Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Hands On: Basic Operations



Sophie Blee-Goldman
Senior Software Engineer (Presenter)


Bill Bejeck
Integration Architect (Author)
Hands On: Basic Operations
The Basic Operations exercise demonstrates how to use Kafka Streams stateless operations such as filter and mapValues. Note that the next few steps, including setting up Confluent Cloud, creating the properties, adding the application ID, and creating the StreamsBuilder, apply to each exercise but will only be shown in this one.
-
Clone the course's GitHub repository and load it into your favorite IDE or editor.
git clone https://github.com/confluentinc/learn-kafka-courses.git -
Change to the directory.
cd learn-kafka-courses/kafka-streams -
Compile the source with ./gradlew build. The source code in this course is compatible with Java 11, and this module's code can be found in the source file java/io/confluent/developer/basic/BasicStreams.java.
-
Go to Confluent Cloud and use the promo code STREAMS101 for $25 of free usage (details). You can also use the promo code CONFLUENTDEV1 to delay entering a credit card for 30 days.
-
Create a new cluster in Confluent Cloud. For the purposes of all the exercise modules you can use the Basic type. Name the cluster kafka_streams_course. Note the associated costs, then click on the Launch Cluster button on the bottom right. (Make a mental note at this point to remember to shut down the cluster when you no longer need it; there are shutdown instructions at the end of the course).
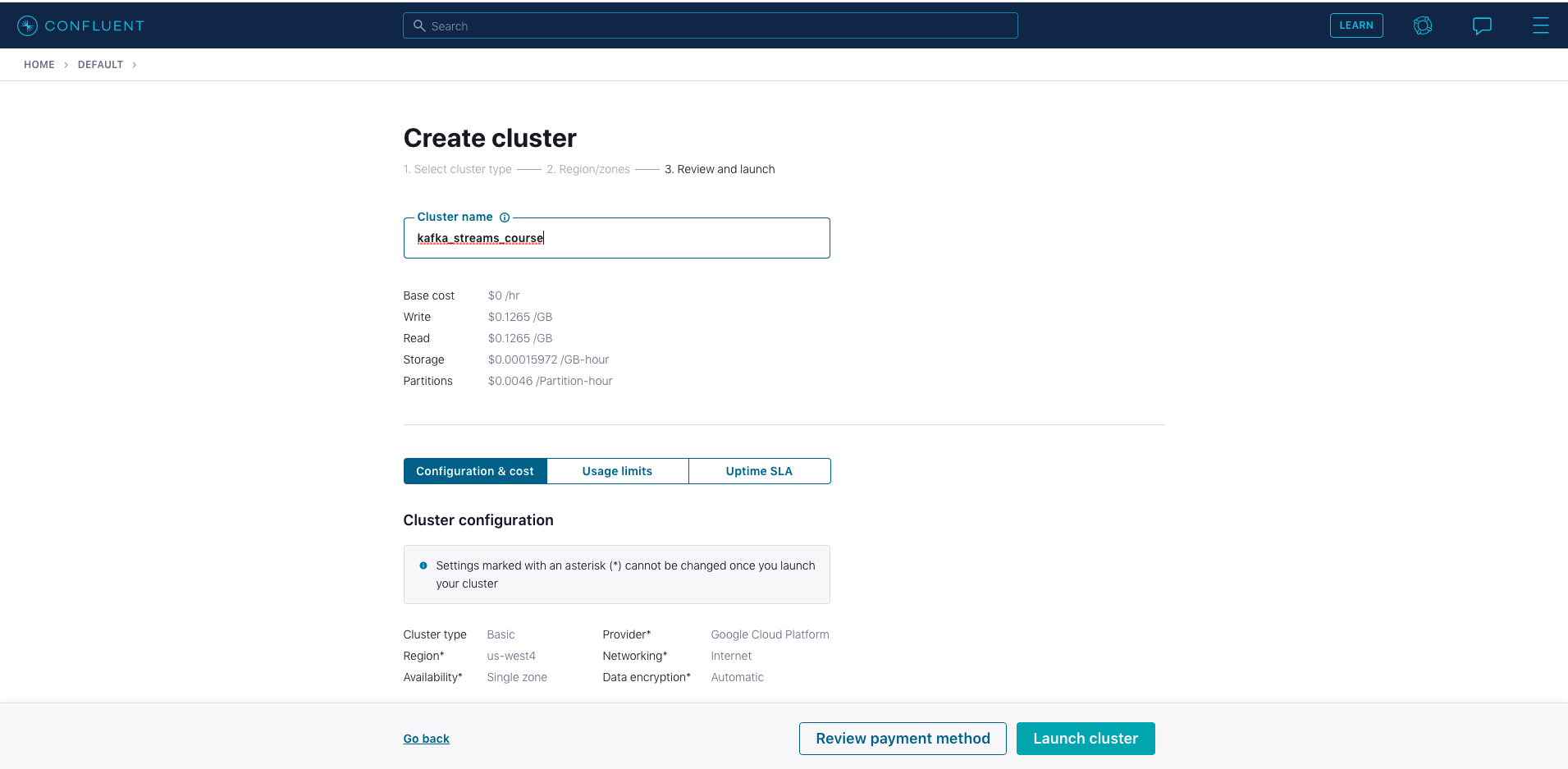
-
You’ll also need to set up a Schema Registry. Click on the environment link in the upper left corner (probably DEFAULT). Then click the Schema Registry link and follow the prompts to set up a schema registry on the provider of your choice. Once that is complete, go back to your cluster.

