Enhance your career, get Certified as a Data Streaming Engineer | Get Certified
Introduction to Designing Events and Event Streams



Adam Bellemare
Staff Technologist, Office of the CTO (Presenter)
What do distributed asynchronous computing, event-driven microservices, data in motion, and the modern data flow all have in common? They start with the event: a single piece of data that describes, as a snapshot in time, something important that happened.
But what is an event? What goes inside of it? How do you choose what to include, and what to avoid?
Properly designing your event and event streams is essential for any event-driven architecture. Precisely how you design and implement them will significantly affect not only what you can do today, but what you can do tomorrow. Unfortunately, many learning materials tend to gloss over event design, either assuming that you know how to do it or simply ignoring it all together.
But not us, and not here.
In this course, we’re going to put events and event streams front and center. We’re going to look at the dimensions of event and event stream design and how to apply them to real world problems. But dimensions and theory are nothing without best practices so we are going to also take a look at these to help keep you clear of pitfalls and set you up for success.
Let’s start with a bit of context to make sure we’re on the same page. There are two important questions we need to ask ourselves:
- How do people come to start using events?
- How should you think about events?
Connecting Existing Systems
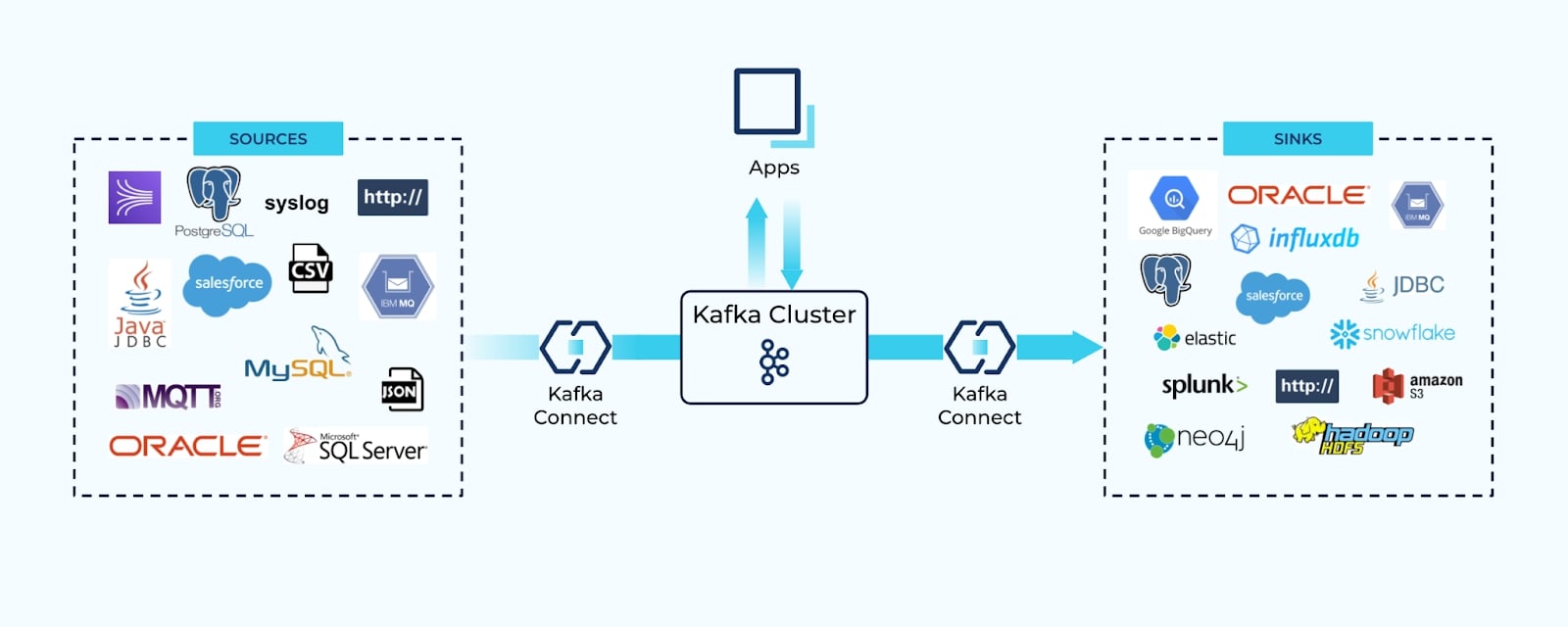
A common first step many businesses take is to connect their existing systems together—reading data from a source, and writing it to a sink. Connectors reduce the burden of writing custom business logic to get data into Kafka topics, where it can then circulate to the systems that need it most.
Connectors automatically convert extracted data into well-defined events that typically mirror the source schema. Consumers rely on these events for dual purposes:
- As a means of transferring state, and
- Reacting to specific changes in the source system.
While connectors are a common first use case, native event production by event-driven applications is a close second.
