Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Getting Started with Kafka Streams



Sophie Blee-Goldman
Senior Software Engineer (Presenter)


Bill Bejeck
Integration Architect (Author)
Getting Started
To understand Kafka Streams, you need to begin with Apache Kafka—a distributed, scalable, elastic, and fault-tolerant event-streaming platform.
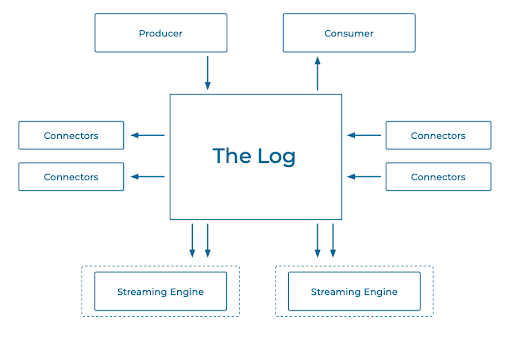
Logs, Brokers, and Topics
At the heart of Kafka is the log, which is simply a file where records are appended. The log is immutable, but you usually can't store an infinite amount of data, so you can configure how long your records live.
The storage layer for Kafka is called a broker, and the log resides on the broker's filesystem. A topic is simply a logical construct that names the log—it's effectively a directory within the broker's filesystem.
Getting Records into and out of Brokers: Producers and Consumers
You put data into Kafka with producers and get it out with consumers: Producers send a produce request with records to the log, and each record, as it arrives, is given a special number called an offset, which is just the logical position of that record in the log. Consumers send a fetch request to read records, and they use the offsets to bookmark, like placeholders. For example, a consumer will read up to offset number 5, and when it comes back, it will start reading at offset number 6. Consumers are organized into groups, with partition data distributed among the members of the group.
Connectors
Connectors are an abstraction over producers and consumers. Perhaps you need to export database records to Kafka. You configure a source connector to listen to certain database tables, and as records come in, the connector pulls them out and sends them to Kafka. Sink connectors do the opposite: If you want to write records to an external store such as MongoDB, for example, a sink connector reads records from a topic as they come in and forwards them to your MongoDB instance.
Streaming Engine
Now that you are familiar with Kafka's logs, topics, brokers, connectors, and how its producers and consumers work, it's time to move on to its stream processing component. Kafka Streams is an abstraction over producers and consumers that lets you ignore low-level details and focus on processing your Kafka data. Since it's declarative, processing code written in Kafka Streams is far more concise than the same code would be if written using the low-level Kafka clients.
Kafka Streams is a Java library: You write your code, create a JAR file, and then start your standalone application that streams records to and from Kafka (it doesn't run on the same node as the broker). You can run Kafka Streams on anything from a laptop all the way up to a large server.
Say you have sensors on a production line, and you want to get a readout of what's happening, so you begin to work with the sensors' data. You need to pay special attention to the temperature (whether it’s too high or too low) and the weight (are they making it the right size?). You might stream records like the example below into a Kafka topic:
{
"reading_ts": "2020-02-14T12:19:27Z",
"sensor_id": "aa-101",
"production_line": "w01",
"widget_type": "acme94",
"temp_celsius": 23,
"widget_weight_g": 100
}You can then use the topic in all sorts of ways. Consumers in different consumer groups have nothing to do with each other, so you would be able to subscribe to the topic with many different services and potentially generate alerts.
Processing Data: Vanilla Kafka vs. Kafka Streams
As mentioned, processing code written in Kafka Streams is far more concise than the same code would be if written using the low-level Kafka clients. One way to examine their approaches for interacting with the log is to compare their corresponding APIs. In the code below, you create a producer and consumer, and then subscribe to the single topic widgets. Then you poll() your records, and the ConsumerRecords collection is returned. You loop over the records and pull out values, filtering out the ones that are red. Then you take the "red" records, create a new ProducerRecord for each one, and write those out to the widgets-red topic. Once you write those records out, you can have any number of different consumers.
public static void main(String[] args) {
try(Consumer<String, Widget> consumer = new KafkaConsumer<>(consumerProperties());
Producer<String, Widget> producer = new KafkaProducer<>(producerProperties())) {
consumer.subscribe(Collections.singletonList("widgets"));
while (true) {
ConsumerRecords<String, Widget> records = consumer.poll(Duration.ofSeconds(5));
for (ConsumerRecord<String, Widget> record : records) {
Widget widget = record.value();
if (widget.getColour().equals("red") {
ProducerRecord<String, Widget> producerRecord = new ProducerRecord<>("widgets-red", record.key(), widget);
producer.send(producerRecord, (metadata, exception)-> {…….} );
…Here is the code to do the same thing in Kafka Streams:
final StreamsBuilder builder = new StreamsBuilder();
builder.stream(“widgets”, Consumed.with(stringSerde, widgetsSerde))
.filter((key, widget) -> widget.getColour.equals("red"))
.to("widgets-red", Produced.with(stringSerde, widgetsSerde));You instantiate a StreamsBuilder, then you create a stream based off of a topic and give it a SerDes. Then you filter the records and write back out to the widgets-red topic.
With Kafka Streams, you state what you want to do, rather than how to do it. This is far more declarative than the vanilla Kafka example.
Errata
- The Confluent Cloud signup process illustrated in this video includes a step to enter payment details. This requirement has been eliminated since the video was recorded. You can now sign up without entering any payment information.
- Previous
- Next
Use the promo code STREAMS101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Getting Started with Kafka Streams
Hi, I'm Sophie Blee-Goldman with Confluent. Let's get started learning Kafka Streams. So before we get into what is Kafka Streams, let's take a step back and talk about what is Apache Kafka. Apache Kafka is an event streaming platform, it's distributed, so it's scalable and elastic and it's fault tolerant. And the fault tolerance property is gained by nature of being distributed. And by replicating the data across the storage nodes. So the storage nodes in Kafka are called Brokers and these storage nodes are just an instance of the Kafka Storage Layer Process running on your server or your laptop, whatever that may be. Now, at the heart of each Broker is this concept of a Log. It's not really the Log that most application developers might think of. This Log is a file and it's a special kind of file. It's a file that holds records or events. These Logs are append only. So as these events come in, they get appended to the end of the Log. And at that point they become immutable. So once immutable, that means they can't be changed, they can't be updated and they don't go away. So this means that unlike some of the message queuing systems, you might be familiar with, Kafka records will be stored forever and they won't disappear as soon as they are consumed like a typical message queue. Now you don't really want to be storing infinite data though you can with some of the tiered storage features you don't always want to, and you can always care about data past a certain point. So Kafka lets you configure a retention on the Logs that are stored by Kafka. It can be in terms of a size, like a certain number of gigabytes for your dataset or in terms of time. Like you don't want to keep records past seven days, which is the default in Kafka. So in Kafka you can set this retention time for each topic specifically. Now topic is really kind of the manifestation of a Log and Kafka, a topic is a logical grouping of events, usually some relation to each other. So you might have a Kafka of customer purchase events or user addresses. Usually it's going to be something that relates to one another in some logical way. And the topic itself really is just a name that is given to the Log. So on the broker, they store each log and directory names by that topic. Now you have your data in Kafka on these Brokers, and now you might be wondering how do you get it in there and how do you get it out? And how do you do something with it? Data is not really any good to you if it's just sitting there on a node. Well, Kafka has a producer and consumer client API, and that is used to do both of these things. The producer client is responsible for getting the data into Kafka. The producer client will send a produce or a send request along with the batch of records and the name of the topic that these records should go into. Now, once these records get appended to a topic, they are going to be appended at a certain position in said topic. And this position is what's known an Offset in Kafka. Now the consumer can use this offset to specify where in the log it would like to start consuming from. So a consumer will send a fetch request. And along with the name of the topic that it would like to consume records from, and potentially an offset that it has started reading from. So this could be the zero offset at the very beginning of the Log, or I could say I only care about records starting from at the time that I'm consuming and only send me new records or it can subscribe to the Log at any position in between using the Offset. So the Offset really identify as a record and it's positioned inside the Log. Now a lot of the time you're going to be doing nothing but producing and consuming from the Log. This is a pretty common pattern where you have your data in a database somewhere, or you have your application events coming in and you really just want to get them either to Kafka or out of Kafka, as you are attaching different things and streaming your events through Kafka. So for this, you can use the the producer client API, but you would end up writing a lot of common and boilerplate code to do so as you would just be sending the records and receiving them. Now, of course, Kafka makes this easy for you as well. Kafka provides what is called Kafka Connect, which is really just a framework that does all that boilerplate code for you. And you could write different connectors for specific databases or common sources or sinks of data that you might have. So for example, you have a MongoDB instance. You don't have to write your own producer and consumer application just to get data in and out of there. You can just hook up the MongoDB connector and it will do all that for you. Connect is useful when you just want to get data in and out, but often you want to do something more useful with the data that is in Kafka. And that's where Kafka Streams comes in. Kafka Streams is the streaming engine. And of course the topic of this course. So let's give an example. How would you process events in Kafka? To take a concrete example here? Imagine we have a widget factory. So you're producing widgets. They have some kind of sensors that are on the production line and these sensors have data about the event itself, metadata like the timestamp, the ID, the widget type, and then there's the actual reading or the data. So that might be something like the temperature in Celsius or the weight in this case. You know, you want to make sure that the temperature isn't too high or else that might imply this thing is wrong with the widget, or if the weight is too low, then there might be some manufacturing flaw that you would like to inspect. So you have this information flowing through Kafka in this widget schema, and you want