Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Geo-Replication



Jun Rao
Co-Founder, Confluent (Presenter)
Single-Region Cluster Concerns
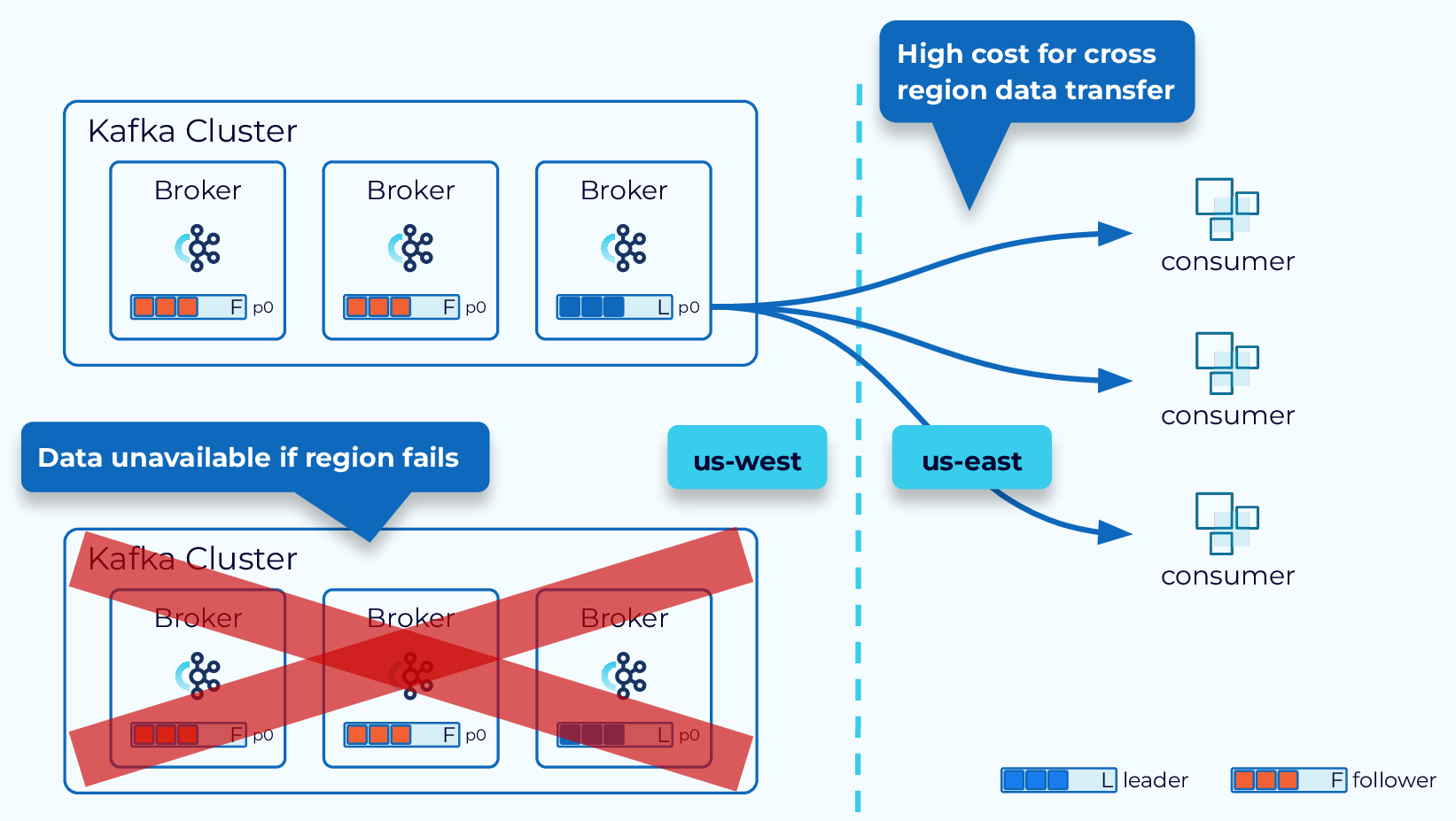
Operating a Kafka cluster in a single region or in a single data center has some distinct drawbacks. A data center or cloud provider outage can take us completely offline. Also, if we have clients that are in different regions the data transfer costs can get out of hand quickly.
Geo-Replication
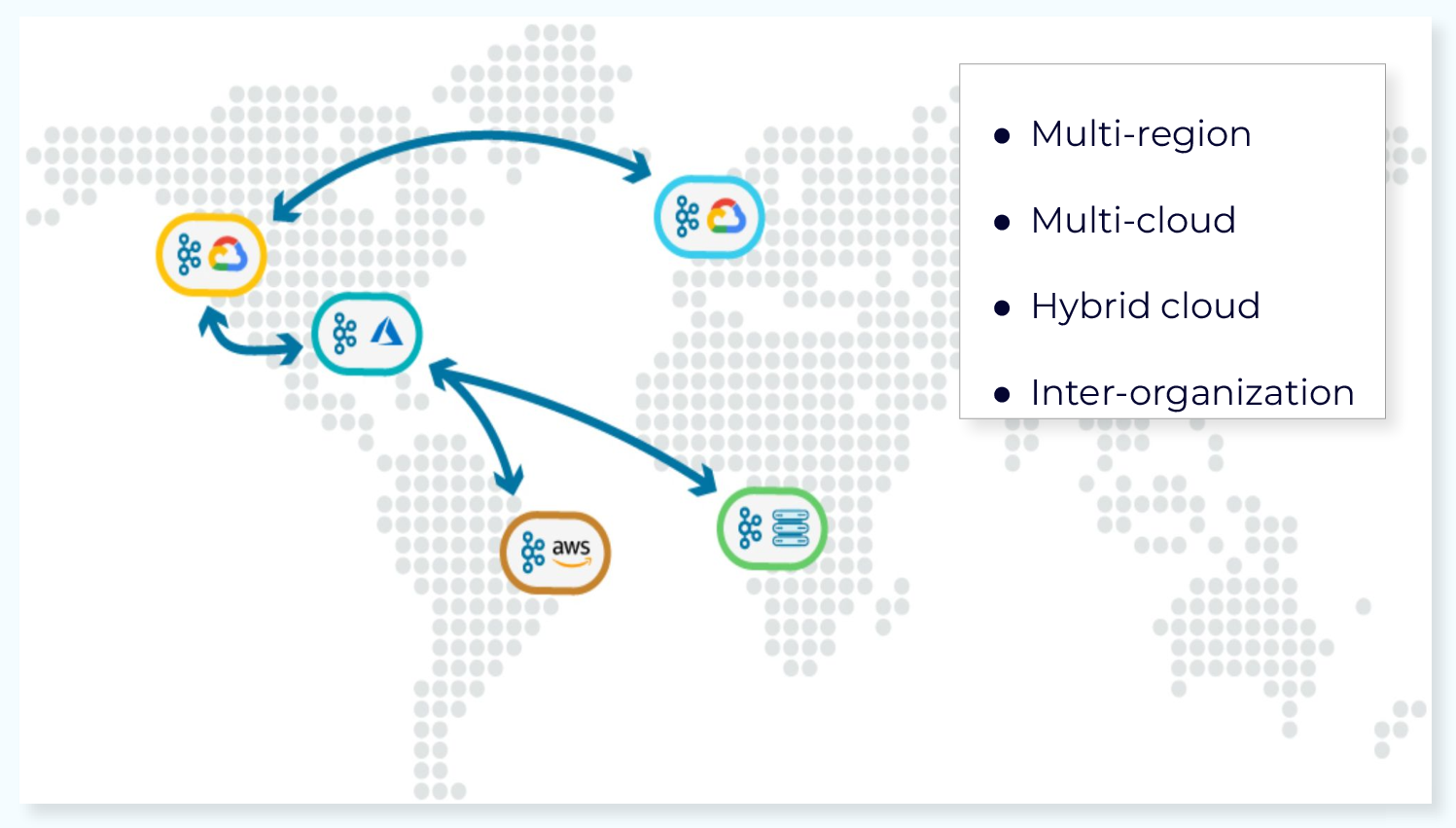
Geo-replication solves these problems by providing for high availability and disaster recovery, and by allowing us to put our data closer to our clients. There are multiple ways to achieve geo-replication, and in this module we’ll look at four of them.
Confluent Multi-Region Cluster (MRC)
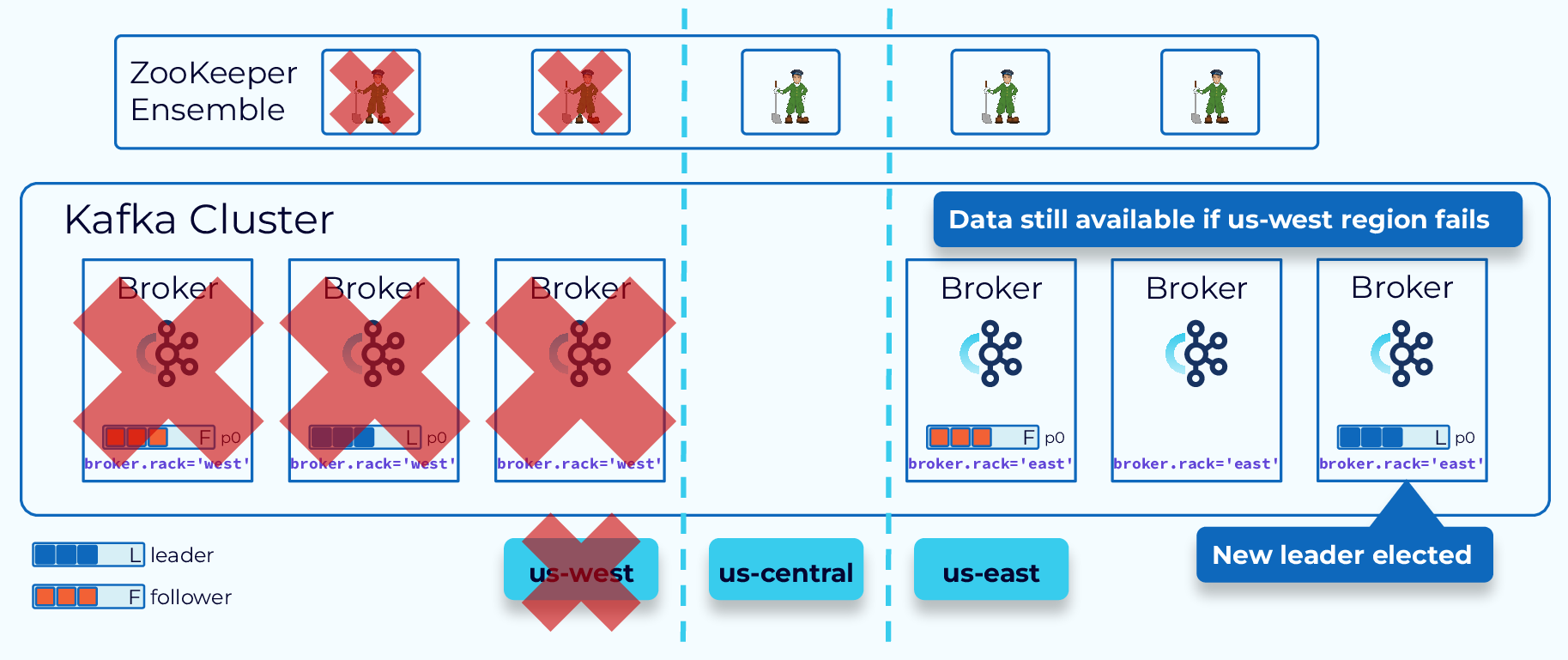
Confluent Multi-Region Cluster (MRC) allows you to deploy Confluent across regional data centers with automated client failover in the event of a disaster.
MRC enables synchronous and asynchronous replication by topic, and all the replication is offset preserving.
It is the solution you might choose if you cannot afford to lose a single byte of data or have more than a minute of downtime.
When designing a multi-region cluster, be sure to consider the control plane, which is consensus based. If we’re only going to have two Kafka clusters, we will also need a third data center to host a ZooKeeper node or KRaft controller, so that if one region goes down, we can still have a majority to reach consensus.
Better Locality with Fetch From Follower
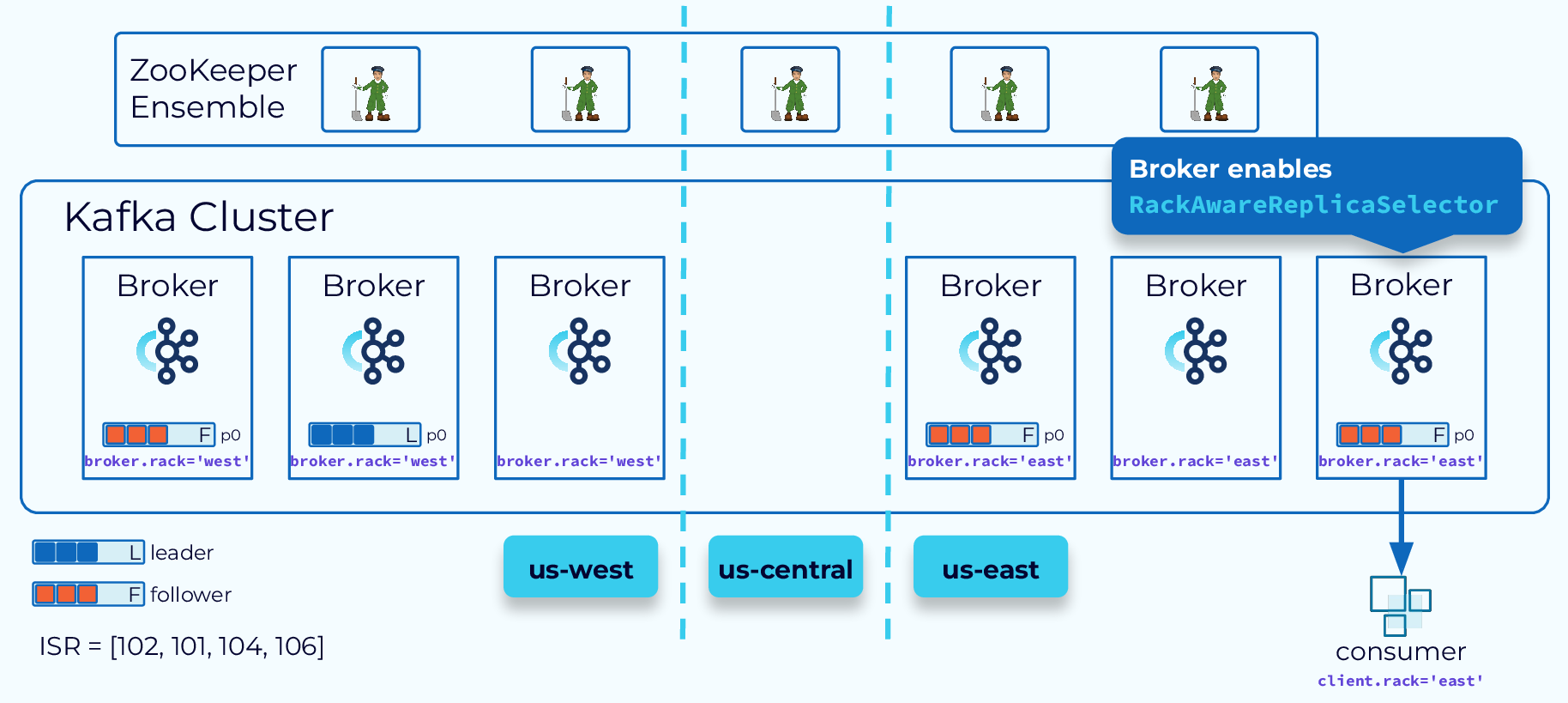
In order to achieve better locality with our multiple regions, we can use the Fetch From Follower behavior that was introduced by KIP-392. With this setting, consumers can fetch from a follower replica if it is closer to them than the leader replica. To enable this feature, configure the brokers to use the RackAwareReplicaSelector and set the broker.rack to designate the location. Then configure the consumer with client.rack of the same value.