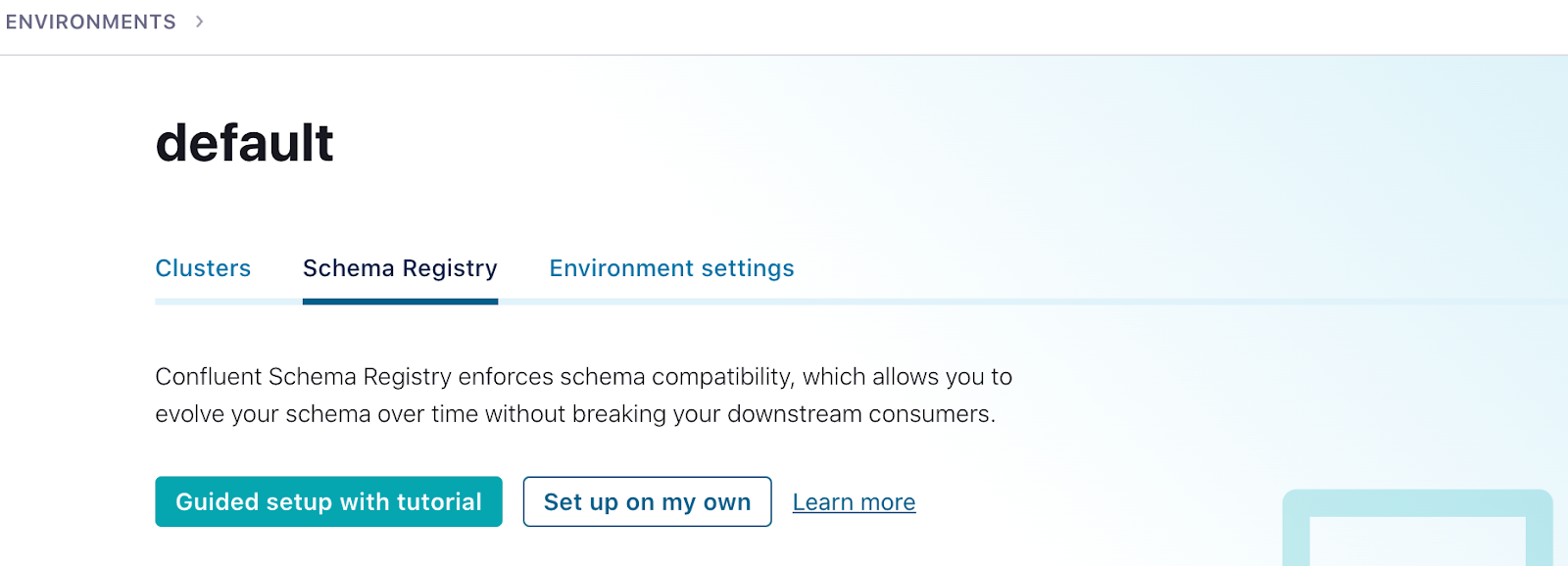
-
Next click on Data Integration in the menu on the left, then select Clients, then the Java tile.
