Hands On: Partitioning



Danica Fine
Senior Developer Advocate (Presenter)
Hands On: Partitioning
Up until this point in the course exercises, we have used a topic with the default six partitions. As you’ve learned through the course modules, though, partitions are useful in allowing you to break up your topic into manageable chunks that can be stored across multiple nodes in your cluster. Through this exercise, you’ll learn how to create topics with different partitions using the command line interface and see how varying topic partition counts affect the distribution of your data.
Again, we recommend following these exercises in order so that you have everything you need to complete the exercise. If you haven’t already set up your CLI to connect to your Confluent Cloud cluster, take a look at the earlier exercise to catch up.
- From a terminal window, list your topics.
confluent kafka topic listYou should see only the poems topic.
- Describe the topic to see more details into the topic and its configuration values.
confluent kafka topic describe poemsIn particular, make note of the num.partitions value, which is 6.
- Create two more topics with 1 and 4 partitions, respectively.
confluent kafka topic create --partitions 1 poems_1
confluent kafka topic create --partitions 4 poems_4- Produce data to the topics using the produce command and --parse-key flag.
confluent kafka topic produce poems_1 --parse-keyWhen prompted, enter the following strings:
1:”All that is gold does not glitter”
2:"Not all who wander are lost"
3:"The old that is strong does not wither"
4:"Deep roots are not harmed by the frost"
5:"From the ashes a fire shall awaken"
6:"A light from the shadows shall spring"
7:"Renewed shall be blad that was broken"
8:"The crownless again shall be king"-
Repeat step 4 for the poems_4 topic.
-
From the Confluent Cloud Console, view the newly produced messages in both topics. Note that the poems_1 topic has all eight messages in its single partition…
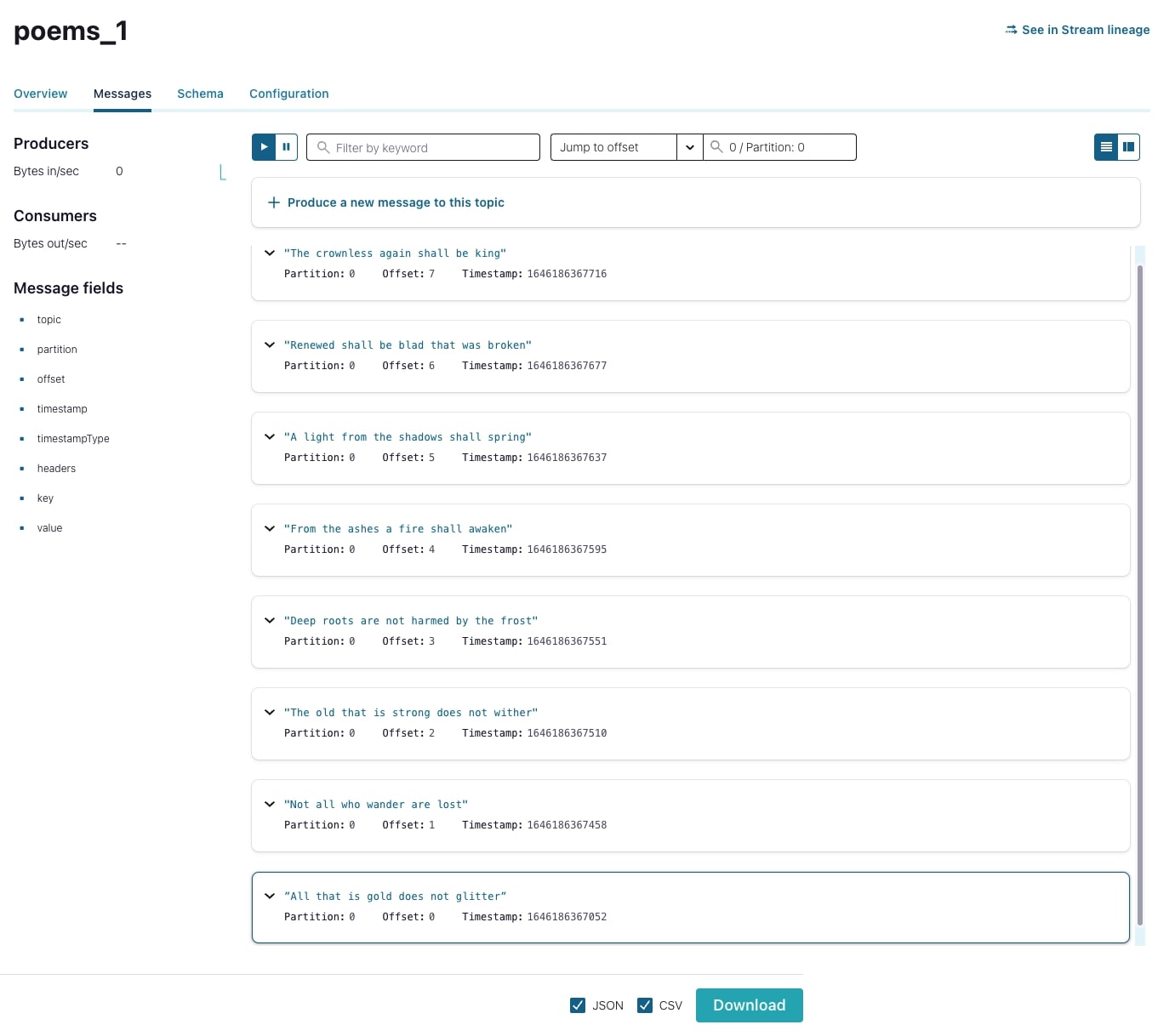

…while the poems_4 topic has a slightly different distribution.