Native Production of Events
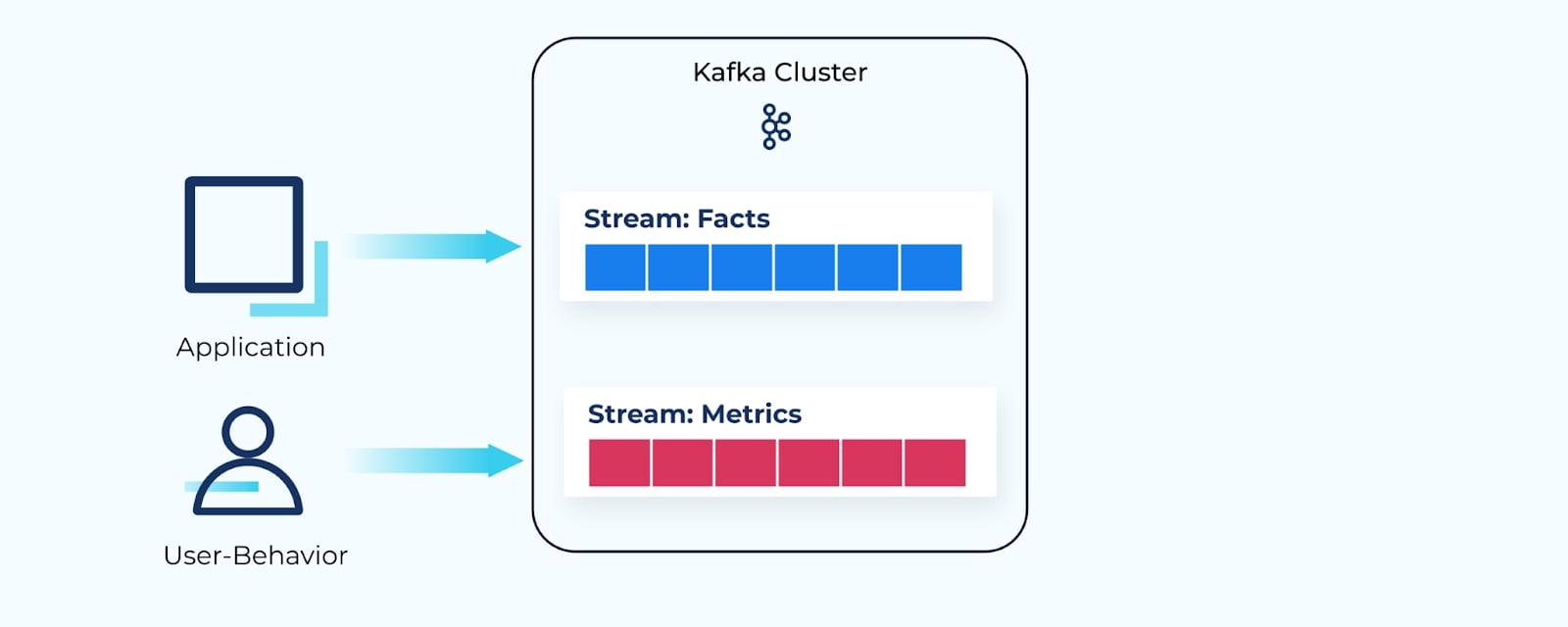
For example, an application may publish facts about business changes to its own event stream—details about a sale, about incoming inventory, or a flight ticket booking.
Similarly, a user's behavior may be recorded in a stream of events as they navigate through a website—products they’ve looked at and flight options they’ve clicked on.
Consumers Can Choose
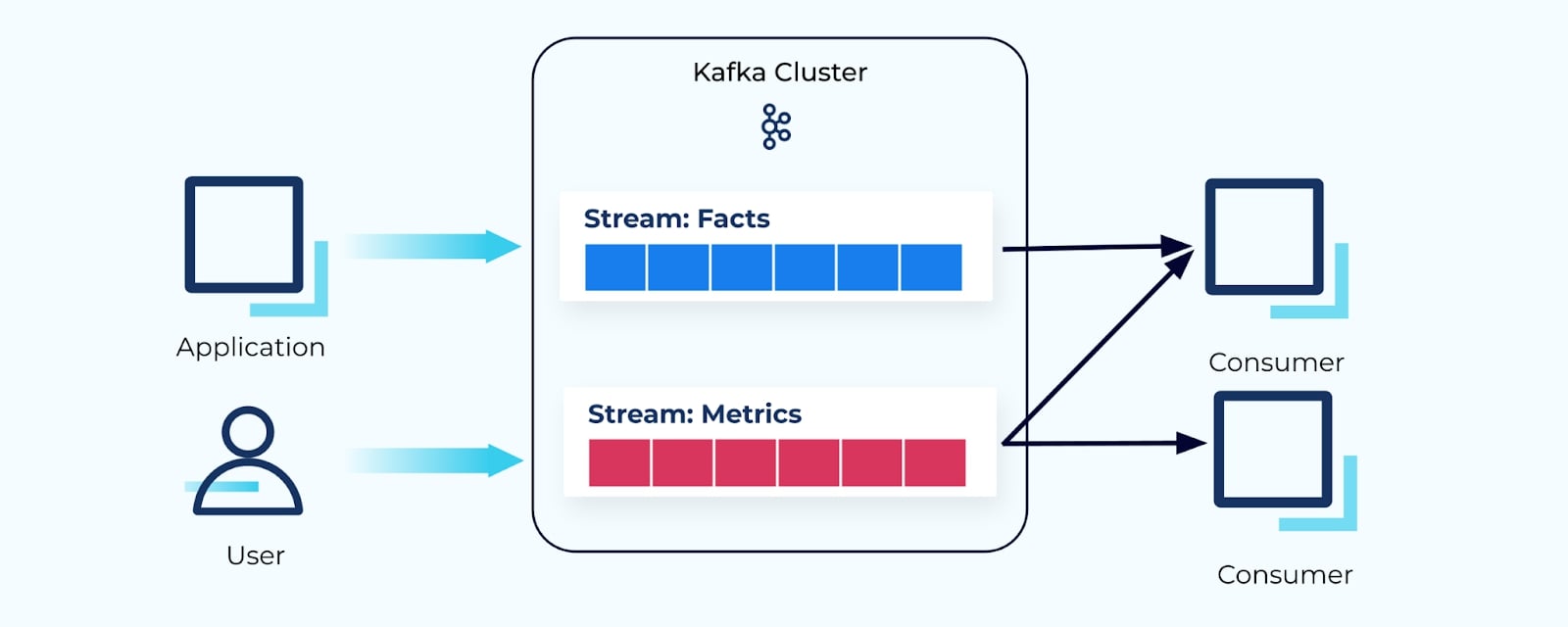
Event streams can also be natively consumed by whichever consumer services need the events. Stream processor frameworks like ksqlDB and Kafka Streams step in as a great choice for building event-driven consumer applications.
What Are Events?

First and foremost, events provide a record of something that has happened in the business. These business occurrences are modeled as individual events, and record all the important business details about what happened and why.
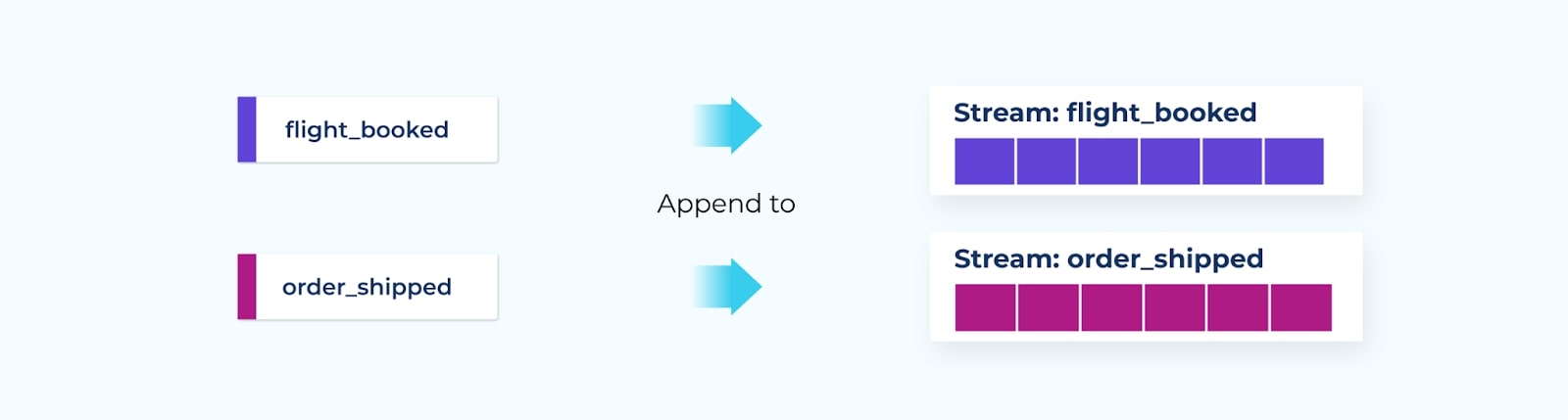
Events are named based on past-tense terminology. For example, booking a flight may result in a flight_booked event, while the completion of an e-commerce order may result in an order_shipped event.
Once an event is recorded, they are written into an event stream.
- Both events and event streams are completely immutable—once published, you can’t change their contents, nor can you change their order in the stream.
- Many different consumers can use the events, however they choose, within their business logic.
- Consumers may choose to ignore events within the consumed event stream, but they undeniably occurred.
- The events are durable and replayable—they stick around as long as they’re needed.
A log of events in a stream can be used to construct a detailed picture of the system over time, rather than just as a snapshot of the present.
But what do you put into an event?
Some of the initial questions you need to ask yourself are: Who is the intended user of the data? Is this an event made for your own internal usage? Or are you looking to share it across your boundary to others?
Start with the Boundaries
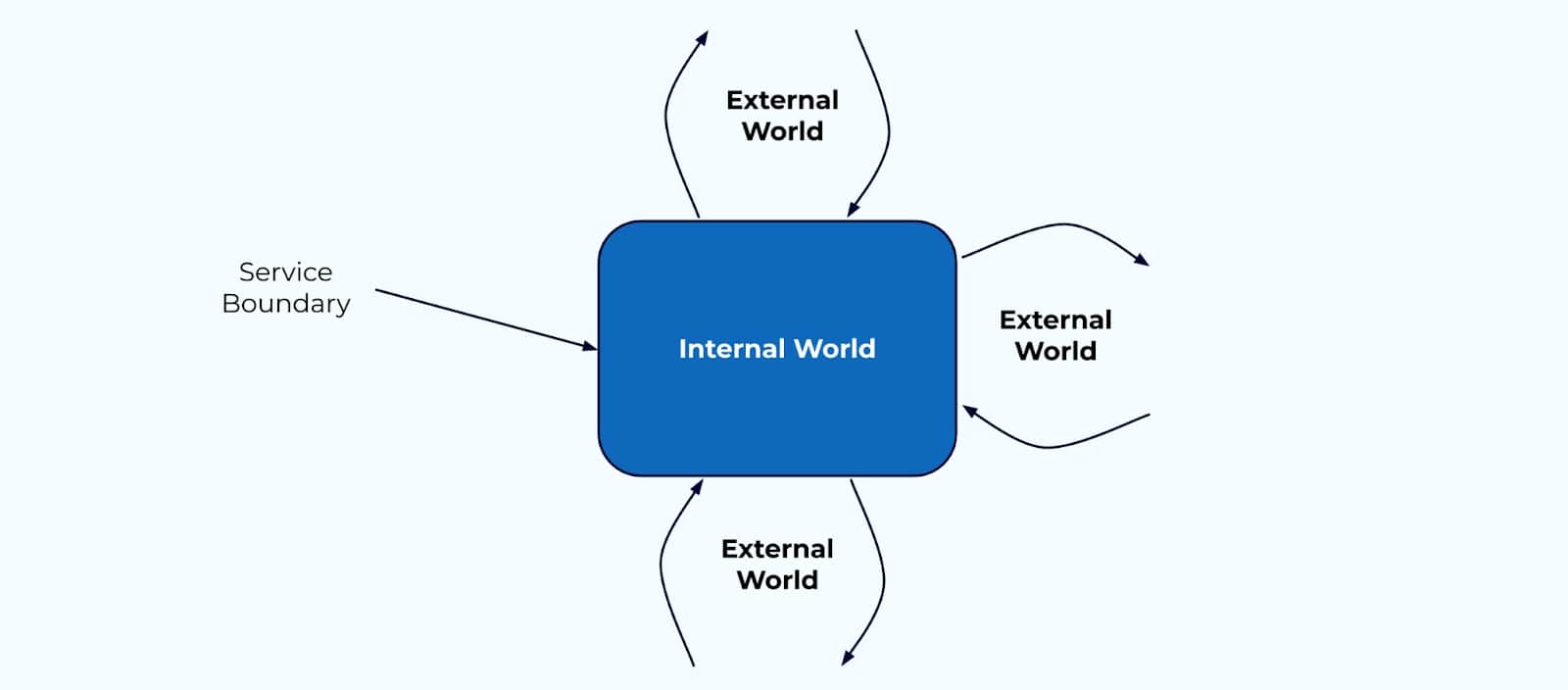
It’s useful to start thinking about the boundaries of your systems. Any given service has its own service boundary—a division between where the internal world transitions to the external world, where encapsulation of data models and business logic give way to APIs, event streams, and remote procedure calls.
In the world of domain-driven design, the boundary between the internal and external world is known as a “bounded context.”
The Internal World
Let’s take a closer look at what the internal world can look like in practice.
Data on the Inside
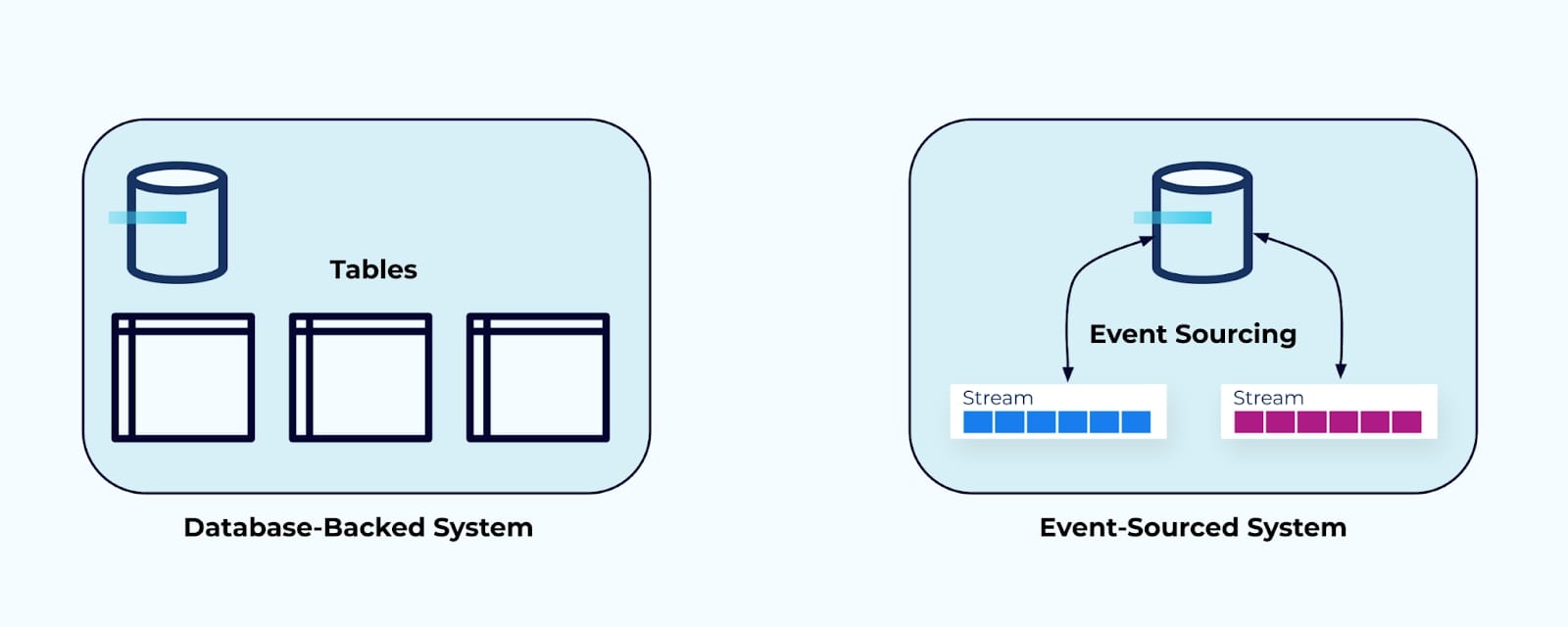
Here are two examples of possible “internal worlds.”
On the left is a typical relational-database backed system—data is stored in database tables, modeled according to the application’s needs and use cases. This data is intended to power the regular application operations.
On the right, is an application powered by event sourcing—the internal event streams record the modifications to the domain that when merged together form the current state of the system.
Data on the inside is private, and is meant specifically for use inside the system. It is modeled according to the needs of its service. It is not meant for general use by other systems and teams.
The External World
Now, let’s take a look at the external world, and most importantly, the data that crosses the boundaries from the external to the internal.
