Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
How to split a stream of events into substreams with Flink SQL
How to split a stream of events into substreams with Flink SQL
Suppose that you have a Kafka topic representing appearances of an actor or actress in a film, with each event denoting the genre. In this tutorial, we'll use Flink SQL to split the stream into substreams based on the genre. We'll have a topic for drama films, a topic for fantasy films, and a topic for everything else.
Setup
Let's assume the following DDL for our base acting_events table:
CREATE TABLE acting_events (
name STRING,
title STRING,
genre STRING
);Route events
Given the acting_events table definition above, we can create separate tables per genre and populate them as follows:
CREATE TABLE acting_events_drama (
name STRING,
title STRING
);
INSERT INTO acting_events_drama
SELECT name, title
FROM acting_events
WHERE genre = 'drama';
CREATE TABLE acting_events_fantasy (
name STRING,
title STRING
);
INSERT INTO acting_events_fantasy
SELECT name, title
FROM acting_events
WHERE genre = 'fantasy';
CREATE TABLE acting_events_other (
name STRING,
title STRING
);
INSERT INTO acting_events_other
SELECT name, title
FROM acting_events
WHERE genre <> 'drama' AND genre <> 'fantasy';Running the example
You can run the example backing this tutorial in one of three ways: a Flink Table API-based JUnit test, locally with the Flink SQL Client against Flink and Kafka running in Docker, or with Confluent Cloud.
Flink Table API-based test
Prerequisites
- Java 17, e.g., follow the OpenJDK installation instructions here if you don't have Java.
- Docker running via Docker Desktop or Docker Engine
Run the test
Clone the confluentinc/tutorials GitHub repository (if you haven't already) and navigate to the tutorials directory:
git clone git@github.com:confluentinc/tutorials.git
cd tutorialsRun the following command to execute FlinkSqlSplitStreamTest#testSplit:
./gradlew clean :splitting:flinksql:testThe test starts Kafka and Schema Registry with Testcontainers, runs the Flink SQL commands above against a local Flink StreamExecutionEnvironment, and ensures that the routed results are what we expect.
Flink SQL Client CLI
Prerequisites
- Docker running via Docker Desktop or Docker Engine
- Docker Compose. Ensure that the command docker compose version succeeds.
Run the commands
Clone the confluentinc/tutorials GitHub repository (if you haven't already) and navigate to the tutorials directory:
git clone git@github.com:confluentinc/tutorials.git
cd tutorialsStart Flink and Kafka:
docker compose -f ./docker/docker-compose-flinksql.yml up -dNext, open the Flink SQL Client CLI:
docker exec -it flink-sql-client sql-client.shFinally, run following SQL statements to create the acting_events table backed by Kafka running in Docker, populate it with test data, and then create and populate a table for drama events.
CREATE TABLE acting_events (
name STRING,
title STRING,
genre STRING
) WITH (
'connector' = 'kafka',
'topic' = 'acting-events',
'properties.bootstrap.servers' = 'broker:9092',
'scan.startup.mode' = 'earliest-offset',
'key.format' = 'avro-confluent',
'key.avro-confluent.url' = 'http://schema-registry:8081',
'key.fields' = 'name;title',
'value.format' = 'avro-confluent',
'value.avro-confluent.url' = 'http://schema-registry:8081',
'value.fields-include' = 'ALL'
);INSERT INTO acting_events VALUES
('Bill Murray', 'Ghostbusters', 'fantasy'),
('Christian Bale', 'The Dark Knight', 'crime'),
('Diane Keaton', 'The Godfather: Part II', 'crime'),
('Jennifer Aniston', 'Office Space', 'comedy'),
('Judy Garland', 'The Wizard of Oz', 'fantasy'),
('Keanu Reeves', 'The Matrix', 'fantasy'),
('Laura Dern', 'Jurassic Park', 'fantasy'),
('Matt Damon', 'The Martian', 'drama'),
('Meryl Streep', 'The Iron Lady', 'drama'),
('Russell Crowe', 'Gladiator', 'drama'),
('Will Smith', 'Men in Black', 'comedy');CREATE TABLE acting_events_drama (
name STRING,
title STRING
)
WITH (
'connector' = 'kafka',
'topic' = 'acting-events-drama',
'properties.bootstrap.servers' = 'broker:9092',
'scan.startup.mode' = 'earliest-offset',
'key.format' = 'avro-confluent',
'key.avro-confluent.url' = 'http://schema-registry:8081',
'key.fields' = 'name;title',
'value.format' = 'avro-confluent',
'value.avro-confluent.url' = 'http://schema-registry:8081',
'value.fields-include' = 'ALL'
);INSERT INTO acting_events_drama
SELECT name, title
FROM acting_events
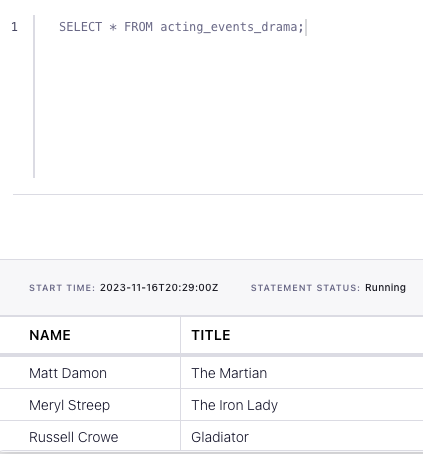
WHERE genre = 'drama';SELECT * FROM acting_events_drama;The query output should look like this:
name title
Matt Damon The Martian
Meryl Streep The Iron Lady
Russell Crowe GladiatorWhen you are finished, clean up the containers used for this tutorial by running:
docker compose -f ./docker/docker-compose-flinksql.yml downConfluent Cloud
Prerequisites
- A Confluent Cloud account
- A Flink compute pool created in Confluent Cloud. Follow this quick start to create one.
Run the commands
In the Confluent Cloud Console, navigate to your environment and then click the Open SQL Workspace button for the compute pool that you have created.
Select the default catalog (Confluent Cloud environment) and database (Kafka cluster) to use with the dropdowns at the top right.
Finally, run following SQL statements to create the acting_events table, populate it with test data, create and populate a table for drama acting events, and query this derived table.
CREATE TABLE acting_events (
name STRING,
title STRING,
genre STRING
);INSERT INTO acting_events VALUES
('Bill Murray', 'Ghostbusters', 'fantasy'),
('Christian Bale', 'The Dark Knight', 'crime'),
('Diane Keaton', 'The Godfather: Part II', 'crime'),
('Jennifer Aniston', 'Office Space', 'comedy'),
('Judy Garland', 'The Wizard of Oz', 'fantasy'),
('Keanu Reeves', 'The Matrix', 'fantasy'),
('Laura Dern', 'Jurassic Park', 'fantasy'),
('Matt Damon', 'The Martian', 'drama'),
('Meryl Streep', 'The Iron Lady', 'drama'),
('Russell Crowe', 'Gladiator', 'drama'),
('Will Smith', 'Men in Black', 'comedy');CREATE TABLE acting_events_drama (
name STRING,
title STRING
);INSERT INTO acting_events_drama
SELECT name, title
FROM acting_events
WHERE genre = 'drama';SELECT * FROM acting_events_drama;The query output should look like this: