Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Data Plane: Replication Protocol



Jun Rao
Co-Founder, Confluent (Presenter)
Kafka Data Replication
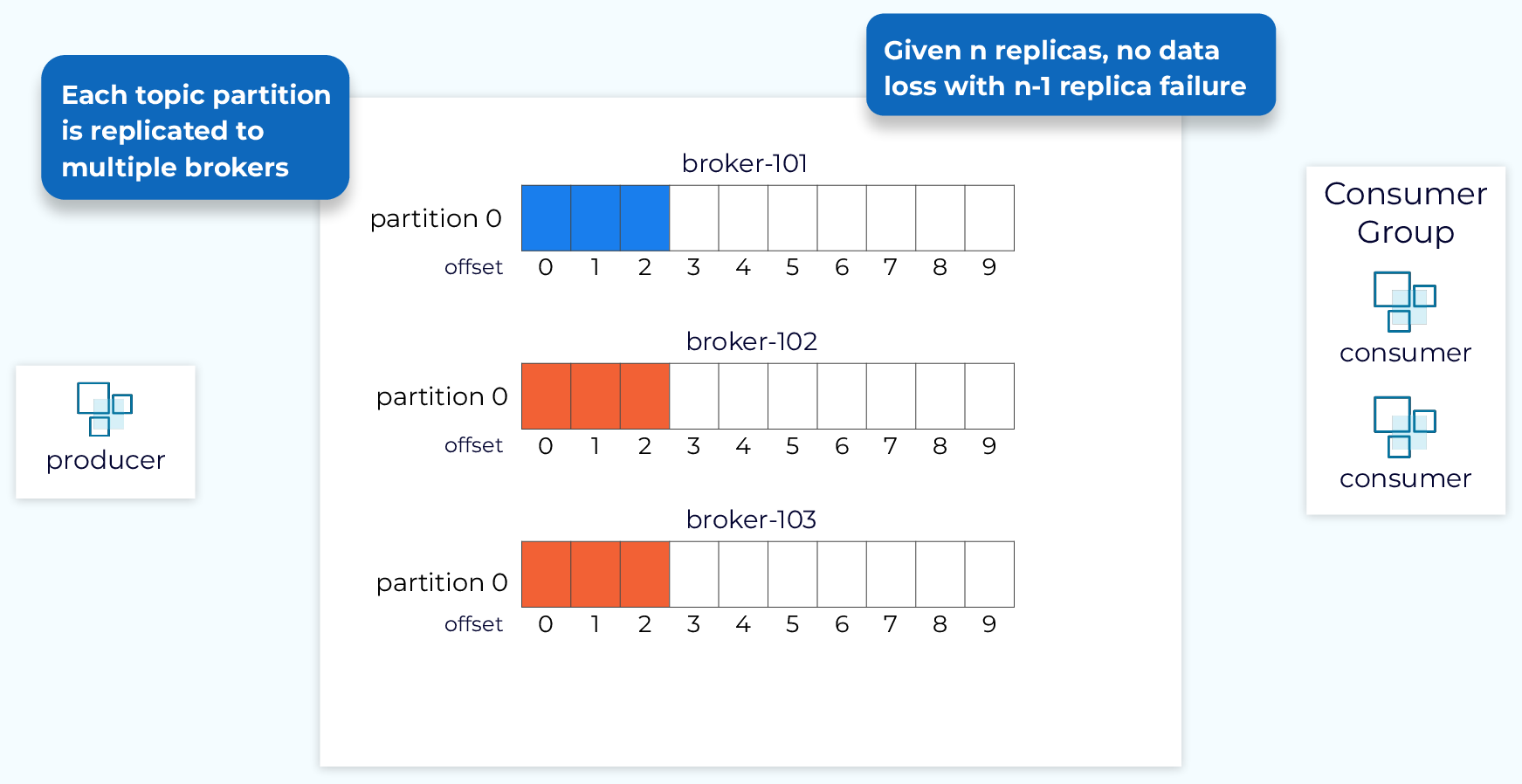
In this module we’ll look at how the data plane handles data replication. Data replication is a critical feature of Kafka that allows it to provide high durability and availability. We enable replication at the topic level. When a new topic is created we can specify, explicitly or through defaults, how many replicas we want. Then each partition of that topic will be replicated that many times. This number is referred to as the replication factor. With a replication factor of N, in general, we can tolerate N-1 failures, without data loss, and while maintaining availability.
Leader, Follower, and In-Sync Replica (ISR) List
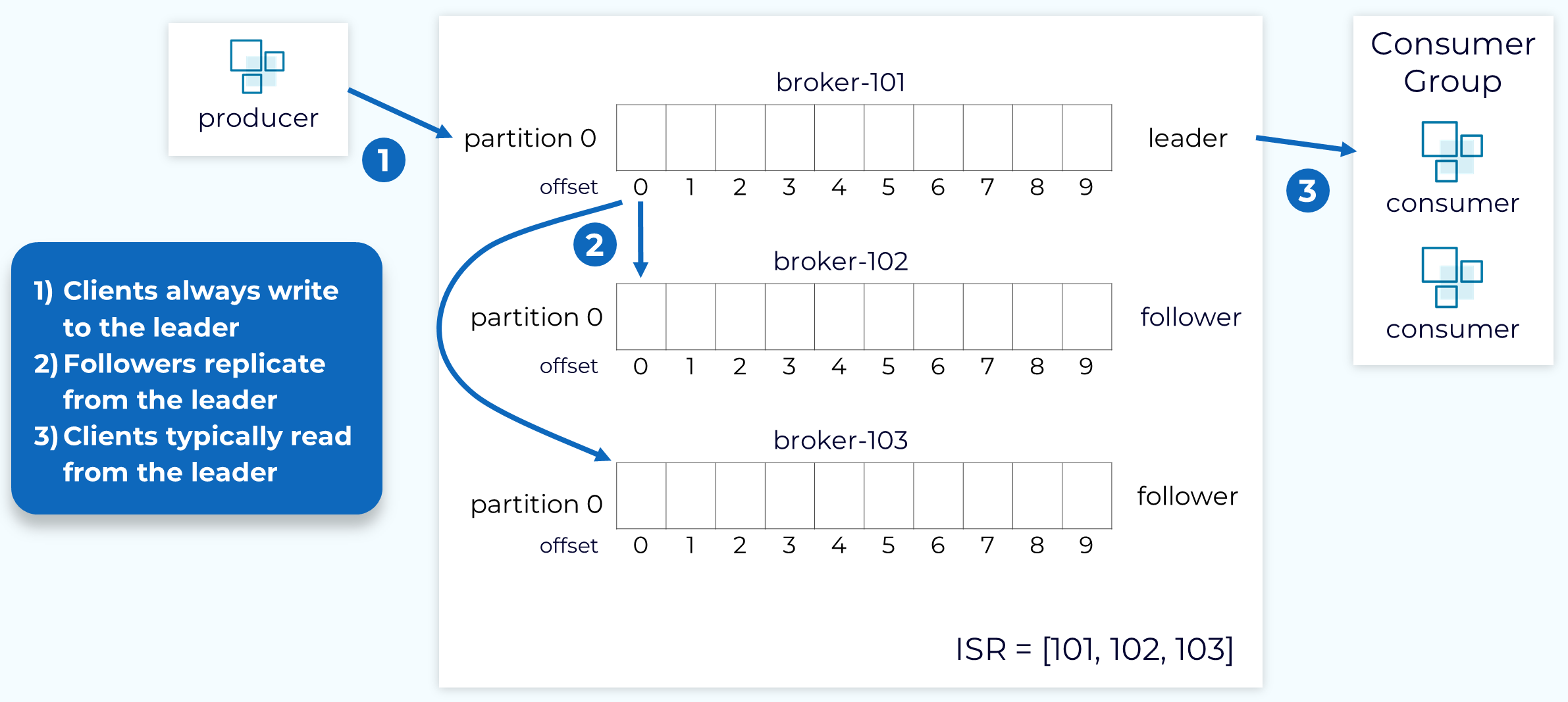
Once the replicas for all the partitions in a topic are created, one replica of each partition will be designated as the leader replica and the broker that holds that replica will be the leader for that partition. The remaining replicas will be followers. Producers will write to the leader replica and the followers will fetch the data in order to keep in sync with the leader. Consumers also, generally, fetch from the leader replica, but they can be configured to fetch from followers.
The partition leader, along with all of the followers that have caught up with the leader, will be part of the in-sync replica set (ISR). In the ideal situation, all of the replicas will be part of the ISR.
Leader Epoch
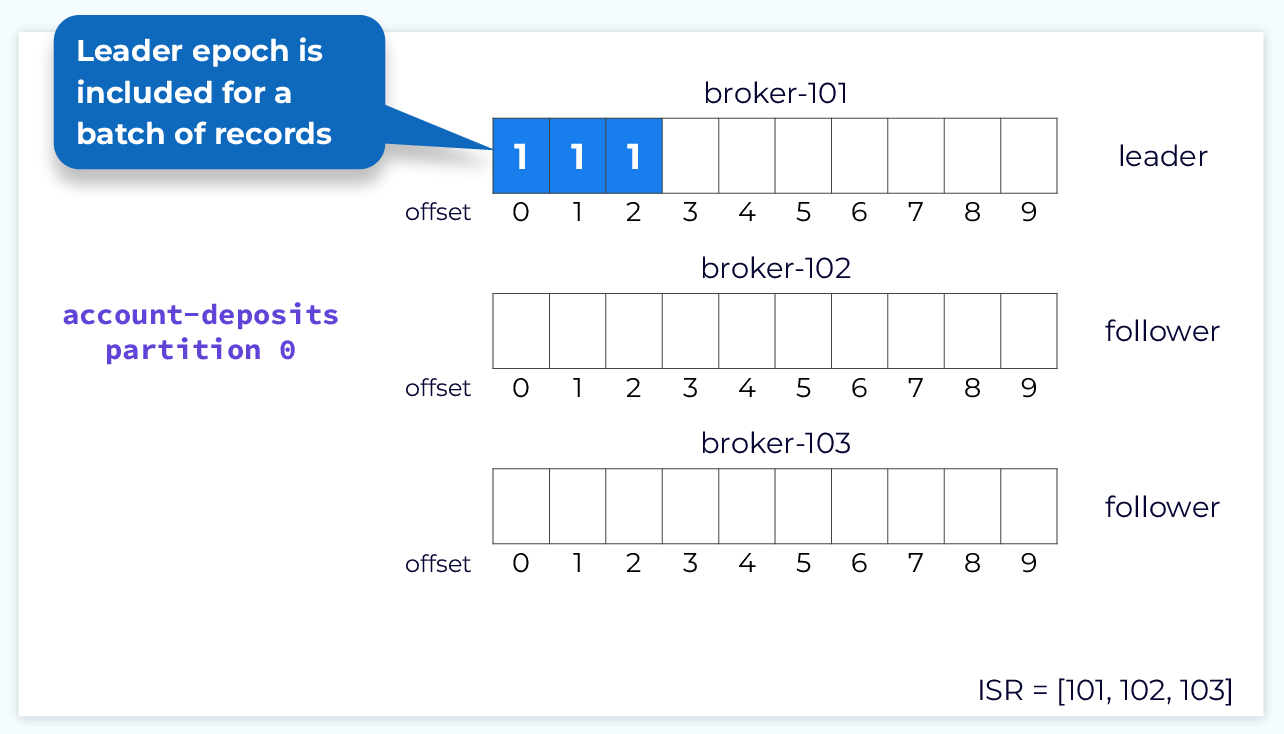
Each leader is associated with a unique, monotonically increasing number called the leader epoch. The epoch is used to keep track of what work was done while this replica was the leader and it will be increased whenever a new leader is elected. The leader epoch is very important for things like log reconciliation, which we’ll discuss shortly.
Follower Fetch Request
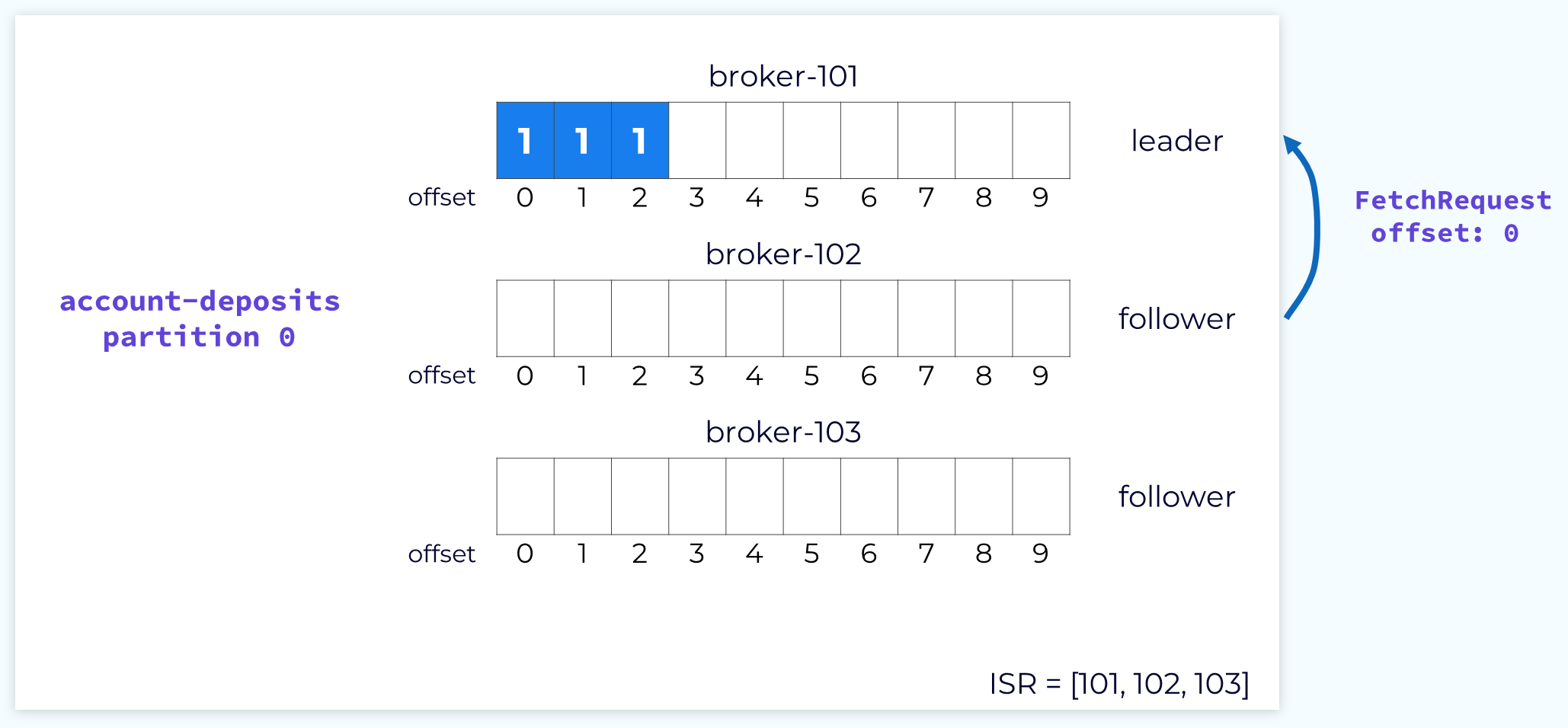
Whenever the leader appends new data into its local log, the followers will issue a fetch request to the leader, passing in the offset at which they need to begin fetching.
Follower Fetch Response
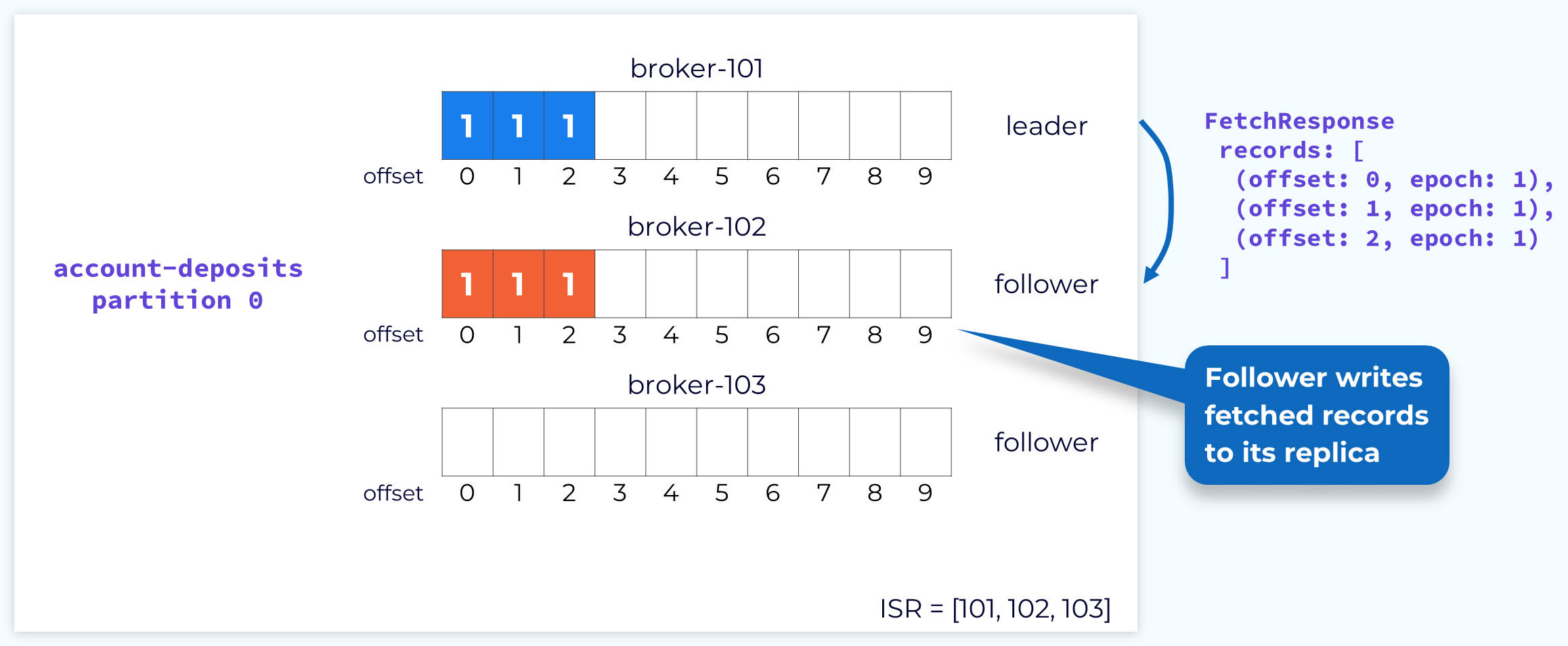
The leader will respond to the fetch request with the records starting at the specified offset. The fetch response will also