Data on the Outside
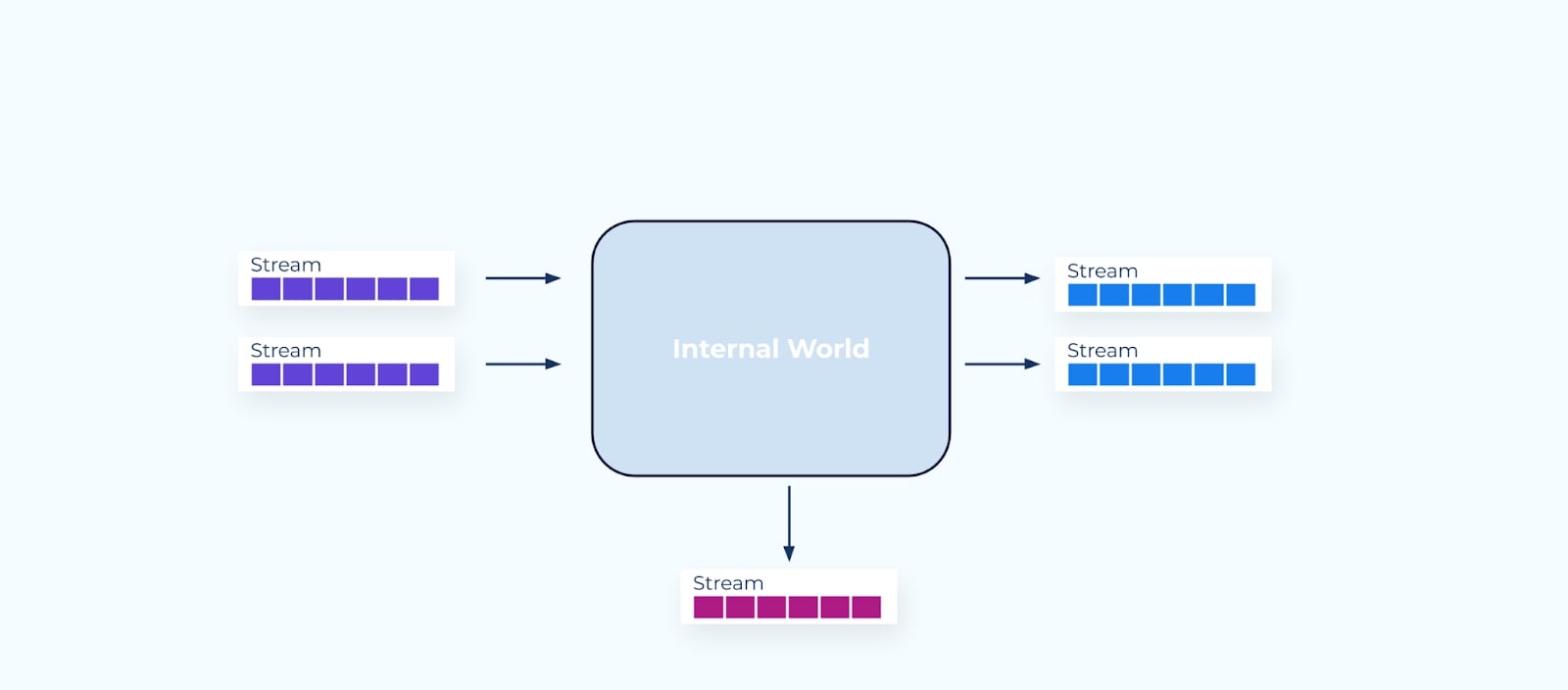
Data on the outside is composed of sources that have deliberately been made available for others to use and consume. In this case, as events served through event streams.
In contrast to internal world data, data on the outside is purpose-built, as a first-class citizen, to share with other services and teams.
There are several questions that you need to ask yourself for designing data on the outside:
- How will others use the events?
- Do the events describe changes, or do they describe snapshots of state?
- Are the events denormalized, or do they need to be joined against other sources of data?
Events as Data Transfer Objects
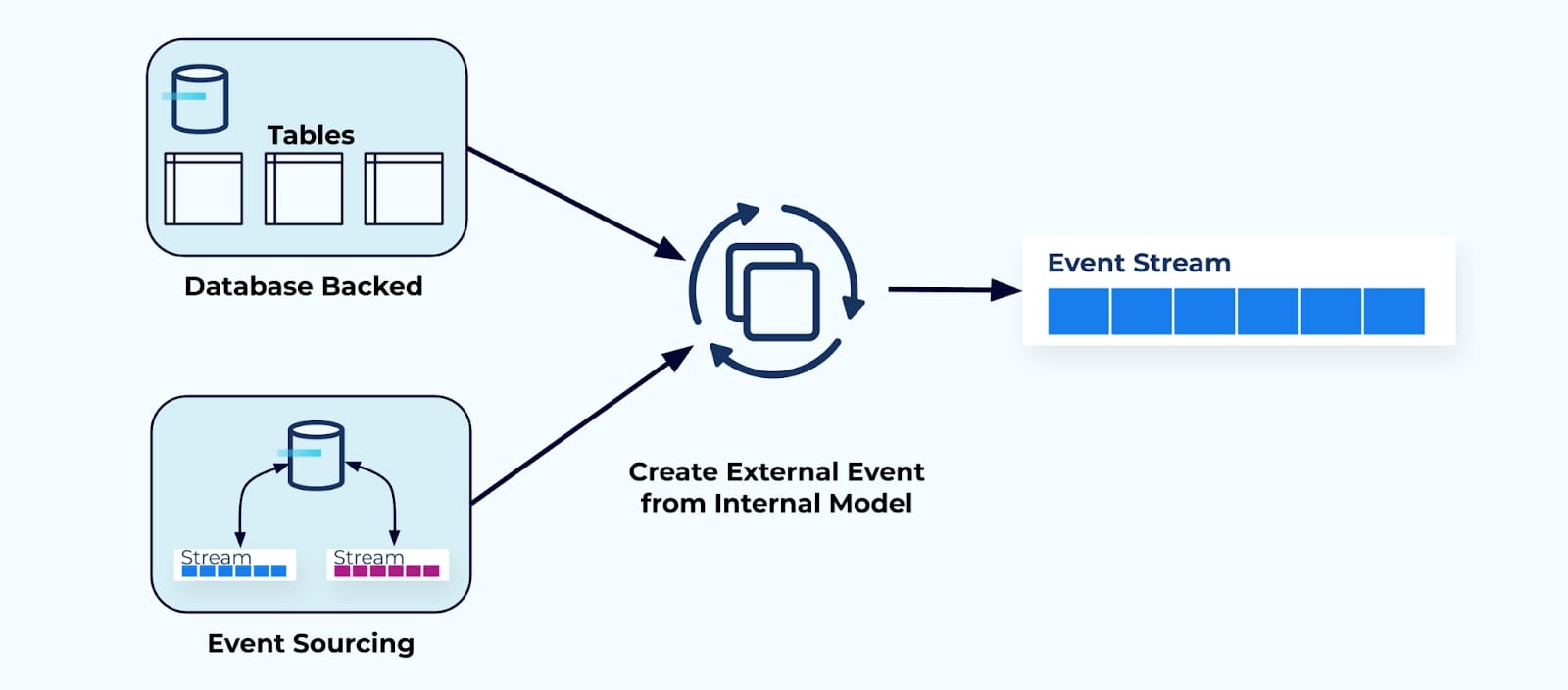
One way to think about data on the outside is to picture the event as a data transfer object. A data transfer object is an encapsulated object that contains data purpose-built for communication to a process or system on the outside.
