar components referred to as SerDes (“SerializerDeserializer”) in Kafka Streams, or just plain old serializers and deserializers in the Kafka Client libraries.
There are a ton of different converters available, but some common ones include:
- Avro – io.confluent.connect.avro.AvroConverter
- Protobuf – io.confluent.connect.protobuf.ProtobufConverter
- String – org.apache.kafka.connect.storage.StringConverter
- JSON – org.apache.kafka.connect.json.JsonConverter
- JSON Schema – io.confluent.connect.json.JsonSchemaConverter
- ByteArray – org.apache.kafka.connect.converters.ByteArrayConverter
While Kafka doesn’t care about how you serialize your data (as far as it’s concerned, it’s just a series of bytes), you should care about how you serialize your data! In the same way that you would take a carefully considered approach to how you design your services and model your data, you should also be deliberate in your serialization approach.
Serialization and Schemas

As well as managing the straightforward matter of serializing data flowing into Kafka and deserializing it on its way out, converters have a crucial role to play in the persistence of schemas. Almost all data that we deal with has a schema; it’s up to us whether we choose to acknowledge that in our designs or not. You can consider schemas as the API between applications and components of a pipeline. Schemas are the contract between one component in the pipeline and another, describing the shape and form of the data.
When you ingest data from a source such as a database, as well as the rows of data, you have the metadata that describes the fields—the data types, their names, etc. Having this schema metadata is valuable, and you will want to retain it in an efficient manner. A great way to do this is by using a serialization method such as Avro, Protobuf, or JSON Schema. All three of these will serialize the data onto a Kafka topic and then store the schema separately in the Confluent Schema Registry. By storing the schema for data, you can easily utilize it in your consuming applications and pipelines. You can also use it to enforce data hygiene in the pipeline by ensuring that only data that is compatible with the schema is stored on a given topic.
You can opt to use serialization formats that don’t store schemas like JSON, string, and byte array, and in some cases, these are valid. If you use these, just make sure that you are doing so for deliberate reasons and have considered how else you will handle schema information.
Converters Specified for Key and Value
Converters are specified separately for the value of a message, and its key:
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
value.converter.schema.registry.url=http://localhost:8081Note that these converters are set as a global default per Connect worker, but they can be overridden per connector instance.
Single Message Transforms

The third and final key component in Kafka Connect is the transform piece. Unlike connectors and converters, these are entirely optional. You can use them to modify data from a source connector before it is written to Kafka, and modify data read from Kafka before it’s written to the sink. Transforms operate over individual messages as they move, so they’re known as Single Message Transforms or SMTs.
Common uses for SMTs include:
- Dropping fields from data at ingest, such as personally identifiable information (PII) if specified by the system requirements
- Adding metadata information such as lineage to data ingested through Kafka Connect
- Changing field data types
- Modifying the topic name to include a timestamp
- Renaming fields
For more complex transformations, including aggregations and joins to other topics or lookups to other systems, a full stream processing layer in ksqlDB or Kafka Streams is recommended.
Obtaining Plugins and Writing Your Own

