Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Internals



Sophie Blee-Goldman
Senior Software Engineer (Presenter)


Bill Bejeck
Integration Architect (Author)
Internals
Tasks
Kafka Streams uses the concept of a task as a work unit. It's the smallest unit of work within a Kafka Streams application instance. The number of tasks is driven by the number of input partitions. For example, if you have a Kafka Streams application that only subscribes to one topic, and that topic has six partitions, your Kafka Streams application would have six tasks. But if you have multiple topics, the application takes the highest partition count among the topics.

Threads
Tasks are assigned to StreamThread(s) for execution. The default Kafka Streams application has one StreamThread. So if you have five tasks and one StreamThread, that StreamThread will work records for each task in turn. However, in Kafka Streams, you can have as many threads as there are tasks. So for five tasks, you could configure your application to have five threads. Each task gets its own thread, and any remaining threads are idle.
Instances
With respect to task assignment, application instances are similar to tasks. If you have an input topic with five partitions, you could spin up five Kafka Streams instances that all have the same application ID, and each application would be assigned and process one task. Spinning up new applications provides the same increase in throughput as increasing threads. Just like with threads, if you spin up more application instances than tasks, the extra instances will be idle, although available for failover. The advantage is that this behavior is dynamic; it doesn't involve shutting anything down. You can spin up instances on the fly, and you can take down instances.
Consumer Group Protocol
Because Kafka Streams uses a Kafka consumer internally, it inherits the dynamic scaling properties of the consumer group protocol. So when a member leaves the group, it reassigns resources to the other active members. When a new member joins the group, it pulls resources from the existing members and gives them to the new member. And as mentioned, this can be done at runtime, without shutting down any currently running applications.
So you should set up as many instances as you need until all of your tasks are accounted for. Then in times when traffic is reduced, you can take down instances and the resources will be automatically reassigned.
Use the promo code STREAMS101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Internals
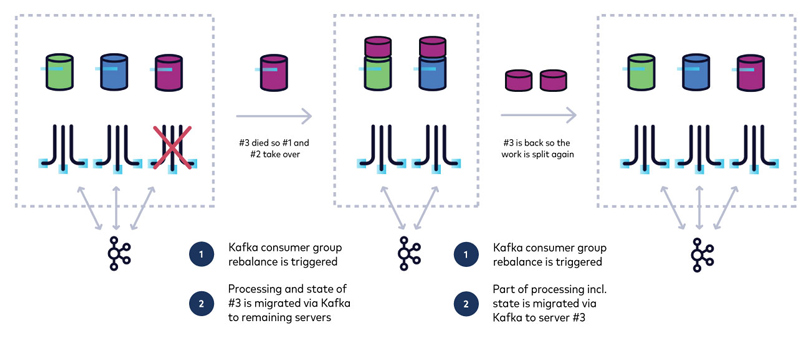
Hi, I'm Sophie Blee-Goldman with Confluent. In this module, we're going to talk about elasticity, scaling, and parallelism in Kafka Streams. So internally, Kafka Streams has this concept of a task or a stream task. And this is really the unit of work for the stream processing application. So the number of tasks is really driven by the number of input partitions, where Kafka Streams takes the highest partition count across all of the source topics, and that determines how many tasks there will be. So each task really corresponds to one or more partitions where there's only one partition per topic and more than one partition only if there is more than one topic for that particular task. So this is really the fundamental unit of work that actually does this processor topology and runs events through your application under the covers in Kafka Streams. Now Kafka Streams will assign these tasks to stream threads, which are just the threads that run these tasks. Each thread can be assigned one or more tasks and they will be iterated and processed together. Now the default number of threads is just one, but that's something you can control and is generally recommended to configure that based on your local machine. A good rule of thumb is to use around two times the number of cores for your number of stream threads. So that means that you can have as many threads as there are tasks in total. If you add more threads than that, they will be there, but they will just be sitting and doing nothing because there is no task to give to this thread to do work. And this applies whether you have multiple instances or not. You might have one instance of your application with eight threads and eight tasks, or you could have eight instances with one thread each, and they could process those eight tasks. Anything beyond that and it's just sitting idle, threads as well as the application instance itself. So it's a good idea to get a sense of how many tasks there are going to be when sizing up your Kafka Streams application. So how do you actually size up your Kafka Streams application? Well, if you increase the thread count, then this automatically increases the processing power that Kafka Streams has. So if you find that your thread is having trouble keeping up with the workload or the lag on the input topics, then you might want to increase your thread to spread those tasks across different threads so that they can process these tasks in parallel. Likewise, spinning up a new Kafka Streams instance with the same application ID is similar to adding a new thread. You can spin up a new application instance and those tasks will be redistributed across the instances, regardless of whether they are on the same node, on the same laptop, whatever that may be. Kafka Streams will distribute those tasks evenly across the instances and across the threads. So this is how Kafka Streams achieves parallelism. And note that in the case of instances, it can sometimes make sense to add another instance, even if it is going to be idle and have no tasks. Unlike with threads, in the case of an instance, this can be useful for fail over. Let's say you have two instances and a third one that's sitting idle. Well, if one of those first two instances crashes, then you can immediately start processing on the third one without waiting for the one that crashed to come back up. Now, since Kafka Streams uses the KafkaConsumer underneath the covers internally, it automatically inherits all of the powerful dynamic scaling properties of the KafkaConsumer and the consumer group protocol. A consumer group is really just a group of consumers, which share the same group ID. So it's analogous to the way that different Kafka Streams applications with the same application ID are all considered one application. And the reason they resemble each other is that Kafka Streams actually uses application ID as the consumer group ID. In that way Kafka Streams application is really just a consumer group. Now a consumer group is useful because it lets the broker dynamically redistribute the workload over only the current and active members. So if you have a member leave the group. For example, if you have a application node that dies, you no longer have it processing these partitions or these tasks, and you want somebody to take them over so that all of these topics and all of these partitions are actively being processed. Now, how does this work? Well when a member leaves the group in this way, a rebalance occurs. So a rebalance is just a fancy word for when all of the members of the consumer group, all of the Kafka Streams instances, all connect again to the broker and ask it for a new assignment, a new task assignment. The broker will then coordinate and assign those tasks to all of the active nodes. And this is the process that we call a rebalance. Now, when a new member joins the group another rebalance will be triggered, and this time instead of giving the resources or the partitions from the member that has left the group to existing members, the opposite happens where existing members will give partitions to the new member or the new Kafka Streams instance. And this is really how Kafka Streams gets its scalability. It lets you spin up and spin down Kafka Streams instances on the fly, and this can be done depending on workload or depending on availability. If you need more processing power, you can just spin up as many Kafka streams instances that you need, at least to the point where there's at least one task on all thread, and that way any new traffic that you get in cases of high workload is distributed across all of these new members, and you can hopefully handle the new workload more evenly. Now, after a spike in traffic, you then probably want to remove these Kafka Stream instances that you have brought up to handle the traffic spike. So in that case, all you need to do is spin down those instances, stop the process and all the resources, all of the tasks and partitions it was processing will be automatically assigned to the existing active applications. So as long as there is at least one Kafka Streams instance remaining, it will continue to process for that application. Now this behavior is completely dynamic. So the processing will continue maybe after a brief delay for the rebalance, but after that, you should see no disruption to your application. So that is what gives Kafka its elasticity, scaling, and parallelism.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.