Data on the inside tends to be more fluid and can change more frequently depending on business requirements. Data on the outside ideally won't change too often because that creates more volatility in the system and may require more extensive changes by downstream consumers.
One challenge of designing events is determining what that data transfer object should contain. Another challenge is creating the code and processes that take data from the inside, and convert it into a format that is suitable for use on the outside.
Precisely how you model data on the outside can be a bit complicated, but we get into the thick of it in the upcoming modules.
The Four Dimensions of Event Design
To start, we look at four important dimensions to consider when you design your events.
- Facts vs. delta events pertains to the event structure—the recording of a whole fact versus just the fields that have changed.
- Normalization vs. denormalization pertains to choices around event relationships, and the trade-offs between normalized and denormalized event streams.
- Single vs. multiple event types per topic focuses on the trade-offs between many topics with single event types, and a single topic containing multiple event types.
- Discrete vs. continuous event flows covers the relationships between events and their usage through workflows.
We also go through some hands-on exercises focused on showcasing how these dimensions work in practice.
Following the four dimensions, we look at a series of modules focused on event design best practices, including everything from schemas, to naming, to IDs, and more.
Confluent Cloud Setup
This course introduces you to designing events and event streams through hands-on exercises using Confluent Cloud and ksqlDB. If you haven’t already signed up for Confluent Cloud, sign up now so when your first exercise asks you to log in, you are ready to do so.
- Browse to the sign-up page: https://www.confluent.io/confluent-cloud/tryfree/ and fill in your contact information and a password. Then click the START FREE button and wait for a verification email.
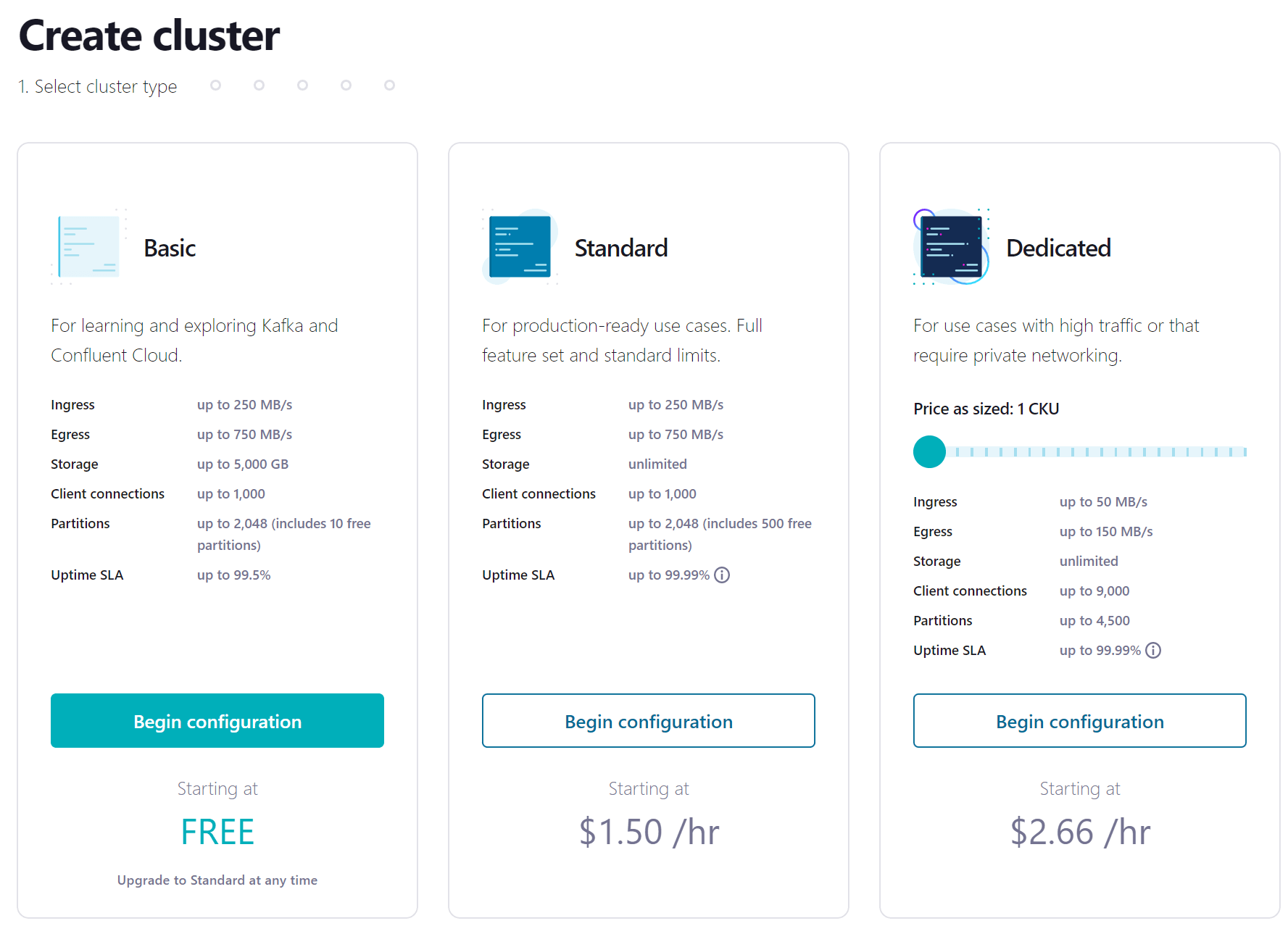
- Click the link in the confirmation email and then follow the prompts (or skip) until you get to the Create cluster page. Here you can see the different types of clusters that are available, along with their costs. For this course, the Basic cluster will be sufficient and will maximize your free usage credits. After selecting Basic, click the Begin configuration button.
- Choose your preferred cloud provider and region, and click Continue.