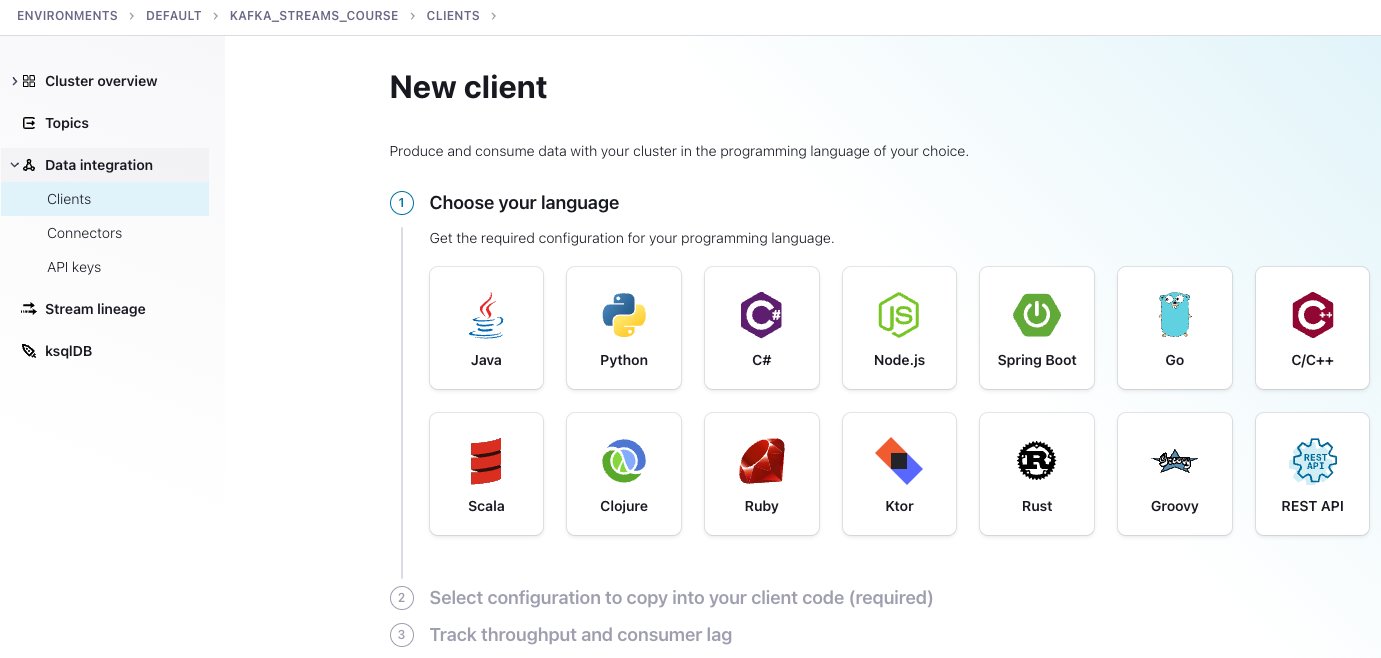
-
You'll be dropped down to a window where you can create credentials for your cluster and Confluent Schema Registry.
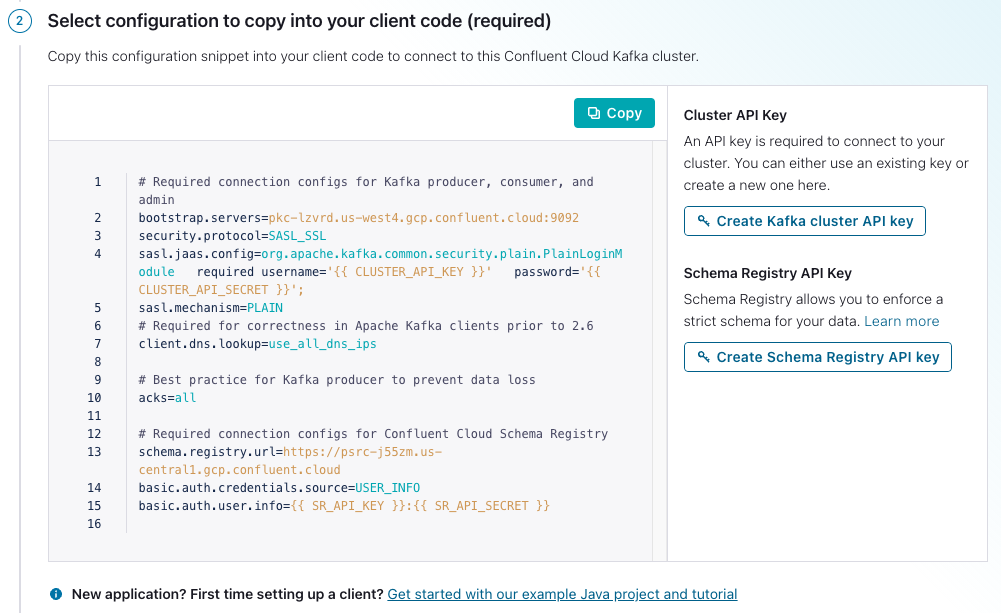
- Click on Create Kafka cluster API key.
- Copy your key and secret, name the file, then click Download and continue. (Your credentials will populate into the configurations boilerplate.)
- Click on Create Schema Registry API key.
- Copy your key and secret, name the file, then click Download and continue. (Your credentials will populate into the configurations boilerplate.)
- Make sure Show API keys is selected, then Copy the configurations in the window.
 6. Create a file named ccloud.properties in the src/main/resources directory of the repo you downloaded. Then paste the configurations into the ccloud.properties file. Note that this file is ignored and should never get checked into GitHub.