Async Replication with Observers
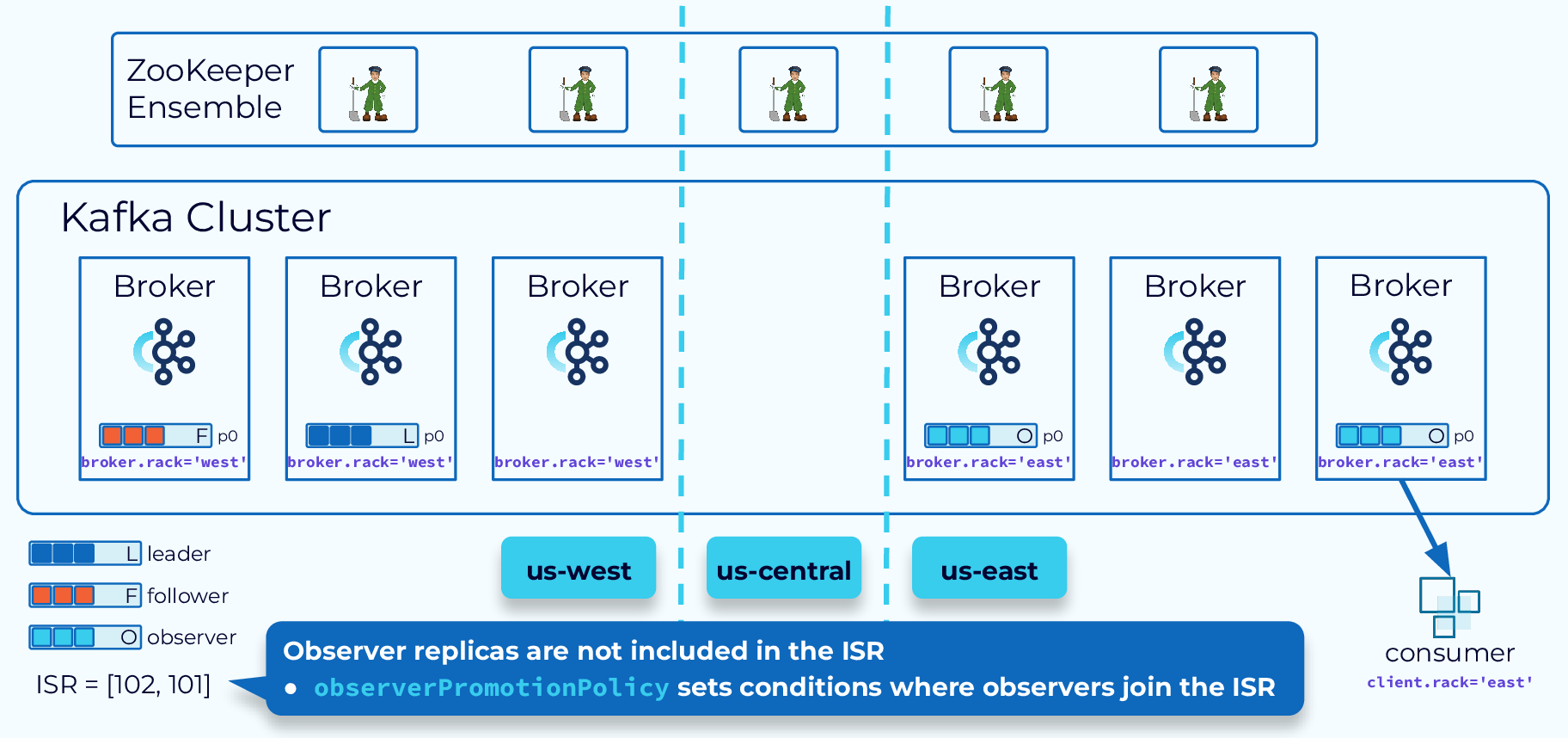
For some applications, low latency is more important than consistency and durability. In these cases, we can use observers, which are brokers in the remote cluster that are not part of the ISR. They are replicated asynchronously, which provides lower latency, when consumers are configured to fetch from followers. But they only provide eventual consistency. Events read by consumers may not be the very latest.
Observers can also be promoted to full-fledged replicas and even take over as leader, based on our observerPromotionPolicy, but be aware that this can lead to possible data loss.
Kafka MirrorMaker 2
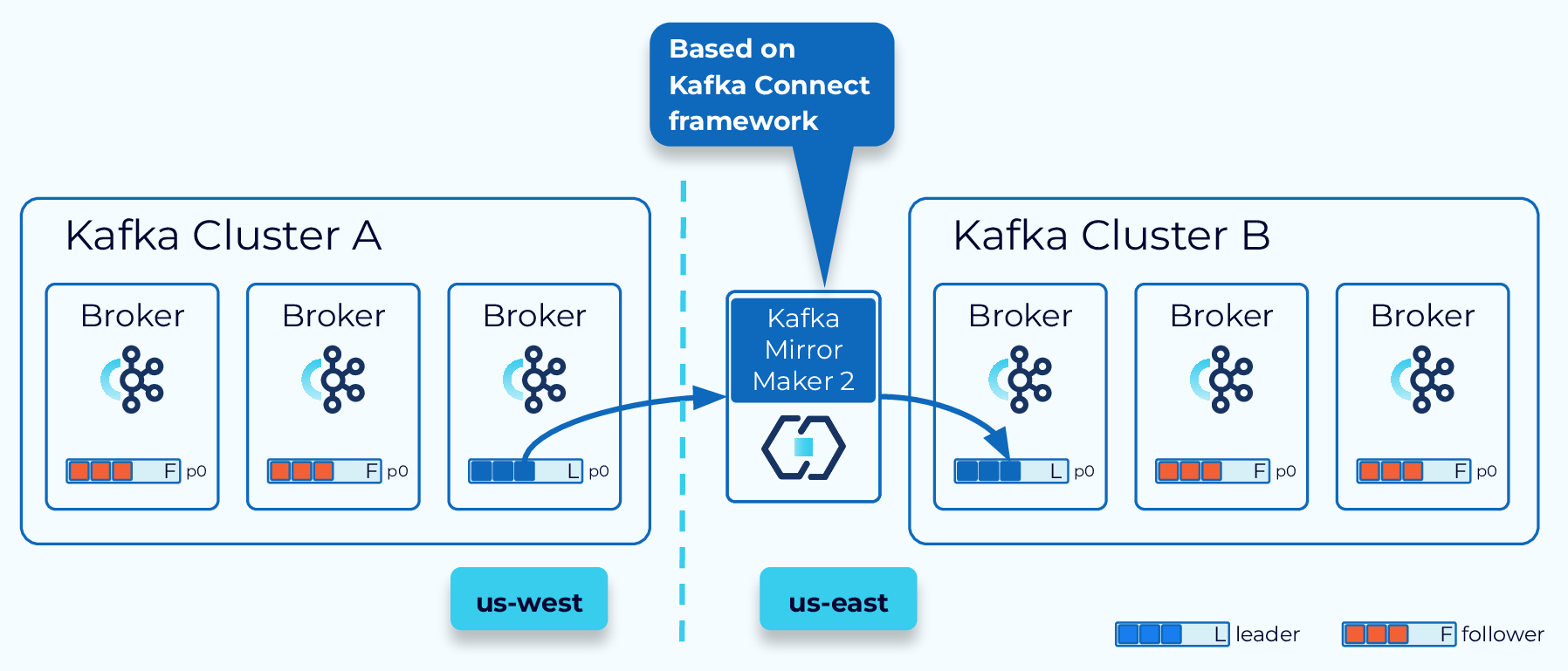
MRC works best with regions that are relatively close. For greater distances, another option is Kafka MirrorMaker 2 (MM2), which is based on Kafka Connect. With MM2, topics, configuration, consumer group offsets, and ACLs are all replicated from one cluster to another. It’s important to note, that unlike MRC, topic offsets are not preserved. In a failover scenario, some manual offset translation would be required.
Confluent Replicator
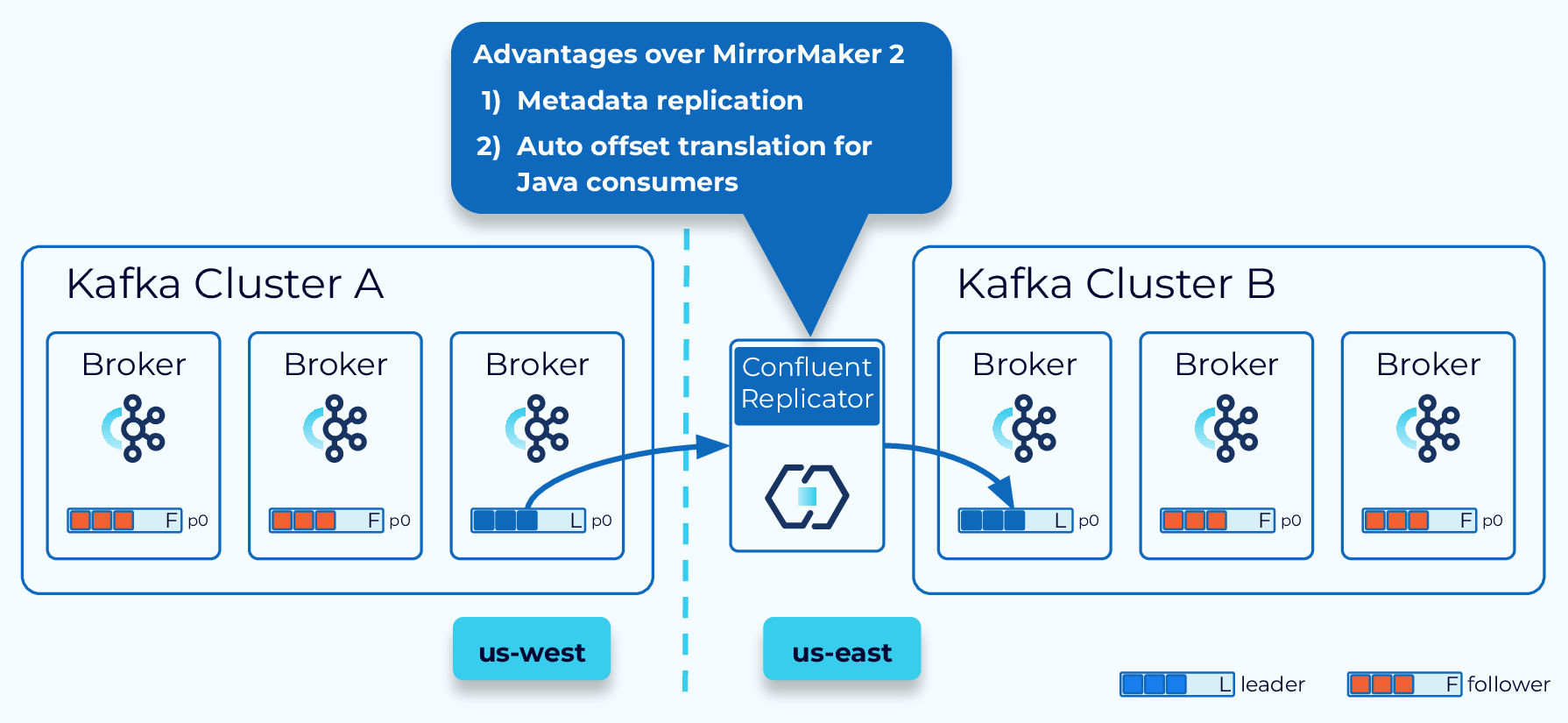
Another option is Confluent Replicator. Replicator works similarly to MM2 but provides some enhancements, such as metadata replication, automatic topic creation, and automatic offset translation for Java consumers.