to do something with it. So here's how you would actually write a consumer and producer application that did something with these widgets. Now take, for example, you want to focus on a specific kind of widget only. Maybe you only care about the red widgets, to fill the color, or you've heard that is wrong with the red widgets. And you want to filter out only the red widgets and send that to you a special red widget topic that you can then further process. To do that with a consumer and producer, you have to first obviously instantiate the consumer and producer. You want to make sure that you use a try with resources to close them properly and clean up all the resources associated with them. And then you get to the actual code itself. So with the consumer, you first have to subscribe to the widgets topic that just tells the consumer, when I send a fetch request, I should ask for the events that are in this widget topic. And then you get to a normal event loop for this consumer where you are pulling for more records from this topic. So for each record that you get, you want to take a look at the widget and if it's red, then you wrap it in this special producer record. And then you send it to this widget topic that you have for the red widget specifically. So all that code is what you need is to do a simple filtering and consuming and producing loop. And that's not even counting any of the air handling that usually would go into this. So now let's take a look at how you would do something like this in Kafka Streams. So the first thing that you'll notice with Kafka Streams is it's a lot less code. A lot of the framework of the consumer and the producer is done under the cover. So you don't have to worry about it. Now in Kafka Streams, the first thing you do is declare this Streams Builder object. And that really just tells streams what to do and what you want these events to be processed with. So in this example, you would first create a stream from this widgets topic and all you have to do rather than deal with any actual consumer itself is specify the type of the objects in this widget topic. So in this case, it would be a string as the key and the value is this widget. Now the key can be anything. It doesn't really matter necessarily in this case, the more important thing here is the widget itself. Now that you have the stream, the next thing that you might want to do is filter. In this example, we are filtering for the color red, which previously meant iterating over every single record and potentially dealing with any errors that arise there. Now with Kafka Streams, all you have to do is call this filter operator and specify what you are filtering. You just pass it into predicate in this case that the color is red and that's it. And finally, to actually produce it to your output topic, your widgets red topic, all you do is call to and similarly to with the consumer, you tell it what the type is and what to produce it with, in this case of string and again the widget and that's it. And you're done. So it's really a lot less code, and it's a lot easier to wrap your mind around. One of the main advantages of Kafka Streams over the Plain Producer and Consumer API is that it's declarative. Whereas with the Plain Clients API, it is imperative. In the previous example we were telling the consumer and the producer exactly what to do and how to do it every step of the way. Whereas with Kafka Streams, all you have to do is tell it what you want to be done through these records and not how to do it. And all of that is taken care of you by Kafka Streams framework. So what is Kafka Streams? Kafka Streams is just a Java library that you use to write your own stream processing applications in Java like you would for any other application. It's important to note that this is something you would run on its own, not on the same note as the Broker. It's an unrelated process that connects to the Broker over the network, but can be run anywhere that can connect to the Broker. So Kafka Streams is really powerful because you can build standard Java or Scala applications, not with any extra special functionality that requires running it as a cluster. In other words, Kafka Streams is a standalone application that streams records to and from Kafka. All you need to do is write your application, then build it into a JAR file and execute it like you would any other Java application. Where you actually deploy the application is entirely up to you. This is very convenient because it means you can easily run it on your laptop for development or on Super BB servers up in the cloud. So no more clusters, you just provide it with the host and the port name of a Broker and start the application. Whether you start this on your laptop or on some BB server somewhere, Kafka Streams doesn't care, it just runs. Combine this with Confluent Cloud, and you've got some serious stream processing power with very little code investment. To get started, go to the URL on the screen and click the "Try Free" button. Then enter your name, email and password. This email and password will be used to login to the Compliment Cloud later. So be sure to remember it. Click the "Start Free" button and watch your inbox for a confirmation email to continue. The link in your confirmation email will lead you to the next step where you can choose between a basic, standard or dedicated cluster. The associated costs are listed, but the startup amount, freely provided to you will more than cover everything you need for this course. Click "Begin Configuration" to choose your preferred cloud provider, region and availability zone. Costs will vary with these choices, but they're clearly shown in the bottom of the screen. Continuing to set up billing info. Here you'll see that you received $200 of free usage each month for the first three months. Also by entering the promo code STREAMS101, you receive an additional $101 of free usage to give you plenty of room to try out the things that we'll be talking about. Click Review, to get one let's look at the choices you've made, then launch your new cluster. While your cluster is provisioning, join me for the next module in this course.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.