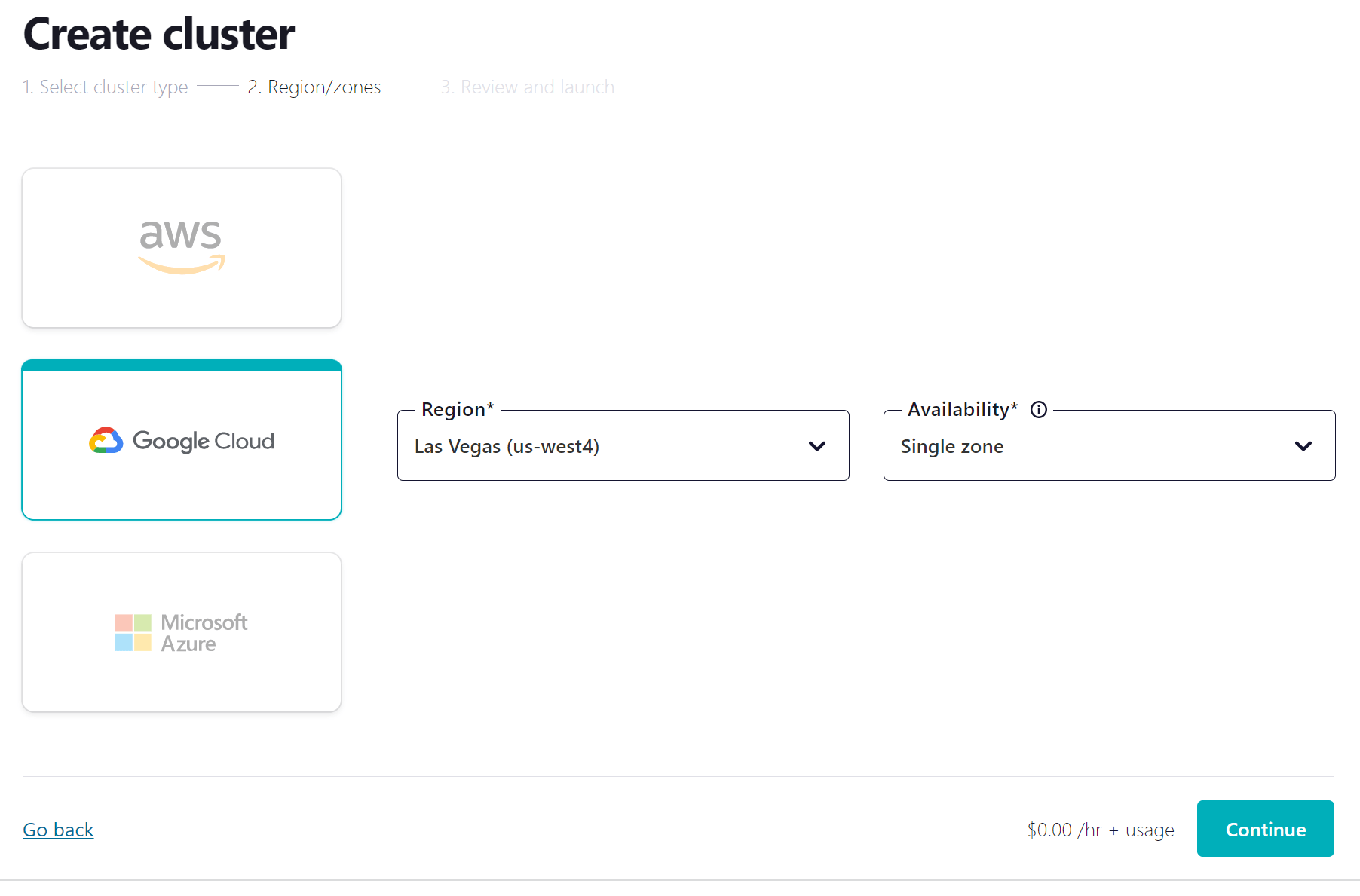
-
Review your selections, give your cluster a name, and click Launch cluster. This might take a few minutes.
-
While you’re waiting for your cluster to be provisioned, be sure to add the promo code EVENTDESIGN101 to get an additional $25 of free usage (details). From the menu in the top-right corner, choose Administration | Billing & Payments, then click on the Payment details tab. From there click on the +Promo code link, and enter the code.
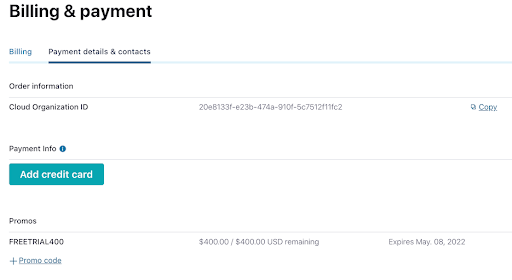
You’re now ready to complete the upcoming exercises as well as take advantage of all that Confluent Cloud has to offer!
- Previous
- Next
Use the promo code EVENTDESIGN101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Introduction to Designing Events and Event Streams
Hi, I'm Adam from Confluent, and today I'll be talking to you about events and event streams. What does distributed asynchronous computing, event driven microservices, data in motion, and the modern data flow all have in common? They start with the event. An event is a single piece of data that describes, as a snapshot in time, something important that happened. But what is an event and what goes inside of it? How do you choose what to include and what you should avoid? Properly designing your event and event streams is essential for any event driven architecture. Precisely how you design and implement them will significantly affect not only what you can do today, but what you can do tomorrow. Now, you may have found that many learning materials tend to gloss over event design, either leaving it as a foregone conclusion that of course you know how to do this, or simply ignoring it all together. But not us and not here. In this course we're going to put events and streams front and center. We're going to look at the dimensions of event and event stream design, and how to apply them to real world problems. But dimensions in theory are nothing without best practices, so we're going to also take a look at these best practices to keep you clear of pitfalls and set you up for success. Now, before we get too far ahead of ourselves let's start with a bit of context to make sure that we're on the same page. There are two important questions we need to ask ourselves. Why do people start using events, and how should we think about them? One of the most common first steps that many businesses take is when connecting existing systems together, reading data from a source and writing it to a sync. Connectors reduce the burden of writing custom business logic to get data into Kafka topics where it can then circulate to the systems that need it most. Consumers rely on these events primarily for two main purposes, one as a means of transferring state, and two, for reacting to specific changes in the source system. And while connectors are a common first use case, native event production by event driven applications is another. For example, an application may publish facts about business changes to its own event stream, details about a sale, about incoming inventory, or a flight ticket booking. Similarly, a user's behavior may also be recorded in a stream of events as they navigate through a website, products that they've looked at, and flight options that they've clicked on. Similarly, a user's behavior may be recorded in a stream of events as they navigate through a website, products that they've looked at, and flight options that they've clicked on. Consumers can choose which events streams they subscribe to and decide for themselves what they want to do with that data. Stream processor frameworks like ksqlDB and Kafka Streams provide powerful options for building event driven applications to put these events to good use. So while we know a little bit about how we use events, what is an event? Well, first and foremost, events provide a record of something that has happened in the business. These business occurrences record all of the important business details about what happened and why. We name the events based on past tense terminology. For example, booking a flight may result in a flight_booked event, while the completion of an eCommerce order may result in an order_shipped event. Once we record them, we write them into an event stream. A stream of events can be used to construct a detailed picture of the system over time, rather than just a snapshot of the present state. Both events and event streams are completely immutable. Once published you can't change their contents, nor can you change their order in the stream. As we alluded to before, multiple consumers can, of course, use them however they choose. Events are durable and repeatable. They stick around in the stream for as long as they're needed and are only deleted when they are no longer needed by the business. But what do you put into an event? One of the first big questions you need to ask yourself is who is the intended user of the data? Is this an event made for your own internal usage? Or are you looking to share it across your service boundary to others in your organization? Let's start with boundaries. Any given service has its own service boundary, a division between where the internal world transitions to the external world, where the encapsulation of data models and business logic give way to APIs, event streams, and remote procedure calls. In the world of domain driven design, the boundary between the internal and the external world is known as a bounded context. Let's take a closer look at what this internal world can look like in practice. Here are two examples of possible internal worlds. On one side we have a typical relational database backed system. Data is stored in database tables modeled according to the applications needs and use cases. This data is intended to power the regular application operations. On the other side, we have an application powered by event sourcing, the internal event streams record the modifications to the domain that, when merged together, form the current state of the system. Data on the inside is private and meant specifically for use inside the system. It is modeled according to the needs of the service. It is not meant for general usage by other systems and teams. But what about the external world? Let's take a look now. This is the data that crosses the boundaries both into and out of the internal world. I like to call this data on the outside. Data on the outside is composed of sources that have deliberately been made available for others to use and consume, in this case as events served through event streams. In contrast to internal world data, data on the outside is purpose-built as a first class citizen to share with others. There are several questions that you'll need to ask yourself when designing data on the outside. How will others use the events? Do the events describe changes, or do they describe snapshots of state? Are the events denormalized, or do they need to be joined against other sources of data? We're going to cover these precise questions in each of the following modules. One way to think about data on the outside is to picture the event as a data transfer object, an encapsulated object that contains data purpose built for inter-process communication. Data on the inside tends to be more fluid and can change more frequently depending on business requirements. Data on the outside ideally won't change too often, because that creates more volatility in the system and will require more extensive changes by downstream consumers. One challenge of designing events is determining what the data transfer object should contain. Another challenge is creating the code and processes that take data from the inside and convert it into a format that is suitable for use on the outside. Data on the inside and data on the outside, this is one of the key components that you'll need to think about when designing your events and your streams as it will help you guide your decision making. We'll be revisiting this concept throughout the course. In the following modules we'll be going into the four main dimensions of event design, mixing in some hands on exercises, and capping it off with a series of best practices. The first dimension, Facts versus Delta events, pertains to the event structure, the recording of a whole fact versus just the fields that have changed. The second dimension, Normalization versus Denormalization, pertains to choices around event relationships and the trade-offs between normalizing and denormalizing the event streams. The third dimension, Single versus Multiple Event Types per Topic, focuses on the trade-offs between many topics with single event types and a single topic containing multiple event types. And finally, the fourth dimension is Discrete versus Continuous Event Flows, and it covers the relationship between events and their intended usage by consumers. Now let's get you set up for the hands-on exercises that we'll be covering in this course. These exercises rely on Confluent Cloud. We'll be using Apache Kafka, ksqlDB, and the Schema Registry to apply the lessons to some practical scenarios. My colleague Danica Fine will now take you through setting up your free Confluent Cloud account. I'll see you back here in the next module. If you haven't already signed up for Confluent Cloud sign up now so that when the first exercise asks you to log in you're already ready to do so. Be sure to use the promo code when signing up. First off, you'll want to follow the URL on the screen. On the signup page, enter your name, email, and password. Be sure to remember these sign-in details as you'll need them to access your account later. Click the start free button, and wait to receive a confirmation email in your inbox. The link in the confirmation email will lead you to the next step where you'll be prompted to set up your cluster. You can choose between a basic, standard, or dedicated cluster. Basic and standard clusters are serverless offerings where your free Confluent Cloud usage is only exhausted based on what you use, perfect for what we we need today. For the exercises in this course we'll choose the basic cluster. Usage costs will vary with any of these choices, but they are clearly shown at the bottom of the screen. That being said, once we wrap up these exercises don't forget to stop and delete any resources that you created to avoid exhausting your free usage. Click review to get one last look at the choices you've made and give your cluster a name, then launch. It may take a few minutes for your cluster to be provisioned. And that's it. You'll receive an email once your cluster is fully provisioned. But in the meantime, let's go ahead and leverage that promo code that we saw earlier. From settings choose billing and payment. You'll see here that you have $400 of free Confluent Cloud usage, but if you select the payment details and contacts tab, you can either add a credit card or choose to enter a promo code. And with that done, you're ready to dive in.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.