6. Create a file named ccloud.properties in the src/main/resources directory of the repo you downloaded. Then paste the configurations into the ccloud.properties file. Note that this file is ignored and should never get checked into GitHub. -
Now set up properties for the exercises (you are taking a couple of minor extra steps to make sure that any sensitive information doesn't get accidentally checked into GitHub). First make sure you are in src/main/resources. Then run the following commands:
- cat streams.properties.orig > streams.properties
- cat ccloud.properties >> streams.properties
-
Next, create a properties object in your BasicStreams.java file:
package io.confluent.developer.basic; import java.io.IOException; import java.util.Properties; public class BasicStreams { public static void main(String[] args) throws IOException { Properties streamsProps = new Properties(); } } -
Use a FileInputStream to load properties from the file that includes your Confluent Cloud properties; in addition, add the application configuration ID to the properties:
try (FileInputStream fis = new FileInputStream("src/main/resources/streams.properties")) { streamsProps.load(fis); } streamsProps.put(StreamsConfig.APPLICATION_ID_CONFIG, "basic-streams"); -
Create a StreamsBuilder instance, and retrieve the name of the inputTopic and outputTopic from the Properties:
StreamsBuilder builder = new StreamsBuilder() final String inputTopic = streamsProps.getProperty("basic.input.topic"); final String outputTopic = streamsProps.getProperty("basic.output.topic"); -
Create an order number variable (you'll see where it comes into play soon), and then create the KStream instance (note the use of the inputTopic variable):
final String orderNumberStart = "orderNumber-"; KStream<String, String> firstStream = builder.stream(inputTopic, Consumed.with(Serdes.String(), Serdes.String())); -
Add a peek operator (it's expected that you don't modify the keys and values). Here, it's printing records as they come into the topology:
firstStream.peek((key, value) -> System.out.println("Incoming record - key " +key +" value " + value)) -
Add a filter to drop records where the value doesn't contain an order number string:
.filter((key, value) -> value.contains(orderNumberStart)) -
Add a mapValues operation to extract the number after the dash:
.mapValues(value -> value.substring(value.indexOf("-") + 1)) -
Add another filter to drop records where the value is not greater than 1000:
.filter((key, value) -> Long.parseLong(value) > 1000) -
Add an additional peek method to display the transformed records:
.peek((key, value) -> System.out.println("Outgoing record - key " +key +" value " + value)) -
Add the to operator, the processor that writes records to a topic:
.to(outputTopic, Produced.with(Serdes.String(), Serdes.String())); -
Create the Kafka Streams instance:
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), streamsProps); -
Use the utility method TopicLoader.runProducer() to create the required topics on the cluster and produce some sample records (we’ll see this pattern throughout the exercises, but keep in mind that it's not part of a standard Kafka Streams application):
TopicLoader.runProducer(); -
Start the application:
kafkaStreams.start();


 6. Create a file named
6. Create a file named Now you can run the basic operations example with this command:
./gradlew runStreams -Pargs=basicand your output on the console should resemble this:
Incoming record - key order-key value orderNumber-1001
Outgoing record - key order-key value 1001
Incoming record - key order-key value orderNumber-5000
Outgoing record - key order-key value 5000Take note that it's expected to not have a corresponding output record for each input record due to the filters applied by the Kafka Steams application.
Use the promo code STREAMS101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Hands On: Basic Operations
This exercise will show basic Kafka Streams operations. The next few steps, creating the properties and adding the application ID, creating the streams builder are found in each exercise. So, we'll only cover them here and won't repeat them afterwards. First, you'll create a Properties object then you'll use this FileInputStream to load properties from a file that includes the confluent cloud properties that you created for working with the cluster. After that, make sure to add the application ID configuration to the properties. Now, you'll create the StreamsBuilder instance. Next, retrieve the name of the inputTopic from the properties. Note that Kafka Streams consumes from this topic and get the name of the outputTopic from the properties. This is the topic Kafka Streams writes its final output to. Next, create the orderNumber variable using the streams application. You'll see where it comes into play soon. And now create the KStream instance. You'll also want to note the use of the inputTopic variable. Now, add a peak operator. Note that it's expected that you don't modify the keys or values. Here, it's printing records as they come into the topology. Here, you'll add a filter to drop records where the value doesn't contain the orderNumber string, then add a mapValues operation, which extracts the number after the dash character. From there, add another filter to drop records where the value is not greater than 1,000 and add an additional peak method to display the transformed and filtered records. Add the to operator, the processor that writes the records to a topic, then create the KafkaStreams instance. Using the utility method, TopicLoader.runProducer, that creates the required topics on the cluster and produces some sample records. We'll see this pattern throughout the exercises. Keep in mind, it is not a standard part of a Kafka Streams application. Now, you can start the application.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.