Confluent Cluster Linking
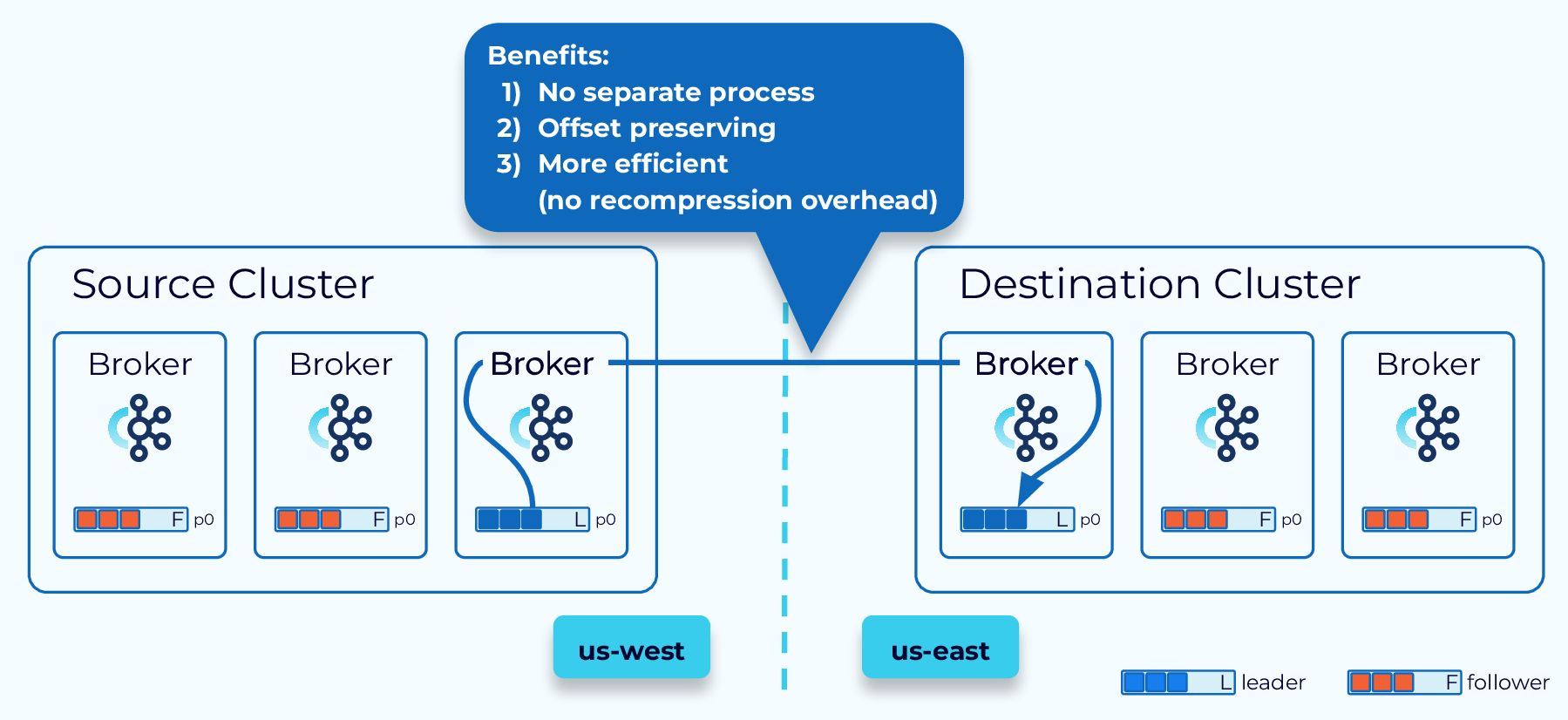
Cluster Linking, from Confluent, goes even further by making the link between the source and destination cluster part of the clusters themselves. There is no separate process to run. Also, data is directly pulled from the source to the destination without having to consume and reproduce it, as we need to do with Kafka Connect-based solutions. This provides for more efficient data transfer, and best of all, offsets are preserved.
Cluster Linking also allows us to connect Confluent Cloud and on-prem Confluent Platform clusters.
Cluster Linking – Destination vs. Source Initiated
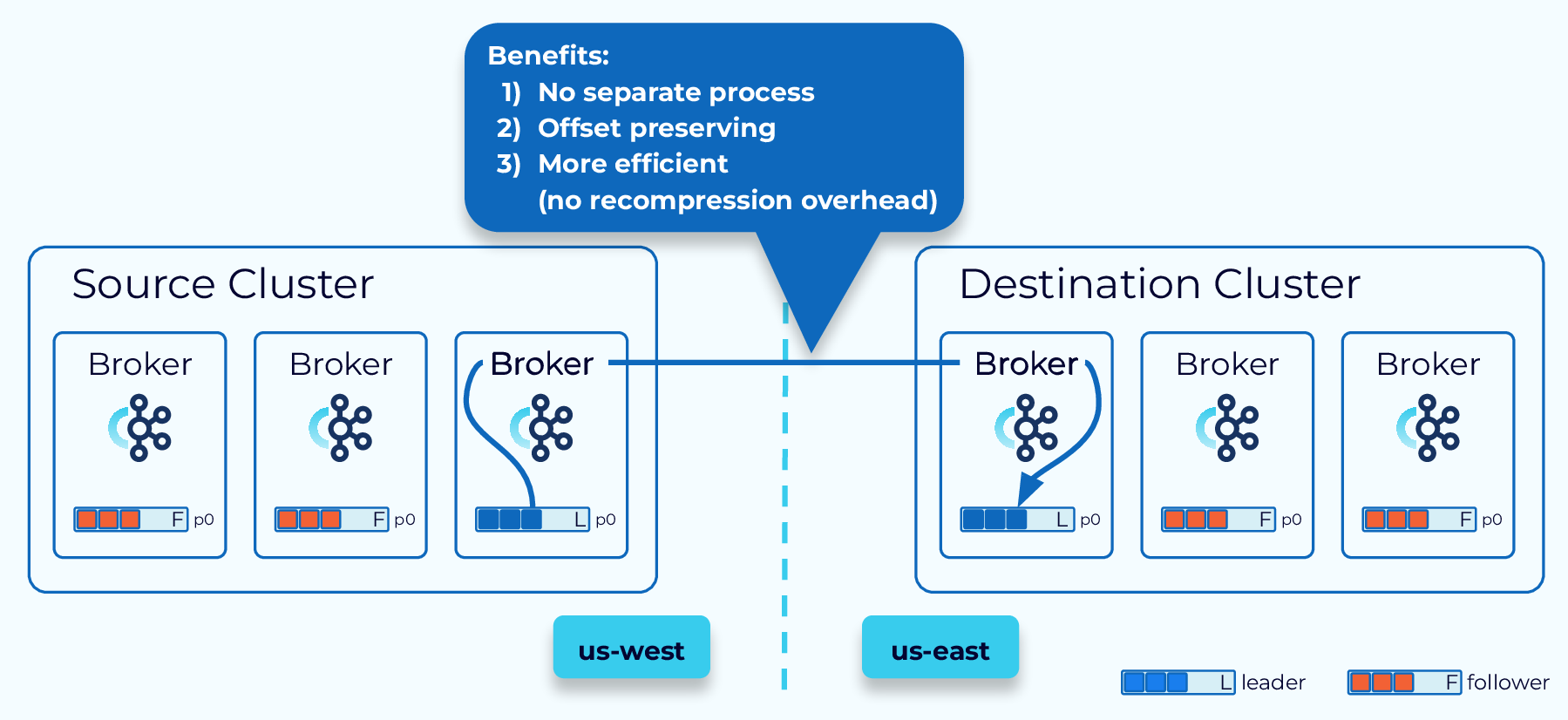
When the destination initiates the link, the source may have to open firewall ports to allow it. This may be a security concern in some situations, so an alternative is provided where the source initiates the connection and the destination uses that connection to pull from the source.
