Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
How to aggregate over tumbling windows with Flink SQL
How to aggregate over tumbling windows with Flink SQL
Suppose you have time series events in a Kafka topic and wish to calculate statistics on the events grouped into fixed-size, non-overlapping, contiguous time intervals called tumbling windows. For example, let's say you have a topic with events that represent movie ratings from viewers over time. In this tutorial, we'll use Flink SQL to count the total number of ratings that each movie has received and calculate the average rating over tumbling windows.
Setup
Because windowed aggregations are calculated on a base table, let's assume the following DDL for our base ratings table:
CREATE TABLE ratings (
rating_id INT,
title STRING,
release_year INT,
rating DOUBLE,
ts TIMESTAMP(3),
-- declare ts as event time attribute and use strictly ascending timestamp watermark strategy
WATERMARK FOR ts AS ts
);The timestamp is an important attribute since we’ll be modeling the number of ratings that each movie receives over time. Also, because we are going to aggregate over time windows, we must define a watermark strategy. In this case, we use strictly ascending timestamps, i.e., any row with a timestamp that is less than or equal to the latest observed event timestamp is considered late and ignored.
Compute windowed aggregation
Given the ratings table definition above, let’s figure out the rating count and average rating in tumbling 6-hour intervals using a windowing table-valued function (TVF).
SELECT title,
COUNT(*) AS rating_count,
AVG(rating) AS avg_rating,
window_start,
window_end
FROM TABLE(TUMBLE(TABLE ratings, DESCRIPTOR(ts), INTERVAL '6' HOURS))
GROUP BY title, window_start, window_end;Running the example
You can run the example backing this tutorial in one of three ways: a Flink Table API-based JUnit test, locally with the Flink SQL Client against Flink and Kafka running in Docker, or with Confluent Cloud.
Flink Table API-based test
Prerequisites
- Java 17, e.g., follow the OpenJDK installation instructions here if you don't have Java.
- Docker running via Docker Desktop or Docker Engine
Run the test
Clone the confluentinc/tutorials GitHub repository (if you haven't already) and navigate to the tutorials directory:
git clone git@github.com:confluentinc/tutorials.git
cd tutorialsRun the following command to execute FlinkSqlTumblingWindowTest#testTumblingWindows:
./gradlew clean :tumbling-windows:flinksql:testThe test starts Kafka and Schema Registry with Testcontainers, runs the Flink SQL commands above against a local Flink StreamExecutionEnvironment, and ensures that tumbling window query results are what we expect.
Flink SQL Client CLI
Prerequisites
- Docker running via Docker Desktop or Docker Engine
- Docker Compose. Ensure that the command docker compose version succeeds.
Run the commands
Clone the confluentinc/tutorials GitHub repository (if you haven't already) and navigate to the tutorials directory:
git clone git@github.com:confluentinc/tutorials.git
cd tutorialsStart Flink and Kafka:
docker compose -f ./docker/docker-compose-flinksql.yml up -dNext, open the Flink SQL Client CLI:
docker exec -it flink-sql-client sql-client.shFinally, run following SQL statements to create the ratings table backed by Kafka running in Docker, populate it with test data, and run the tumbling windows query.
CREATE TABLE ratings (
rating_id INT,
title STRING,
release_year INT,
rating DOUBLE,
ts TIMESTAMP(3),
-- declare ts as event time attribute and use strictly ascending timestamp watermark strategy
WATERMARK FOR ts AS ts
) WITH (
'connector' = 'kafka',
'topic' = 'ratings',
'properties.bootstrap.servers' = 'broker:9092',
'scan.startup.mode' = 'earliest-offset',
'key.format' = 'raw',
'key.fields' = 'rating_id',
'value.format' = 'avro-confluent',
'value.avro-confluent.url' = 'http://schema-registry:8081',
'value.fields-include' = 'EXCEPT_KEY'
);INSERT INTO ratings VALUES
(0, 'Die Hard', 1998, 8.2, TO_TIMESTAMP('2023-07-09 01:00:00')),
(1, 'The Big Lebowski', 1998, 4.2, TO_TIMESTAMP('2023-07-09 02:00:00')),
(2, 'Die Hard', 1998, 4.5, TO_TIMESTAMP('2023-07-09 05:00:00')),
(3, 'The Big Lebowski', 1998, 9.9, TO_TIMESTAMP('2023-07-09 06:30:00')),
(4, 'Die Hard', 1998, 5.1, TO_TIMESTAMP('2023-07-09 07:00:00')),
(5, 'Tree of Life', 2011, 5.6, TO_TIMESTAMP('2023-07-09 08:00:00')),
(6, 'Tree of Life', 2011, 4.9, TO_TIMESTAMP('2023-07-09 09:00:00')),
(7, 'A Walk in the Clouds', 1995, 3.6, TO_TIMESTAMP('2023-07-09 12:00:00')),
(8, 'A Walk in the Clouds', 1995, 6.0, TO_TIMESTAMP('2023-07-09 15:00:00')),
(9, 'Super Mario Bros.', 1993, 3.5, TO_TIMESTAMP('2023-07-09 18:30:00')),
(10, 'A Walk in the Clouds', 1995, 4.6, TO_TIMESTAMP('2023-07-10 01:00:00'));SELECT title,
COUNT(*) AS rating_count,
AVG(rating) AS avg_rating,
window_start,
window_end
FROM TABLE(TUMBLE(TABLE ratings, DESCRIPTOR(ts), INTERVAL '6' HOURS))
GROUP BY title, window_start, window_end;The query output should look like this:
title rating_count avg_rating window_start window_end
Die Hard 2 6.35 2023-07-09 00:00:00.000 2023-07-09 06:00:00.000
The Big Lebowski 1 4.2 2023-07-09 00:00:00.000 2023-07-09 06:00:00.000
Die Hard 1 5.1 2023-07-09 06:00:00.000 2023-07-09 12:00:00.000
Tree of Life 2 5.25 2023-07-09 06:00:00.000 2023-07-09 12:00:00.000
The Big Lebowski 1 9.9 2023-07-09 06:00:00.000 2023-07-09 12:00:00.000
A Walk in the Clouds 2 4.8 2023-07-09 12:00:00.000 2023-07-09 18:00:00.000
Super Mario Bros. 1 3.5 2023-07-09 18:00:00.000 2023-07-10 00:00:00.000When you are finished, clean up the containers used for this tutorial by running:
docker compose -f ./docker/docker-compose-flinksql.yml downConfluent Cloud
Prerequisites
- A Confluent Cloud account
- A Flink compute pool created in Confluent Cloud. Follow this quick start to create one.