include the offset for each record and the current leader epoch. The followers will then append those records to their own local logs.
Committing Partition Offsets
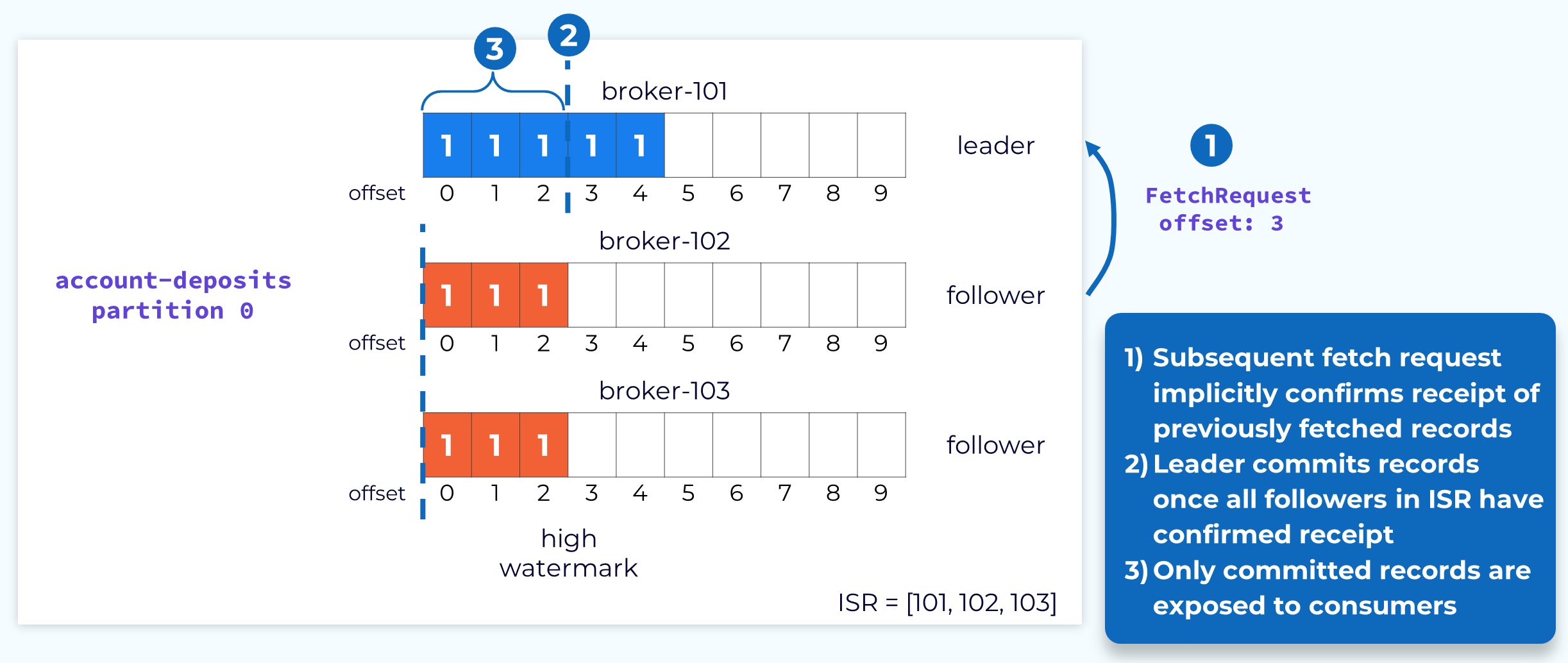
Once all of the followers in the ISR have fetched up to a particular offset, the records up to that offset are considered committed and are available for consumers. This is designated by the high watermark.