Recap
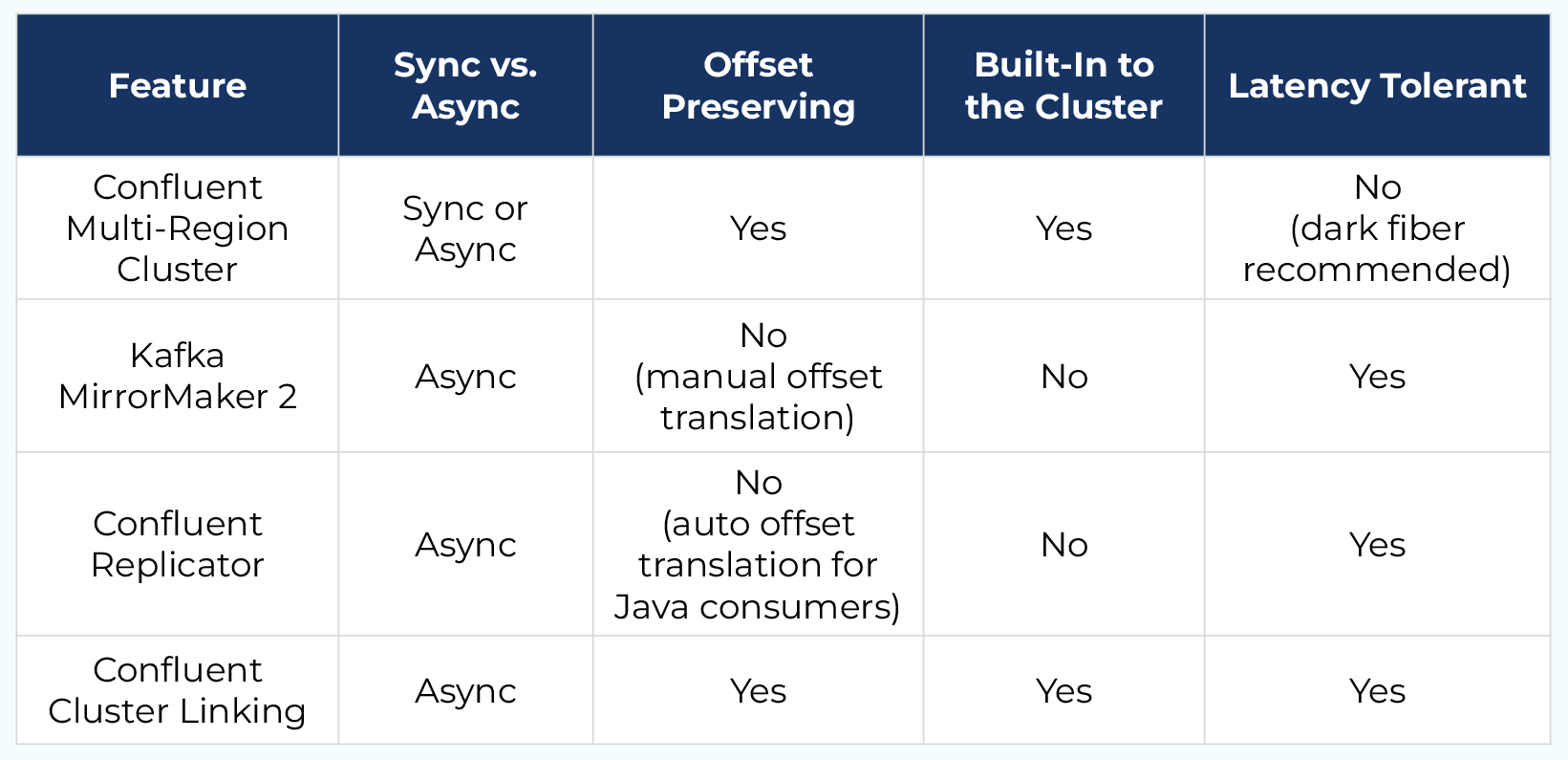
Sharing data across regions or data centers is becoming a necessity for many organizations and it’s great to see that we have options. But deciding which solution is the best one for any given situation can be challenging and must be done with careful consideration. While there’s no substitute for research and experimentation, hopefully this feature matrix can give you some ideas to get you started.