Run the commands
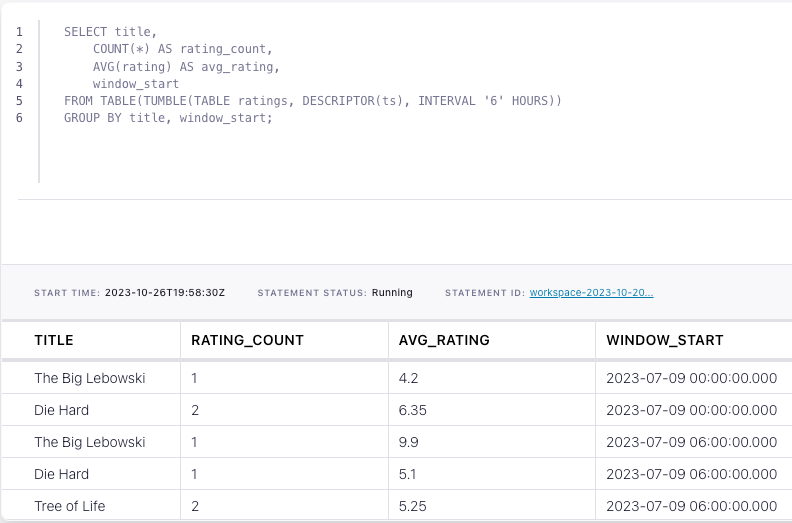
In the Confluent Cloud Console, navigate to your environment and then click the Open SQL Workspace button for the compute pool that you have created.
Select the default catalog (Confluent Cloud environment) and database (Kafka cluster) to use with the dropdowns at the top right.
Finally, run following SQL statements to create the ratings table, populate it with test data, and run the tumbling windows query.
CREATE TABLE ratings (
rating_id INT,
title STRING,
release_year INT,
rating DOUBLE,
ts TIMESTAMP(3),
-- declare ts as event time attribute and use strictly ascending timestamp watermark strategy
WATERMARK FOR ts AS ts
);INSERT INTO ratings VALUES
(0, 'Die Hard', 1998, 8.2, TO_TIMESTAMP('2023-07-09 01:00:00')),
(1, 'The Big Lebowski', 1998, 4.2, TO_TIMESTAMP('2023-07-09 02:00:00')),
(2, 'Die Hard', 1998, 4.5, TO_TIMESTAMP('2023-07-09 05:00:00')),
(3, 'The Big Lebowski', 1998, 9.9, TO_TIMESTAMP('2023-07-09 06:30:00')),
(4, 'Die Hard', 1998, 5.1, TO_TIMESTAMP('2023-07-09 07:00:00')),
(5, 'Tree of Life', 2011, 5.6, TO_TIMESTAMP('2023-07-09 08:00:00')),
(6, 'Tree of Life', 2011, 4.9, TO_TIMESTAMP('2023-07-09 09:00:00')),
(7, 'A Walk in the Clouds', 1995, 3.6, TO_TIMESTAMP('2023-07-09 12:00:00')),
(8, 'A Walk in the Clouds', 1995, 6.0, TO_TIMESTAMP('2023-07-09 15:00:00')),
(9, 'Super Mario Bros.', 1993, 3.5, TO_TIMESTAMP('2023-07-09 18:30:00')),
(10, 'A Walk in the Clouds', 1995, 4.6, TO_TIMESTAMP('2023-07-10 01:00:00'));SELECT title,
COUNT(*) AS rating_count,
AVG(rating) AS avg_rating,
window_start
FROM TABLE(TUMBLE(TABLE ratings, DESCRIPTOR(ts), INTERVAL '6' HOURS))
GROUP BY title, window_start;The query output should look like this: