Enhance your career, get Certified as a Data Streaming Engineer | Get Certified
The Apache Kafka Control Plane



Jun Rao
Co-Founder, Confluent (Presenter)
Control Plane
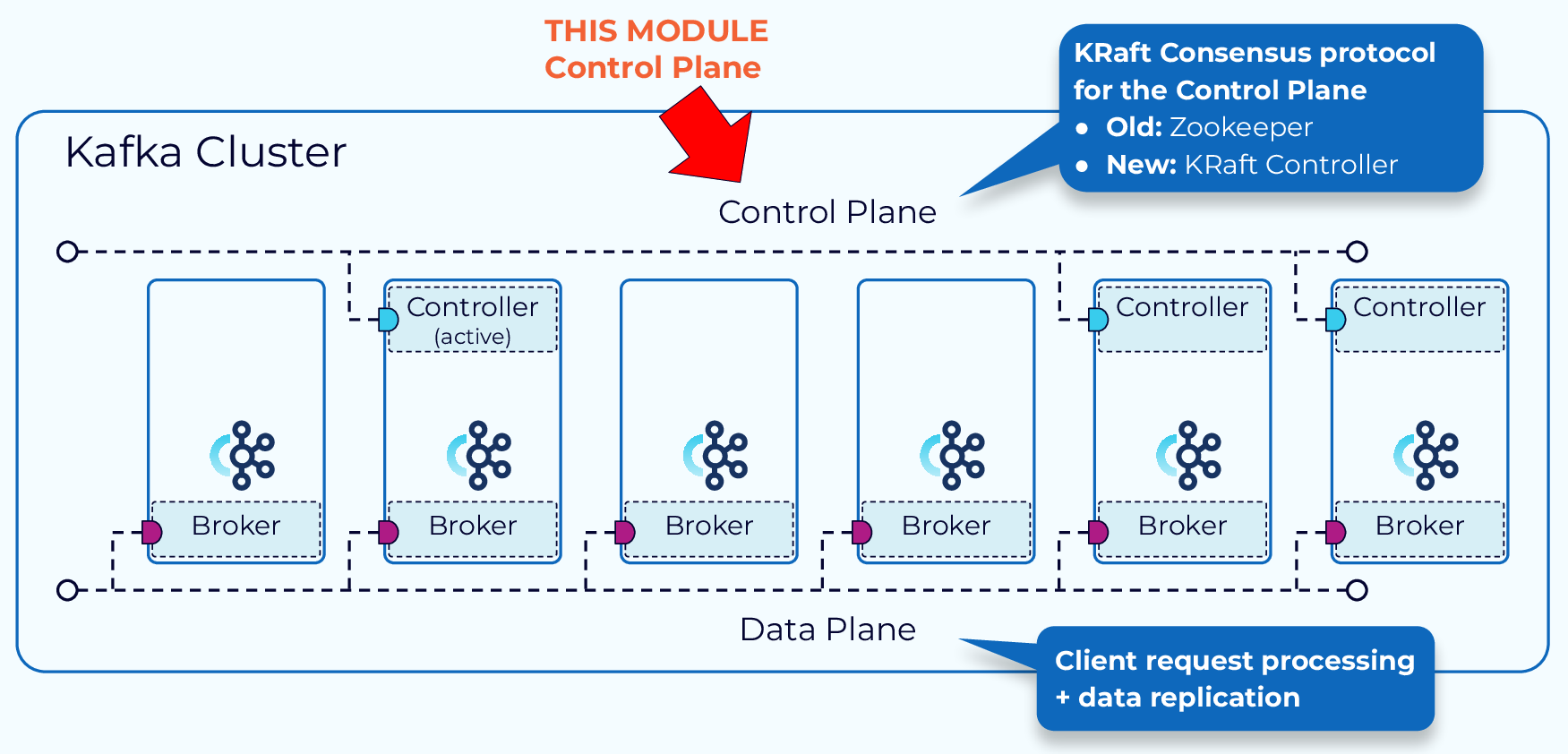
In this module, we’ll shift our focus and look at how cluster metadata is managed by the control plane.
ZooKeeper Mode
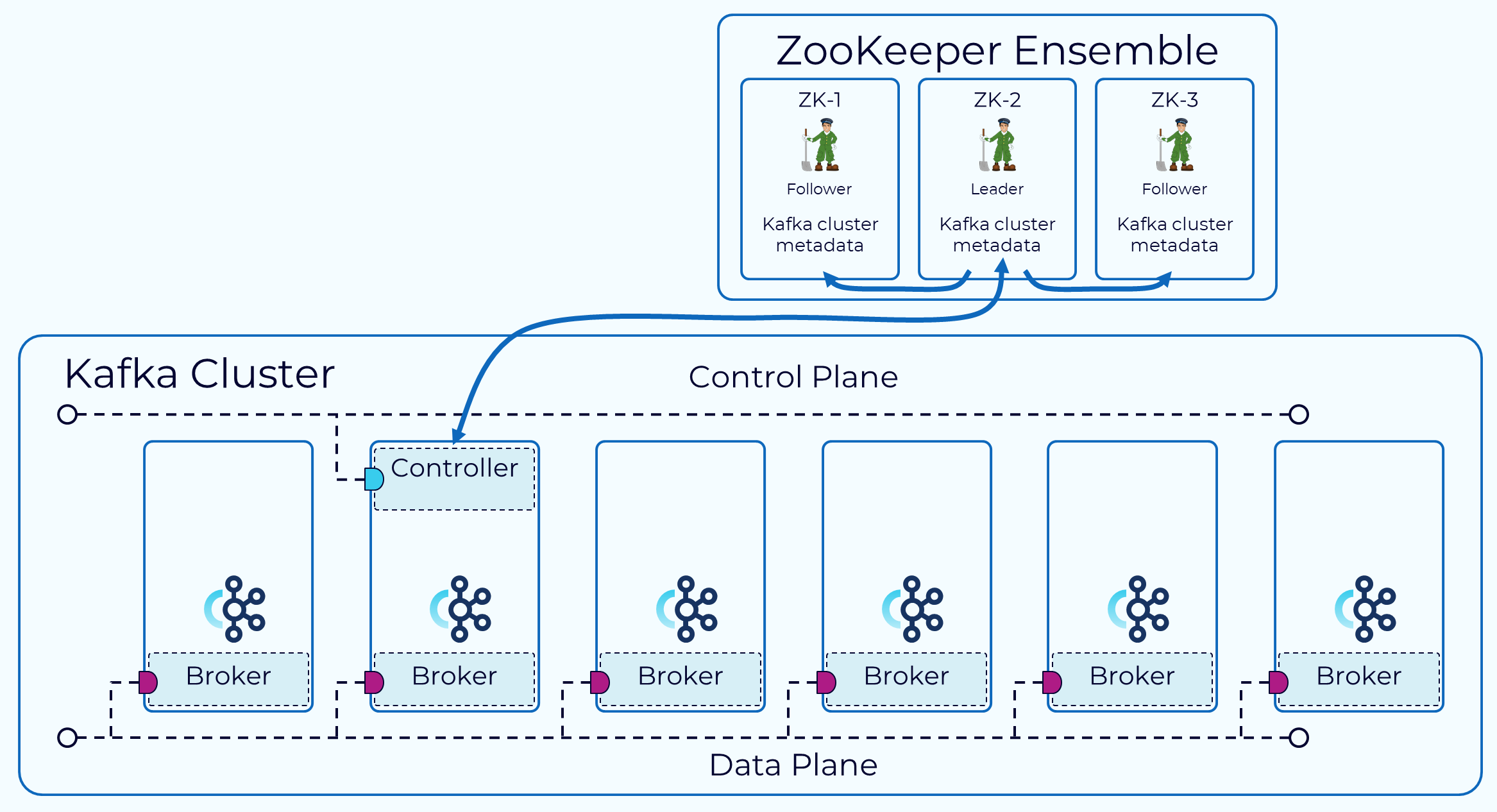
Historically, the Kafka control plane was managed through an external consensus service called ZooKeeper. One broker is designated as the controller. The controller is responsible for communicating with ZooKeeper and the other brokers in the cluster. The metadata for the cluster is persisted in ZooKeeper.
KRaft Mode
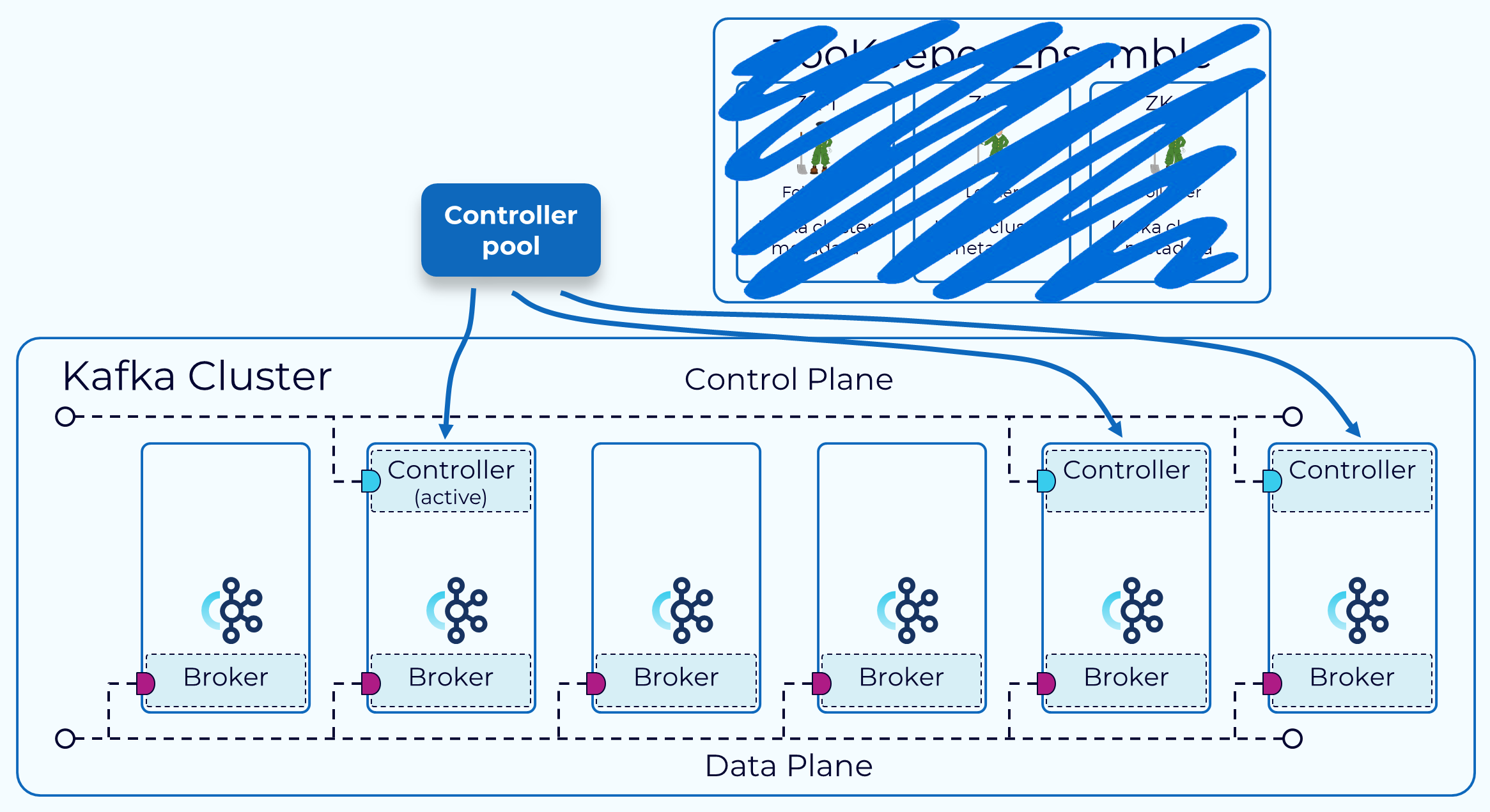
With the release of Apache Kafka 3.3.1 in October 2022, a new consensus protocol for metadata management, called KRaft, has been marked as production ready. Running Kafka in Kraft mode eliminates the need to run a Zookeeper cluster alongside every Kafka cluster.
In KRaft, a subset of brokers are designated as controllers, and these controllers provide the consensus services that used to be provided by ZooKeeper. All cluster metadata are now stored in Kafka topics and managed internally.
For more information on KRaft mode see the KRaft documentation.
KRaft Mode Advantages
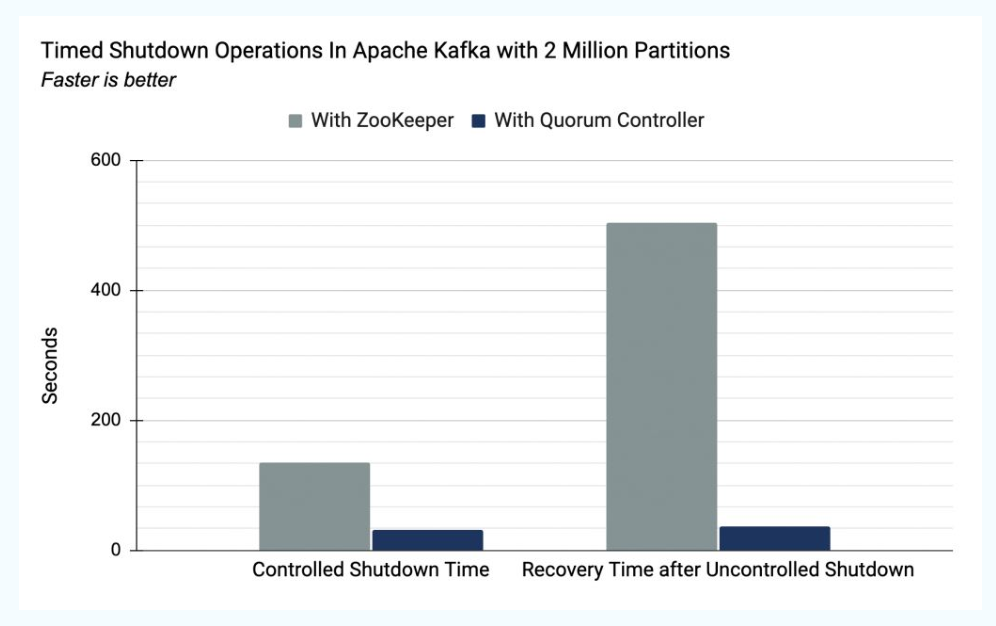
There are many advantages to the new KRaft mode, but we’ll discuss a few of them here.
- Simpler deployment and administration – By having only a single application to install and manage, Kafka now has a much smaller operational footprint. This also makes it easier to take advantage of Kafka in smaller devices at the edge.
- Improved scalability – As shown in the diagram, recovery time is an order of magnitude faster with KRaft than with ZooKeeper. This allows us to efficiently scale to millions of partitions in a single cluster. With ZooKeeper the effective limit was in the tens of thousands.
- More efficient metadata propagation – Log-based, event-driven metadata propagation results in improved performance for many of Kafka’s core functions.
KRaft Cluster Node Roles
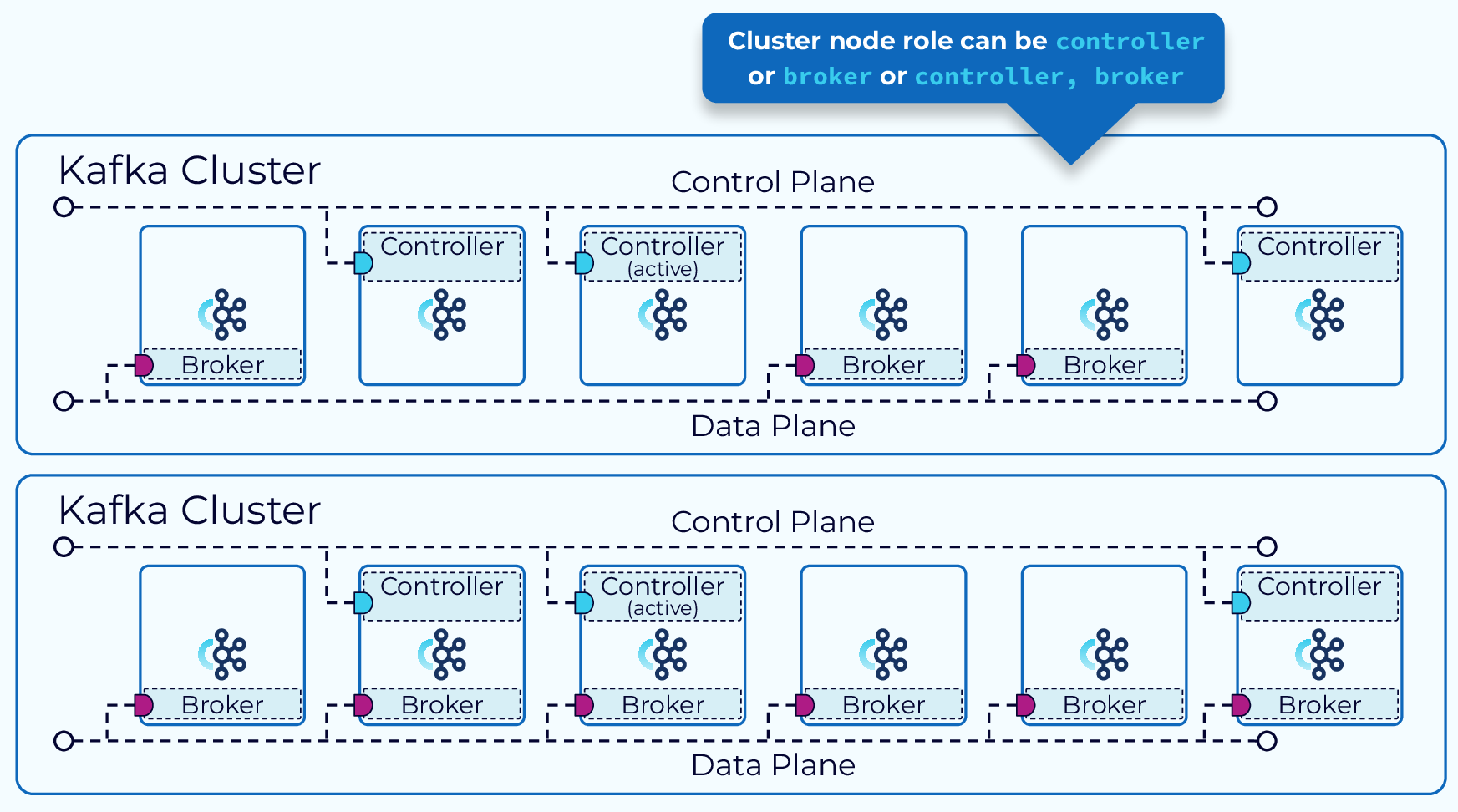
In KRaft mode, a Kafka cluster can run in dedicated or shared mode. In dedicated mode, some nodes will have their process.roles configuration set to controller, and the rest of the nodes will have it set to broker. For shared mode, some nodes will have process.roles set to controller, broker and those nodes will do double duty. Which way to go will depend on the size of your cluster.
KRaft Mode Controller
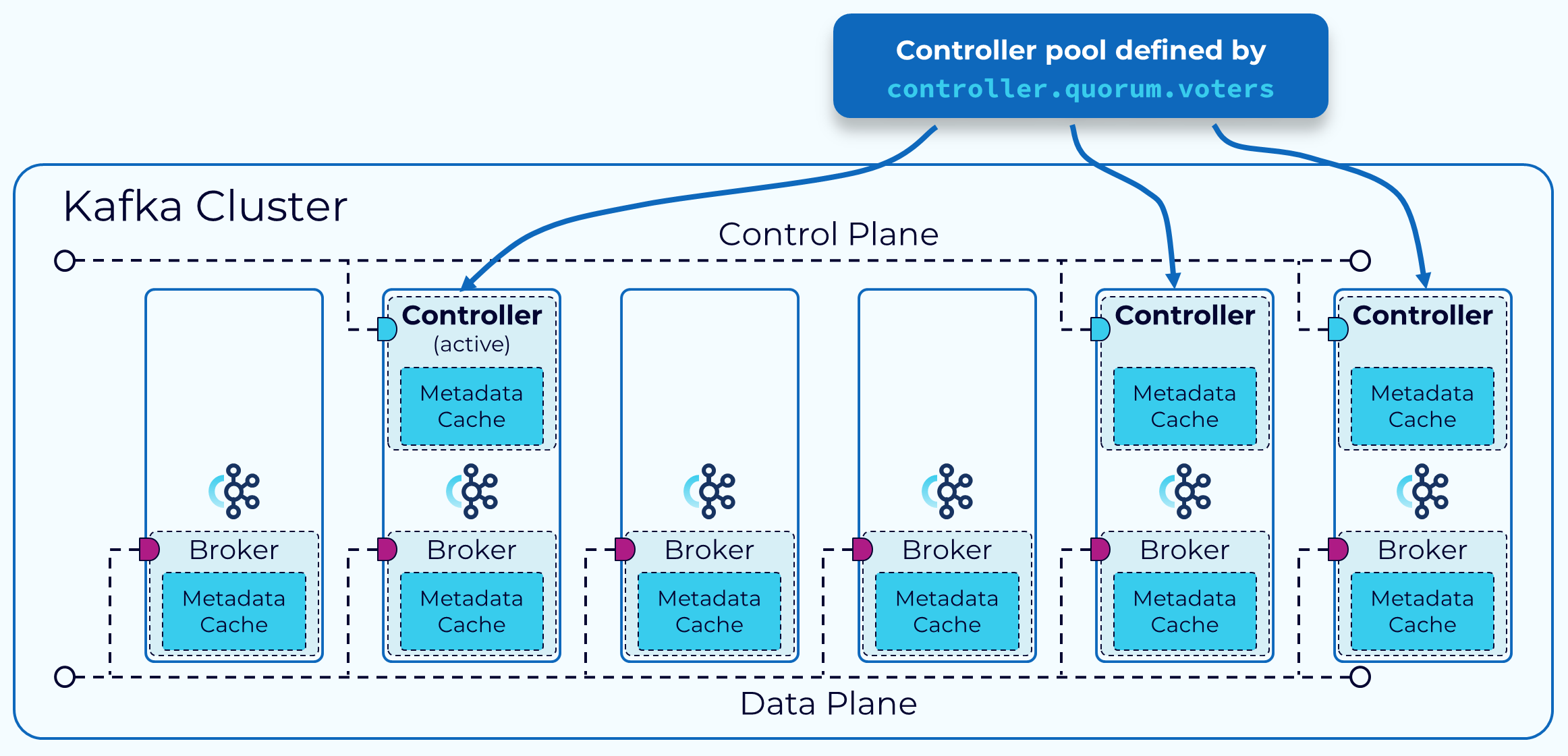
The brokers that serve as controllers, in a KRaft mode cluster, are listed in the controller.quorum.voters configuration property that is set on each broker. This allows all of the brokers to communicate with the controllers. One of these controller brokers will be the active controller and it will handle communicating changes to metadata with the other brokers.
All of the controller brokers maintain an in-memory metadata cache that is kept up to date, so that any controller can take over as the active controller if needed. This is one of the features of KRaft that make it so much more efficient than the ZooKeeper-based control plane.
KRaft Cluster Metadata
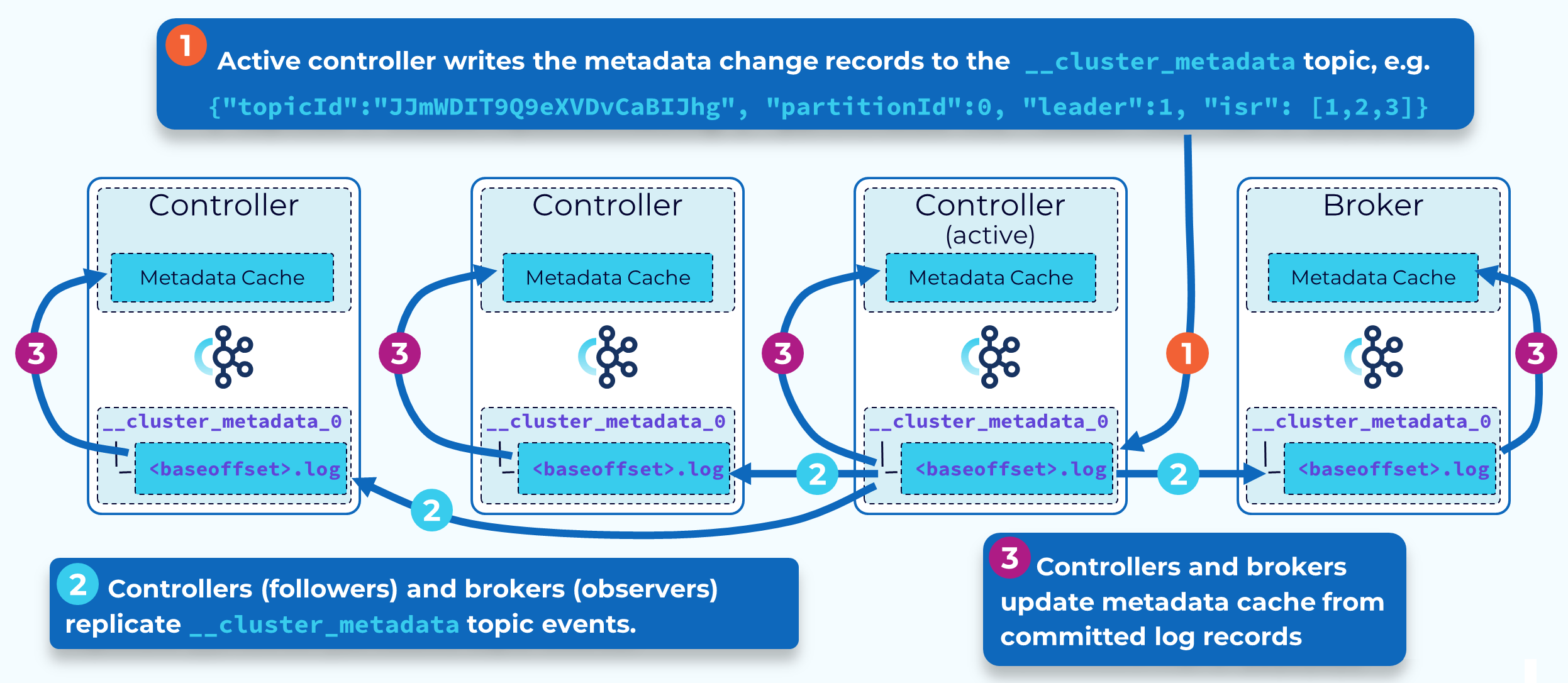
KRaft is based upon the Raft consensus protocol which was introduced to Kafka as part of KIP-500 with additional details defined in other related KIPs. In KRaft mode, cluster metadata, reflecting the current state of all controller managed resources, is stored in a single partition Kafka topic called __cluster_metadata. KRaft uses this topic to synchronize cluster state changes across controller and broker nodes.
The active controller is the leader of this internal metadata topic’s single partition. Other controllers are replica followers. Brokers are replica observers. So, rather than the controller broadcasting metadata changes to the other controllers or to brokers, they each fetch the changes. This makes it very efficient to keep all the controllers and brokers in sync, and also shortens restart times of brokers and controllers.
KRaft Metadata Replication
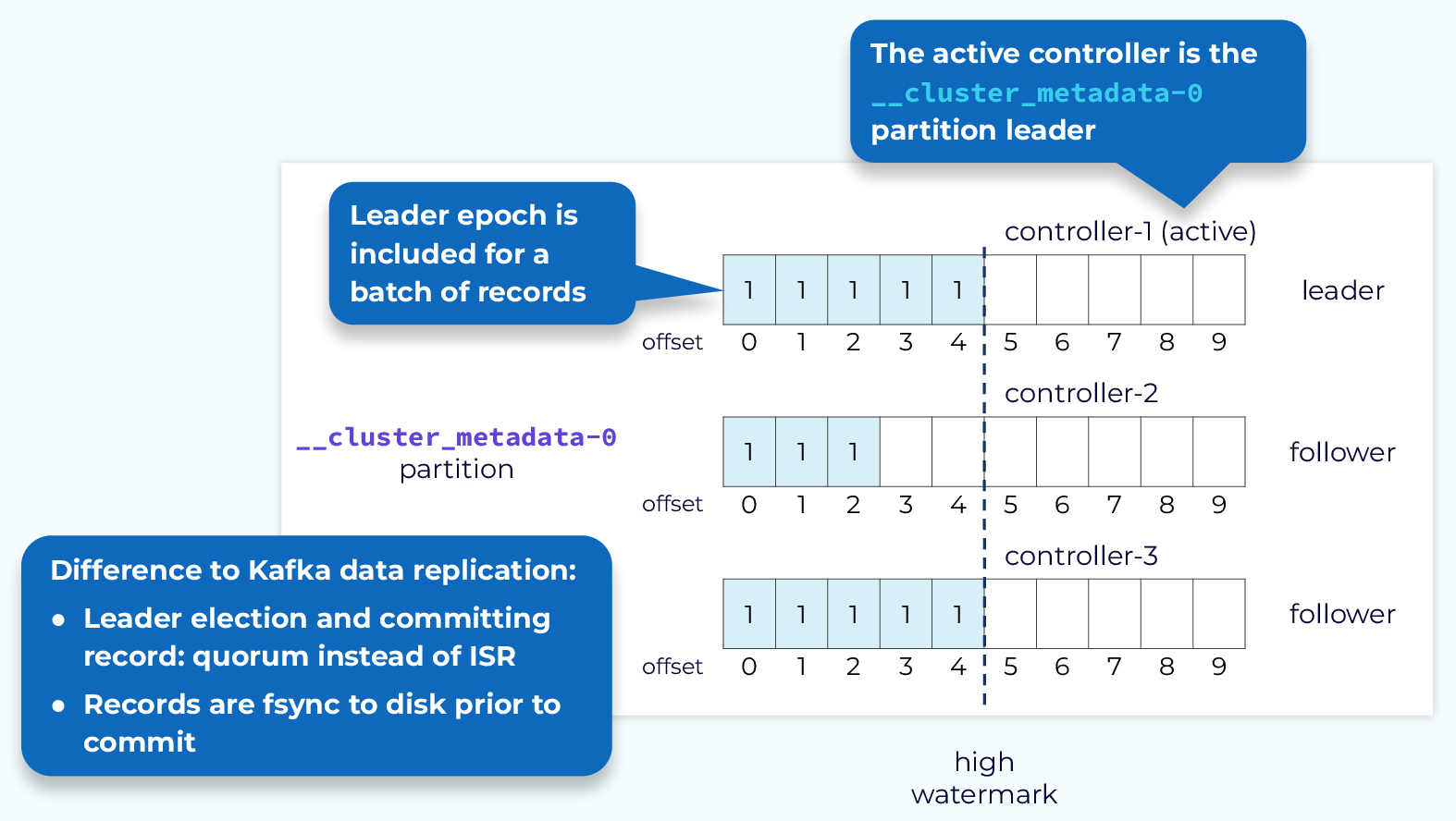
Since cluster metadata is stored in a Kafka topic, replication of that data is very similar to what we saw in the data plane replication module. The active controller is the leader of the metadata topic’s single partition and it will receive all writes. The other controllers are followers and will fetch those changes. We still use offsets and leader epochs the same as with the data plane. However, when a leader needs to be elected, this is done via quorum, rather than an in-sync replica set. So, there is no ISR involved in metadata replication. Another difference is that metadata records are flushed to disk immediately as they are written to each node’s local log.
Leader Election
Controller leader election is required when the cluster is started, as well as when the current leader stops, either as part of a rolling upgrade or due to a failure. Let’s now take a look at the steps involved in KRaft leader election.
Vote Request
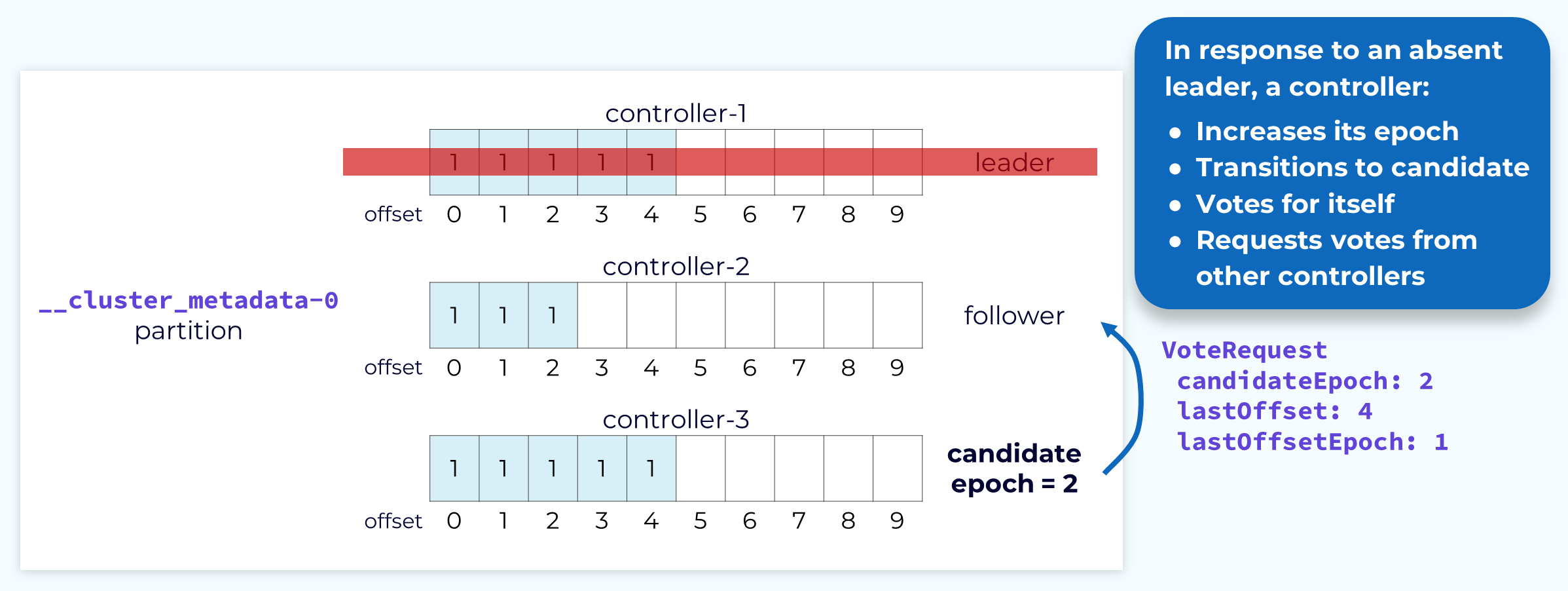
When the leader controller needs to be elected, the other controllers will participate in the election of a new leader. A controller, usually the one that first recognized the need for a new leader, will send a VoteRequest to the other controllers. This request will include the candidate’s last offset and the epoch associated with that offset. It will also increment that epoch and pass it as the candidate epoch. The candidate controller will also vote for itself for that epoch.
Vote Response

When a follower controller receives a VoteRequest it will check to see if it has seen a higher epoch than the one being passed in by the candidate. If it has, or if it has already voted for a different candidate with that same epoch, it will reject the request. Otherwise it will look at the latest offset passed in by the candidate and if it is the same or higher than its own, it will grant the vote. That candidate controller now has two votes: its own and the one it was just granted. The first controller to achieve a majority of the votes becomes the new leader.
Completion
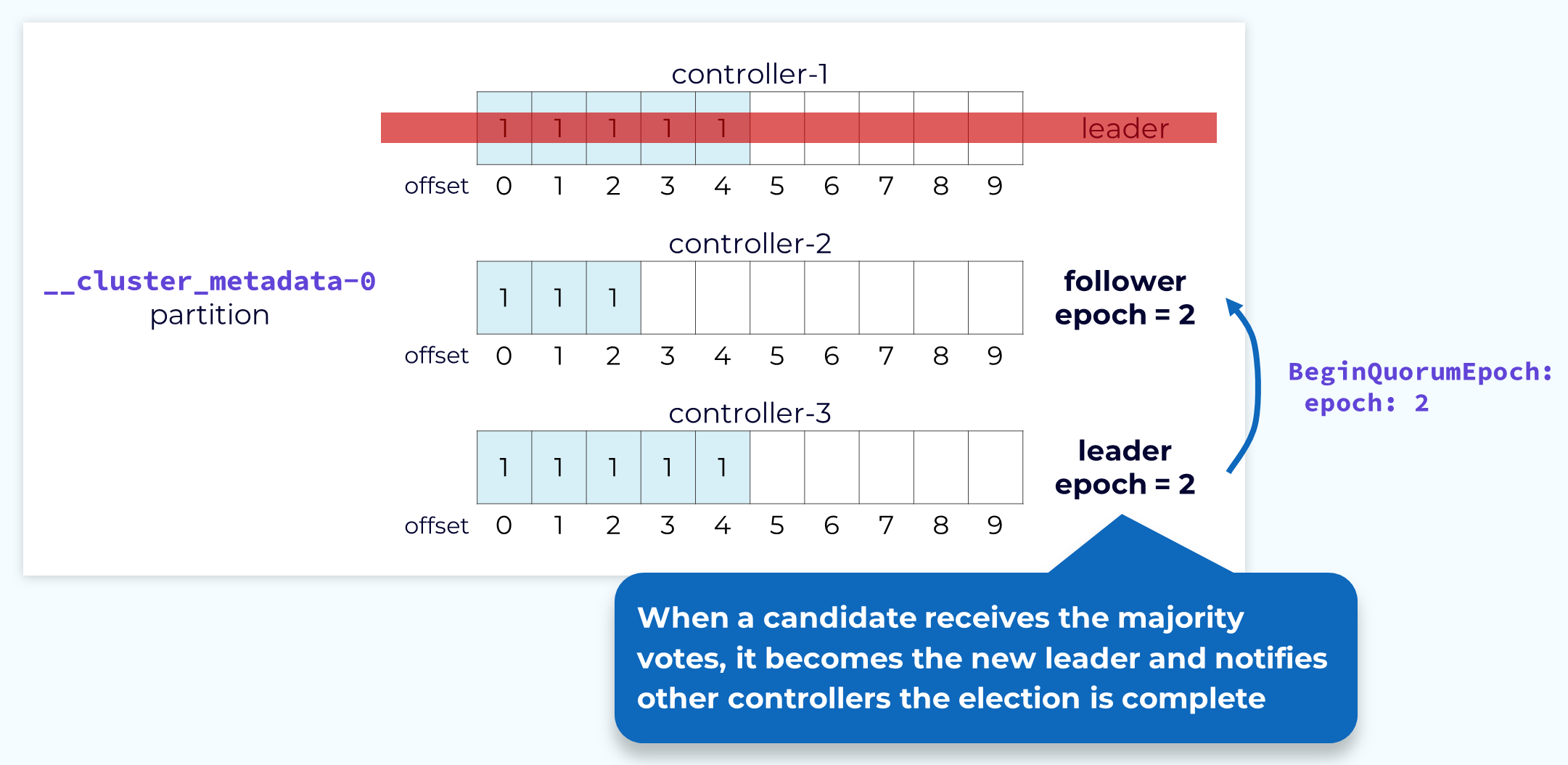
Once a candidate has collected a majority of votes, it will consider itself the leader but it still needs to inform the other controllers of this. To do this the new leader will send a BeginQuorumEpoch request, including the new epoch, to the other controllers. Now the election is complete. When the old leader controller comes back online, it will follow the new leader at the new epoch and bring its own metadata log up to date with the leader.
Metadata Replica Reconciliation
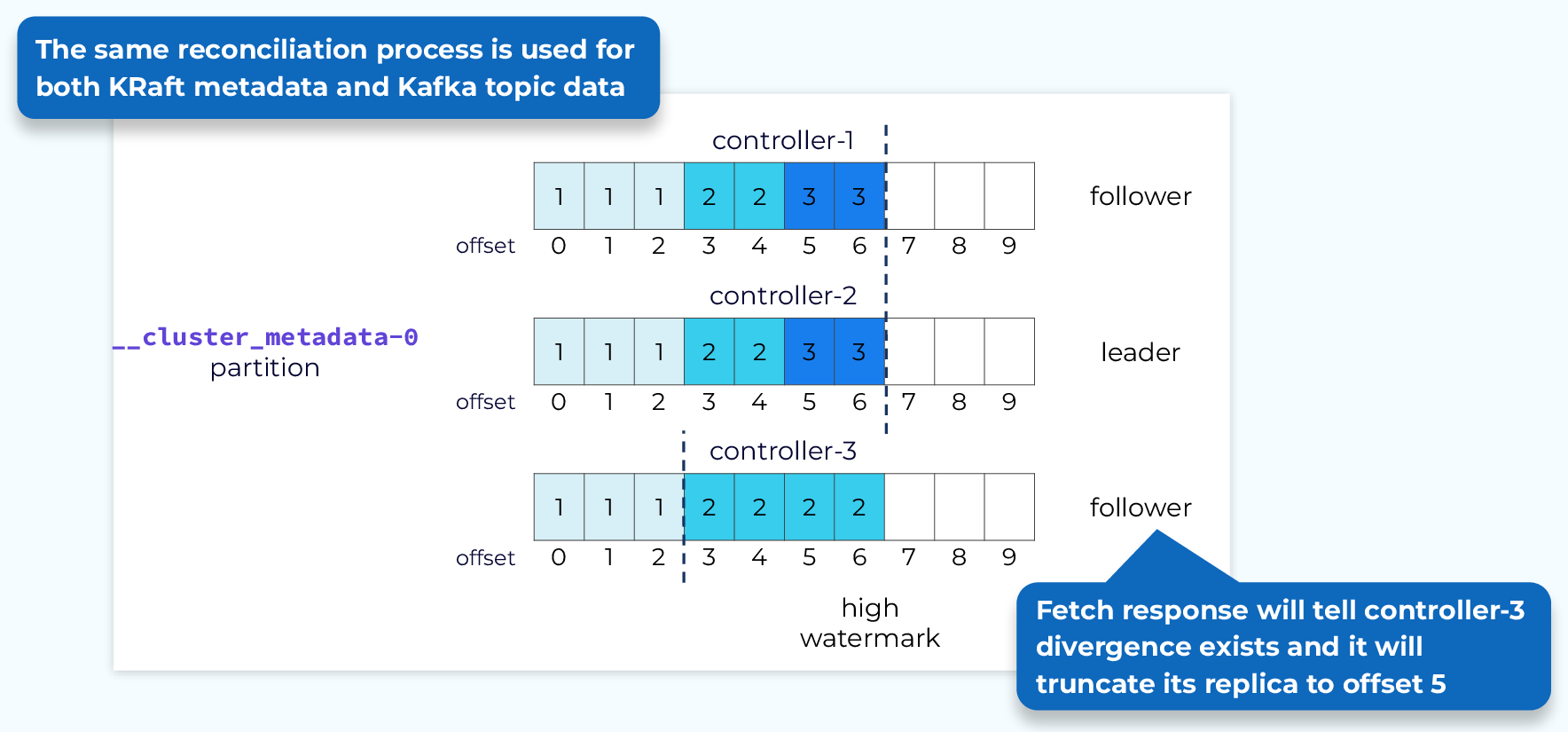
After a leader election is complete a log reconciliation may be required. In this case the reconciliation process is the same that we saw for topic data in the data plane replication module. Using the epoch and offsets of both the followers and the leader, the follower will truncate uncommitted records and bring itself in sync with the leader.
KRaft Cluster Metadata Snapshot
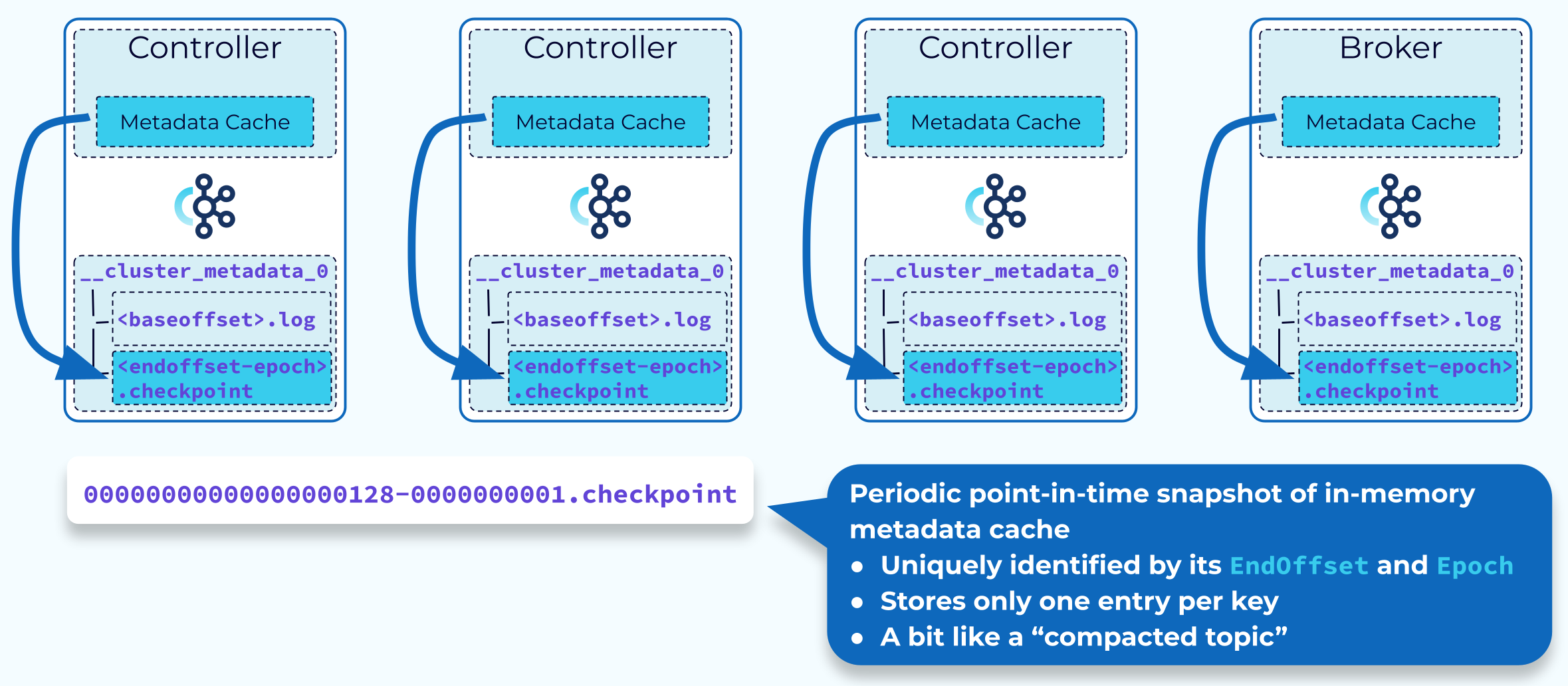
There is no clear point at which we know that cluster metadata is no longer needed, but we don’t want the metadata log to grow endlessly. The solution for this requirement is the metadata snapshot. Periodically, each of the controllers and brokers will take a snapshot of their in-memory metadata cache. This snapshot is saved to a file identified with the end offset and controller epoch. Now we know that all data in the metadata log that is older than that offset and epoch is safely stored, and the log can be truncated up to that point. The snapshot, together with the remaining data in the metadata log, will still give us the complete metadata for the whole cluster.
When a Snapshot Is Read
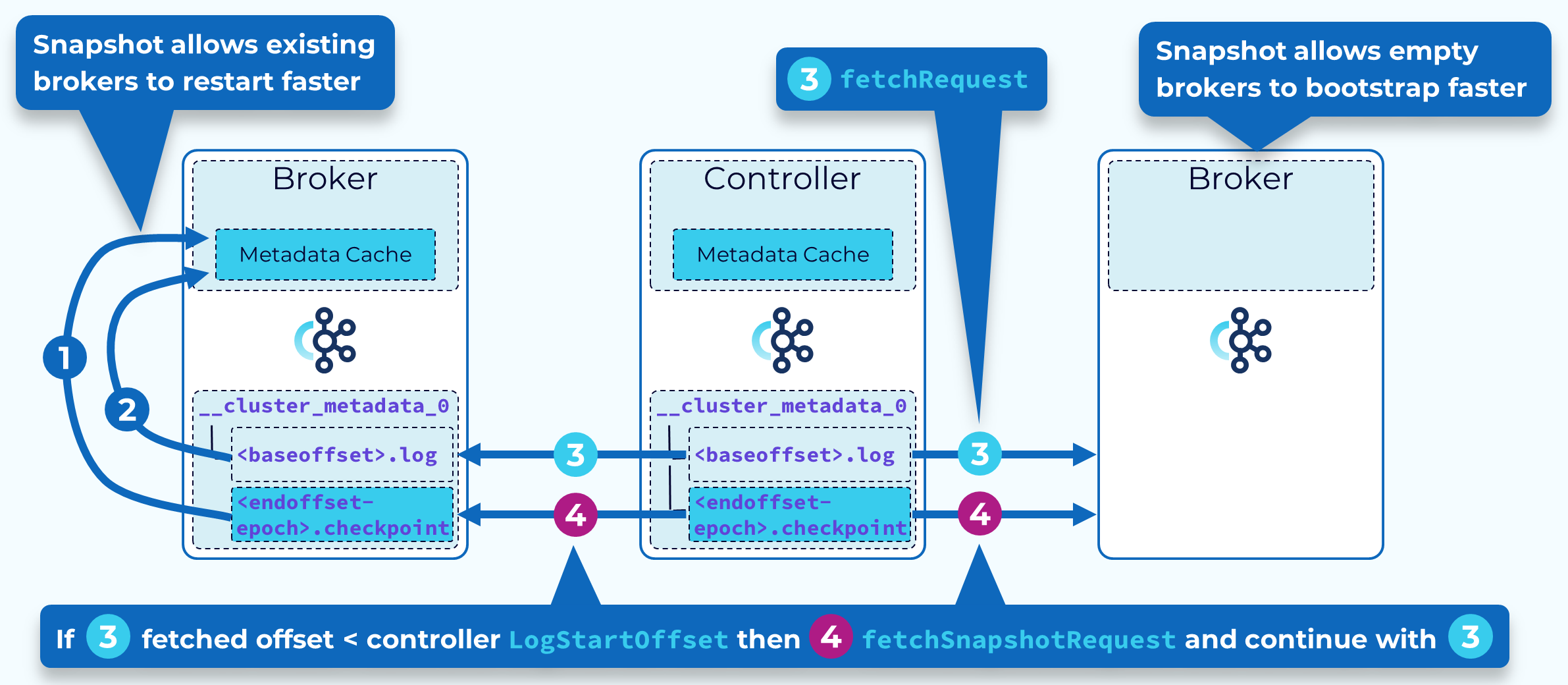
Two primary uses of the metadata snapshot are broker restarts and new brokers coming online.
When an existing broker restarts, it (1) loads its most recent snapshot into memory. Then starting from the EndOffset of its snapshot, it (2) adds available records from its local __cluster_metadata log. It then (3) begins fetching records from the active controller. If the fetched record offset is less than the active controller LogStartOffset, the controller response includes the snapshot ID of its latest snapshot. The broker then (4) fetches this snapshot and loads it into memory and then once again continues fetching records from the __cluster_metadata partition leader (the active controller).
When a new broker starts up, it (3) begins fetching records for the first time from the active controller. Typically, this offset will be less than the active controller LogStartOffset and the controller response will include the snapshot ID of its latest snapshot. The broker (4) fetches this snapshot and loads it into memory and then once again continues fetching records from the __cluster_metadata partition leader (the active controller).
Use the promo code INTERNALS101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
The Apache Kafka Control Plane
Hi, everyone. Welcome back. This is Jun from Confluent. In this module, we're going to talk about Kafka's control plane. So in the previous module, we talked about the data plane and how client requests and replications are handled through the data plane. And in this module, we'll talk about the control plane which manages the metadata of the cluster. The old way of managing the control plane Zookeeper Mode (Legacy) Zookeeper Ensemble is through ZooKeeper. There's one broker that is picked as a special controller and the controller is responsible for managing and changing the metadata of the whole cluster. The metadata is assisted in the consensus service which is external to Kafka and is called ZooKeeper. And the controller is also responsible for propagating the metadata changes to the rest of the brokers. The new world of the control plane is implemented through a new module called KRaft. We completely eliminated dependency on ZooKeeper. Instead, we have a built-in consensus service based on Raft within the Kafka cluster. In this case, you can see a few of the brokers are selected to build this internal consensus service to manage and store the metadata. And this is a relatively new feature. So it is still just in preview. But since this is the future, in this module, we are only going to talk about the control plane based on KRaft. Now, why are we building a new control plane using KRaft? Kraft Mode Advantages Well, these are some of the main reasons. The number one reason is this makes the operation of Kafka a lot easier by removing a number of moving parts. Earlier, you had to have two separate systems, Kafka and ZooKeeper, that you had to manage. Right now with KRaft, you just have one type of system that you have to deal with. This make things like deployment, configuration monitoring, security, much easier and simpler than before. The second reason is the KRaft model in general is much more efficient. Because we have this customized build consensus survey just for Kafka, we can store and manage the metadata in a much more efficient way. So here in this figure, we have shown that in general, with the KRaft model, we can achieve at least 10x scalability improvements in terms of the amount of metadata it can handle within the cluster. The KRaft model also allows the metadata to be propagated from the controller to the brokers in a much more efficient way as we'll see later on. When you configure a KRaft-based controller, there are two ways you can configure it. The top one shows you that you can configure it in a non-overlapping way. You can pick some of the nodes as brokers and some other nodes dedicated as a controller. If you have a smaller cluster, you can also choose to run in a shared mode. In this case, you can say some of the nodes will act both as a broker as well as, as a controller. Both setups are possible. So once we have selected those controllers in a cluster, Kraft Mode Controller those controllers need a way to communicate among themselves. And other brokers also need to communicate with the controllers in order to propagate the metadata. So this is done through this configuration. It provides a list of all the controllers and includes endpoints, including the host names and ports. The active controller as well as the other controllers, they each maintain an in-memory metadata cache. So this is actually pretty useful because if the active controller fails, the rest of the controllers can take over as the new controller much quicker because they don't need to refresh metadata because they have an up-to-date in-memory copy of all the metadata. This is actually one of the ways that KRaft is much more efficient than the old ZooKeeper-based control plane. Once the active controller decides to change a particular metadata, we need a way to persist it. And this is achieved through an internal built-in topic called cluster metadata. This is a very special topic. It only has a single partition and it's used to persist all the metadata within this cluster. So for example here, if a controller wants to make a change to change the leader in-sync replica set for a particular partition, the first thing it needs to do is to write a metadata record into this metadata log. Then this data will be replicated to other controllers or other brokers will also be replicating this metadata log to their local logs. By keeping a local metadata log, this allows a broker to be able to keep up with the changes in a much more incremental way. For example, if the broker is restarted, it doesn't have to refresh all the metadata. It just has to catch up from what it's missing since it's done. This is actually much more efficient than the ZooKeeper way. KRaft Metadata Replication Now, how is the metadata replicated in the KRaft mode? The replication of the metadata is very similar to how the data is replicated. We have a similar concept to the leader and the followers. The data will be flowing first into the leader and then to the followers. And there's a similar concept of leader epoch and all records will be tagged with leader epoch as they are appended to the log. The leader of this metadata log is also the active controller and is responsible for writing the data into this replicated log. But there are some key differences between the metadata replication and the data replication. One of the key differences is that the leader election and offset committing is completely different in KRaft mode. There's no concept of ISR or in-sync replica set because we have no other consensus service that we can rely upon to persist this metadata. So instead, in KRaft mode, the leader election and offset committing is all based on a quorum-based system, which we'll talk about a bit later. The second difference is in KRaft mode, all of the metadata records have to be persisted in the log. They have to be flushed to disk before they are exposed, before they can be considered committed. Vote Request Now, let's look at how the leader election works in KRaft mode. Let's say in this case, the old leader on controller one failed and then we need to elect a new leader. In this case, since there's no concept of ISR the remaining replicas, controller two and three need to coordinate among themselves to select a new leader. So the way this works is each of these followers will be first bumping up its epoch and then will mark itself as a candidate. It will vote for itself for this particular epoch. And it will send vote requests to all other replicas to request a vote from them. To prevent the case where all the followers try to elect themselves at the same time, there's a little back up logic. So each of the candidates will back up to a random number and then make itself as a candidate. Let's say in this case, replica three is the first that gets selected as a candidate And then it will send this voter request to other followers including its candidate epoch as well as a little metadata about its log which is the end offset of its log and the latest epoch it has. Once one of the other followers receives this vote request, Vote Response it will first check if it has seen any epoch higher than this epoch. If so, it will reject this request. Then it will check to see if it has already responded to this particular epoch. If so, it will just send the same response it made before. In this case, it hasn't really made a response before, so what the follower does is to compare the candidate's log with its own log, to see which one is longer. In this case, it will notice that the candidate's log has the same epoch but has a longer offset than its local log. So in this case, it will notice that the candidate's log is at least as long as its own local log, so it will actually vote yes to this vote request. So once the candidate has collected enough votes, Completion it will consider itself as the new leader. In this case, it has accumulated two out three votes. So it can become the new leader. Once the new leader is elected, it will inform other replicas through another request to tell them that it is the new leader and they should be following it. Metadata Replica Reconciliation Once the new leader is elected, we need a very similar log reconciliation process to make sure all the replicas are consistent. As you can see in this case initially, the follower's data is a little bit inconsistent with the new leader because some of the records in its log are never committed. So in this case, what a follower will do is to go through a similar process as the data replication reconciliation logic by sending its epoch and offset. And eventually, the follower's log will be truncated and made consistent with the leader. KRaft Cluster Metadata Snapshot We need a way to prevent the metadata log from growing forever. We can't simply just truncate all the data in the metadata log. Because it may still consist of some of the latest values for some of the resources the cluster is managing. So instead, what we do is use a concept called a snapshot. So periodically, each of these controllers, and the broker will take the latest records in the metadata cache and write that as a snapshot. Once the snapshot is written, which is corresponding to a particular end offset, we know all the records before that particular end offset in the metadata log are redundant. They are no longer needed. So at that point, once we generate a snapshot, Metadata Log Truncation with Snapshot we can start truncating some of the old data in this metadata log. The snapshot together with the remainder of the metadata log will still give us the latest metadata for the whole cluster. When a Snapshot is Read Now, how is the snapshot being used? Well, the snapshot is used in a couple of cases. Each time a broker is restarted, it will need to rebuild this in-memory metadata cache. It does that by first scanning through the latest snapshot and loading that into memory followed by continuing to fetch the data from the last offset associated with the snapshot from this metadata log. The second use case of the snapshot is when the controller or the broker is fetching the metadata from the leader's metadata log. Sometimes when a fetch request is issued, the offset in the fetch request may no longer exist in the leader's metadata log because the leader may have truncated it after generating some of the latest snapshot. So in this case, the leader will send a response to the controller or the follower to indicate that its offset is missing, and that they need to first catch up on the snapshot. So after receiving this response, the broker or the controller will first scan through or issue a request to scan through all the snapshot data from the leader. And after that, they will switch to consume the data from the metadata log after the end offset associated with the snapshot. So this concludes this particular module. Thanks for listening.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.