Use the promo code INTERNALS101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Geo-Replication
Hi, everyone, welcome back. Jun Rao from Confluent here. In this module, I'm going to talk about geo-replication for Kafka. Single-Region Cluster Concerns First, why do we need geo-replication? Well, there are two main reasons why you need geo-replication. The first reason is for disaster recovery. So if you only have a single region cluster and if that region fails, then your business stops. But if you have availability in another region, then you can continue your business. The second reason is for local affinity. Because in this case, if you only have data in one region, you may have some other consumers that are in some other data center that can be further apart, letting all those applications independently pull remote data can stress the limited cross-data center bandwidth. So it's much better to be able to pull data once into this remote region and then serve that data locally. So these are two common reasons why you need geo-replication. With geo-replication, we can solve these needs much better. We can set up this multi-region environment, whether it's within the public cloud or between on-prem and the public cloud, within the organization or across organizations. You have lots of flexibilities. Let's look at what are some choices we have in the geo-replication space. Confluent Multi-Region Cluster The first option is from Confluent it's called multi-region cluster. In the multi-region cluster, the way you set up is you set up a stretch cluster across the regions where you want to have your data. Typically, you spread the data between the two data centers you have. But for the control plane, it's a bit tricky. Because for that, since it's based on the consensus service, we do need a third data center for you to put an actual ZooKeeper node or the new controller node in the KRaft mode. So that you can have the majority of the nodes still available when there's a single data center failing. When you set up the brokers, you typically would set, would enable the rack tag for each of the brokers. In this case, you will configure all the brokers in this cluster with US west and you will configure all the brokers in this data center with US east. Once you do that, when you create a particular topic, the replicas of this topic will be evenly spread around between those different racks. In this case, if one of the data centers fails, you can automatically have all traffic flipped over to the other data center because the leader will be moved over. Since this is really a single stretch cluster, all offsets are preserved. So from the consumer's perspective, they can just continue with exactly the same offset where they left off. There are a couple of optimizations we can do in this multi-region cluster mode. Better Locality with Fetch From Follower The first optimization we can do is to enable fetch from follower for better locality. In this case normally, the consumer will always read data from the leader but if the consumer is in a different geographical location, it's inefficient because it has to read the data across the remote link. In this case, what it can do is to enable this rack replica selector policy on the broker side and can also configure a consumer application with the rack affinity. When you set this up, then the broker will determine the closest follower to this consumer allocation and will be routing traffic from that particular replica to the consumer. This improves the locality during the consumption phase. Another optimization we can do with multi-region clusters Async Replication with Observers is through the observer capability. By default, the replication is synchronous between the two data centers. If the data centers are a bit further apart from each other, this can add latency. So for some applications, they may be willing to get better latency by sacrificing a little bit of the durability of the data. In this case what they can do is set up observers. In this figure, we have the leader and followers set up in one data center and we have some other replicas set up in the other data center as observers. Normally, the observers will not be part of the ISR so they won't be delaying the committing of the offsets and exposing the data to the consumer applications. Which improves the latency story. Now, in some cases, you can promote the observer to the ISR or even as leader. So this can be done through this observer policy. For example, you can say, if there's not enough replica or not enough in-sync replicas, a certain minimum number, then some of the observers can be added to the in-sync replica set. If this particular data center fails, you can also issue a command to manually promote some of the observers as the new leader. In this case, since the replication to the observer is asynchronous, you may lose a little bit of the data. But in the common case, the observer is pretty caught up with the new leader in real time. So the amount of data loss typically would be minimal. The multi-region cluster is super useful when the data centers are not too far apart from of each other. But in some cases, your geographic needs are maybe across continents. Maybe you have one data center in North America. You may have another data center in Europe. Now, what do you do in these cases? We have a few other solutions solving for those remote, far apart geographic locations. Kafka MirrorMaker 2 The first option we have is a tool from Apache Kafka. It is called Kafka MirrorMaker. And we have a version 2 of that. The way it works is it has a separate process that runs as a special connector within the Connect framework. So this special connector will read data from the source cluster. And then write that out into the topic in a separate output cluster. In this case, you will have separate clusters in each data center and the MirrorMaker is responsible for copying the data from the source to the target. This is pretty useful because now you don't have to worry about these two data centers being far apart from each other, because they are managed independently. But one of the tricky things with MirrorMaker is the offsets in general are not really preserved between these two clusters. Which means if you have a consumer application you want to fail over from one data center to another, you have to do some offset translation manually in the application. Another tool we have is from Confluent, Confluent Replicator it's called Replicator. This tool improves the MirrorMaker tool in two categories. The first thing is when you mirror the data from the source to the destination, in addition to mirroring the actual data, it'll also mirror some of the metadata such as topics, configuration and a number of partitions as well. The second improvement it adds is to solve some of those offset translation problem for you. In this mode, the offset in general, is still not preserved within the source cluster and the destination cluster but Replicator provides a tool that it can embed in your Java application which will do the offset translation automatically for you when you switch the consumer application from one data center to another. Confluent Cluster Linking The last tool I want to talk about from Confluent is Cluster Linking. This tool improves MirrorMaker and Replicator in a few other ways. The first way it differs from them is that there's no separate process as you can see. Is still has these two separate clusters, but the process of Cluster Linking is embedded in these source and destination clusters. So what's going to happen is the destination cluster will be embedded in the broker and it will keep pulling the data from the source broker into the target. Another key feature of Cluster Linking is it actually preserves offset. Because it copies data from the source partitions into the target partitions with exactly the same offset. This way, it makes the switching of the consumer for each application much easier because there's no need for doing offset translation. You can just seamlessly move your consumer application from the source cluster to the destination cluster. The last thing is that the process as you can see, is more efficient. First of all, there's no actual hop compared with if you had a separate process. The second thing is because it's using some of the internal methods to replicate data it actually avoids the need to recompress the data. For example, if the data is compressed, normally you will need to decompress data to read it out and then compress it back again when you publish it. But with the Cluster Linking, we can just copy the data as compressed and then directly add that to the destination cluster. It's actually much more efficient in terms of both CPU and network transfer. Another interesting feature with Cluster Linking Destination vs Source Initiated Cluster Linking is it has the option for you to decide from where to initiate the linking. Normally, the connection is initiated from the destination cluster to the source cluster. But in this case as you can see, the destination is in the cloud but the source cluster is in an on-prem data center. So if the link is initiated from the destination, it will require the on-prem cluster to open up its firewall so that the destination cluster can connect to it. This can be inconvenient for some use cases because people are always a little bit skeptical about opening a firewall for external usage. So another mode Cluster Linking supports is source initiated connections. So in this case, you can choose to have the source start opening a connection to the destination cluster. And once the destination cluster receives its connection, it can reverse this connection and use that to start pulling the data from the source to the destination. So they achieve the same thing, but it eliminates the need for the on-prem cluster to open up the firewall, which is a big security improvement. With all those choices, Geo-Replication Recap how do you choose among the different options when you think about replication? This table tries to summarize some of the differences among those different options. In general, if the two data centers you have are not too far from each other, the multi-region cluster can be your best choice because it supports both synchronous and asynchronous mode. And it also preserves offsets. If the two data centers are too far apart from each other, then the best option right now is Cluster Linking because it actually preserves the offset for you. And it also makes the replication process much more efficient. So that's the end of this module. And thanks for listening.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.