Connectors, transforms, and converters are all specified as part of the Kafka Connect API, and you can consult the Javadoc to write your own.
Apache Kafka and Confluent have several converters and transforms built in already, but you can install more if you need them. You will find these along with hundreds of connectors in Confluent Hub.
Now that we know the theory, let's take the previous hands-on exercise a step further and transform the input records before writing them to a Kafka topic. In the exercise that follows we'll do exactly that and see how easy it is to do so using Confluent Cloud.
Use the promo code 101CONNECT & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Connectors, Configuration, Converters, and Transforms
Hi, Danica Fine here. Let's take a deeper look into some of the components of Kafka Connect and the critical roles they play in moving your data. Kafka Connect is built around a pluggable architecture of several components, which together provide very flexible integration pipelines. Inside Kafka Connect To get the most out of Kafka Connect it's important to understand these components and their roles. Connectors are responsible for the interaction between Kafka Connect and the external technology being integrated with. Converters handle the serialization and deserialization of data. Transformations can optionally apply one or more transformations to the data passing through the pipeline. The key component of any Kafka Connect pipeline is a connector instance, which is a logical job that defines where data should be copied to and from. All of the classes that implement or are used by a connector instance are defined in its connector plugin. Written by the community, a vendor, or occasionally written bespoke by the user, the plugin integrates Kafka Connect with a particular technology. These plugins are reusable components that you can download, install, and use without writing any code. For example, the Debezium MySQL source connector Connectors uses the MySQL bin log to read events from the database and stream these to Kafka. The ElasticSearch Sink Connector takes data from Kafka, and using the ElasticSearch APIs, writes the data to ElasticSearch. The S3 Connector from Confluent can act as both a source and sink connector, writing data to S3 or reading it back in. A source connector plugin knows how to talk to a specific source system and generate records that Kafka Connect then writes into Kafka. On the downstream side, the connector instance configuration specifies the topics to be consumed and Kafka Connect reads those topics and sends them to the sink connector that knows how to send those records to a specific sink system. So the connectors know how to work with the records and talk to the external system, but Kafka Connect workers are acting as the conductor and taking care of the rest. We will define what a worker is shortly so we'll get back to that. Add a Connector Instance with the REST API To specify a connector, you include its name and your configuration. Every connector's documentation will give you the particular class name string to use. As you might expect, connectors have different configuration properties specific to the technology with which they're integrating. For example, a cloud connector will need to know the region, the credentials, and also the endpoint to use. A database connector, however, will need to know the names of the tables, the database host name, and so on. Here's an example of creating an ElasticSearch Sink Connector instance with a call to Kafka Connect's REST API. You can also use ksqlDB to manage your connectors. Here's the syntax for adding the previous ElasticSearch Sink Connector instance through ksqlDB. In addition to using the Kafka Connect REST API directly, Add a Connector Instance with the Console UI you can add connector instances using the Confluent Cloud Console. It's important to understand that the connector plugins themselves don't read from or write to Kafka itself. The plugins just provide the interface between Kafka and the external technology. And this is a deliberate design decision. Source connectors interface with the source API What is the Role of the Connector? and extract the payload and schema of the data, and this is then passed internally as a generic representation of the data. Sink connectors work in reverse. They take a generic representation of the data and the sink connector plugin writes that to the target system, using its API. Kafka Connect and its underlying components take care of writing data received from source connectors to Kafka topics, as well as reading data from Kafka topics and passing it to sink connectors. Now, this is all hidden from the user. When you add a new connector instance, that's all you need to configure and Kafka Connect does the rest to get the data flowing. But understanding the next piece in the puzzle is important to help you avoid some of the common pitfalls with Kafka Connect, and that's converters. Technically, transforms sit between connectors and converters, but we'll get back to those later. Converters are responsible for the serialization Converters Serialize/Deserialize the Data and deserialization of data flowing between Kafka Connect and Kafka itself. You'll sometimes see similar components referred to you as serdes, or serializer deserializers, in Kafka streams or just plain old serializers and deserializers in the Kafka Client Libraries. There are a ton of different converters available, but some common ones include Avro, Protobuf, and JSON. While Kafka doesn't care about how you serialize your data, as far as it's concerned, it's just a series of bites, you should care about how you serialize your data. In the same way that you would take a carefully considered approach to how you design your services and model your data, you should also be deliberate in your serialization approach. As well as managing the straightforward matter Serialization and Schemas of serializing data flowing into Kafka and decentralizing it on its way out, converters have a crucial role to play in the persistence of schemas. Almost all data that we deal with has a schema. It's just up to us whether we choose to acknowledge that in our designs or not. You can consider schema as the API between applications and components of a pipeline. Schemas are the contract between one component in the pipeline and another, describing the shape and form of the data. When you ingest data from a source, such as a database, as well as the rows of data, you have the metadata that describes the fields, the data types, their names, and more. Having the schema metadata is valuable and you'll want to retain it in an efficient manner. A great way to do this is by using a serialization method such as Avro, Protobuf, or JSON schema. All three of these will serialize the data onto a Kafka topic, and then store the schema separately in the Confluent Schema Registry. By storing the schema for data, you can easily utilize it in your consuming applications and downstream in the pipeline. You can also use it to enforce data hygiene in the pipeline by ensuring that only data that is compatible with the schema is stored on a given Kafka topic. Now you can opt to use serialization formats that don't store schema, like JSON, string, or byte array. And in some cases, these are completely valid. But if you use these, just make sure that you're doing so for deliberate reasons and have considered how else you'll handle schema information. Converters Specified for key and Value Converters are specified separately for the value of a message and it's key. And note that these converters are set as a global default per connect worker, but they can be overridden per connector instance. The third and final key component in Kafka Connect Single Message Tranforms is the transform piece. Now unlike connectors and converters, these are entirely optional. You can use them to modify data from a source connector before it's written to Kafka or modify data read from Kafka before it's written to the sink. Transforms operate over individual messages as they move, so they're known as single message transforms or SMTs. Some common uses for SMTs include dropping fields from data at ingest such as personally identifiable information if specified by the system requirements, adding metadata information, such as lineage, to data ingested through Kafka Connect, changing field data types, modifying the topic name to include a timestamp, or renaming fields. For more complex transformations, including aggregations and joins to other topics or lookups to other systems, a full stream processing layer in ksqlDB or Kafka streams is recommended. Connectors, transforms, and converters are all specified as part of the Kafka Connect API, and you can consult the Java docs to write your own. Apache Kafka and Confluent have several converters and transforms built in already, but you can install more if you need them. You'll find these, along with hundreds of connectors, in the Confluent Hub, Now that we know the theory, let's take the previous hands-on exercise a step further and transform the input records before writing them to a Kafka topic. In the exercise that follows, we'll do exactly that, and see how easy it is to do so, using Confluent cloud. You'll continue to learn more about Kafka Connect in the coming modules and exercises, but now you should have a pretty decent idea of the importance of each of the Kafka Connect components has. See you in the next module where we'll put this information into practice.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.