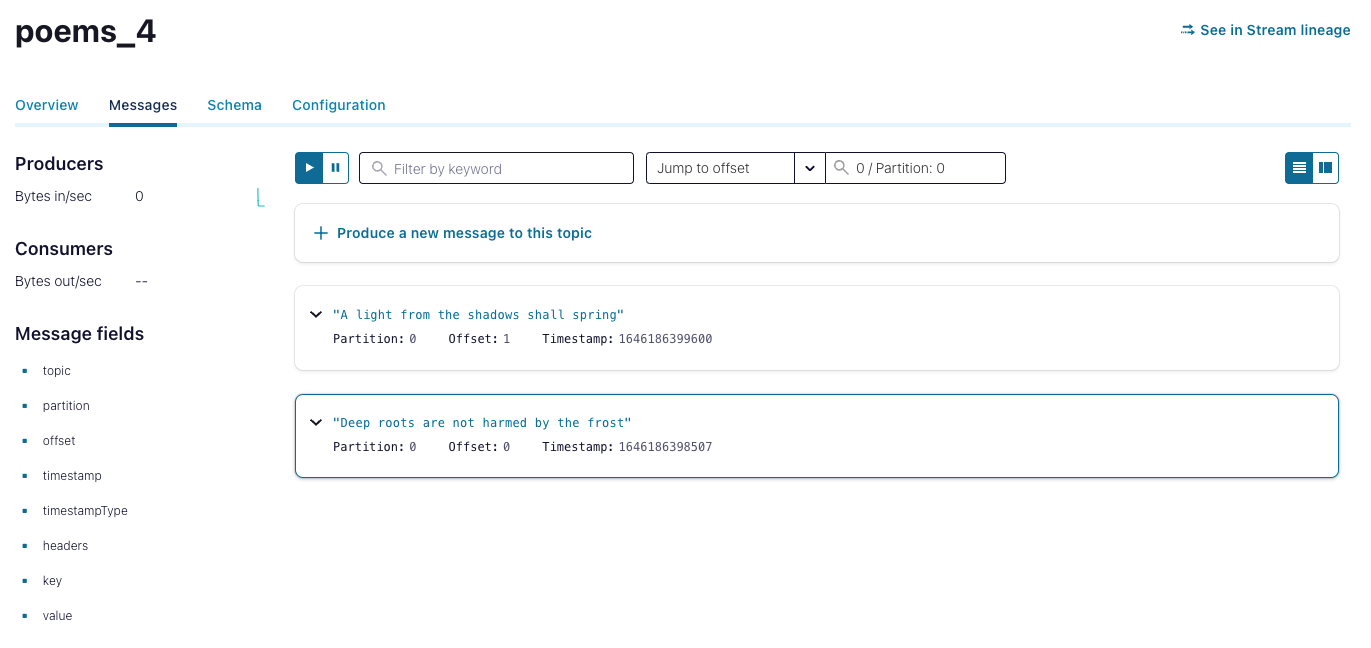
- Using the Jump to offset field, explore the partitions of all three topics—poems, poems_1, and poems_4—to observe how the messages are distributed differently across these topics.
This should have given you a good idea of how partitions will affect the distribution of data across your topic. The next time you create a topic, think about how many partitions you’ll need!
Use the promo codes KAFKA101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud storage and skip credit card entry.
Hands On: Partitioning
So up until this point, we've used a topic with the default of six partitions, but as you've learned through the course modules, partitions are useful in allowing you to break up your topic into more manageable chunks that can be stored across multiple nodes in your cluster. So through this exercise, you'll learn how to create topics with different partitions using the command line interface and we'll also see how varying topic partition counts can affect the distribution of your data. Let's get started. We recommend following these exercises in order so that you have everything you need to do the exercise. If you haven't already set up your CLI to connect to your Confluent Cloud cluster, take a look at earlier exercises to catch up. From your terminal, run Confluent Kafka topic list to see a list of topics in your cluster. So far, you should only see the poems topic. We can run a describe command on that topic to dive a little deeper and see its configuration values. Note that the num partition's value for this topic is six. Let's create two more topics called poems_1 and poems_4, which will have one and four partitions respectively. To do so, you can run the create topic command as shown. Remember to add the partition's config. Again, you can verify the partition count of both of these new topics by running the describe command. Now let's produce data to these topics using the same command from the last exercise. We'll write the same poem. Run the produce command and write the following messages. Do the same thing for the poems_4 topic. Going back to the Confluent Cloud web console, we can view these newly produced messages. Note that the poems_1 topic has all eight messages in its single partition. While the poems_4 topic has a slightly different distribution. Remember that when messages with keys are produced to Kafka, a hash is computed from the key and this result is used to determine the partition. We now have three topics, poems, poems_1, and poems_4, all containing the same eight messages. I encourage you to take some time on your own and see how the messages are distributed differently across these topics. This should've given you a pretty good idea of how partition counts can affect the distribution of data across your topics. So the next time you create a topic, think about how many partitions you'll need. See you in the next exercise where we'll continue exploring more Kafka features.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.