The leader is made aware of the highest offset fetched by the followers through the offset value sent in the fetch requests. For example, if a follower sends a fetch request to the leader that specifies offset 3, the leader knows that this follower has committed all records up to offset 3. Once all of the followers have reached offset 3, the leader will advance the high watermark accordingly.
Advancing the Follower High Watermark
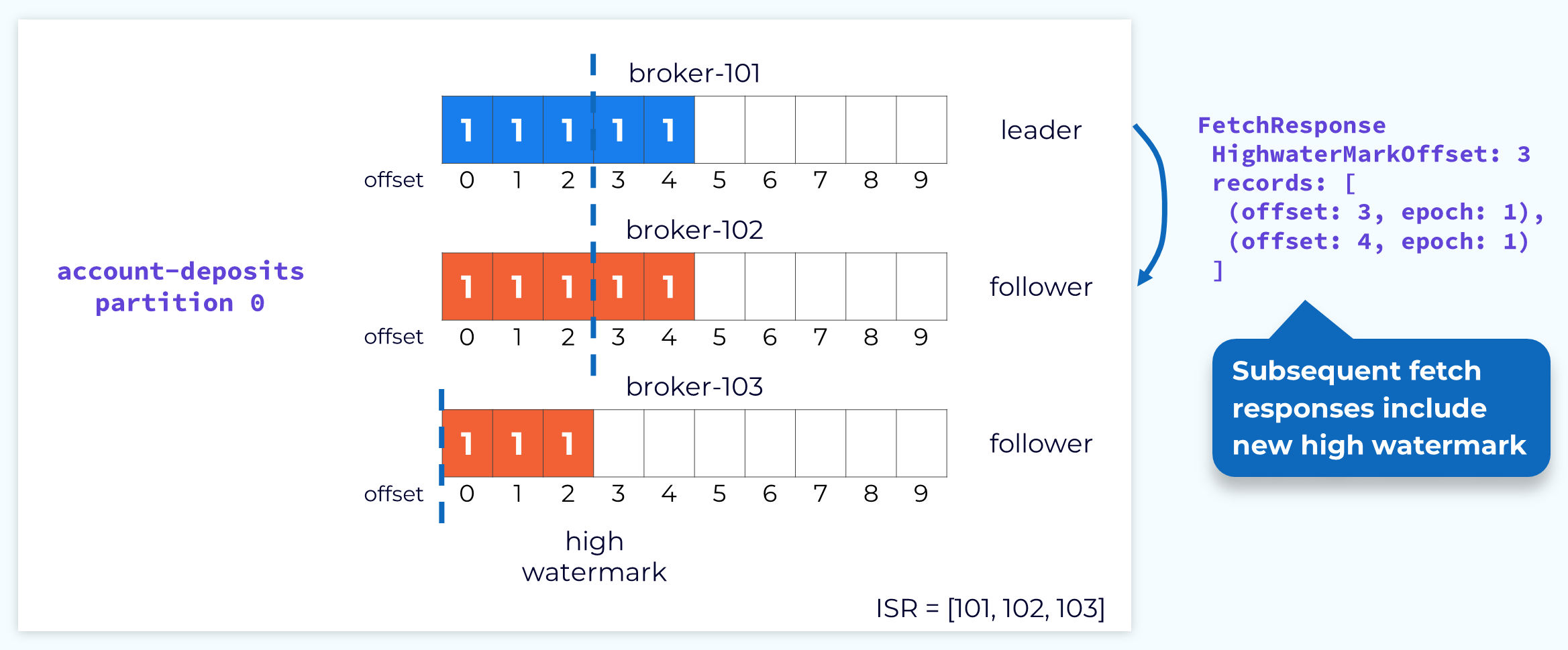
The leader, in turn, uses the fetch response to inform followers of the current high watermark. Because this process is asynchronous, the followers’ high watermark will typically lag behind the actual high watermark held by the leader.
Handling Leader Failure
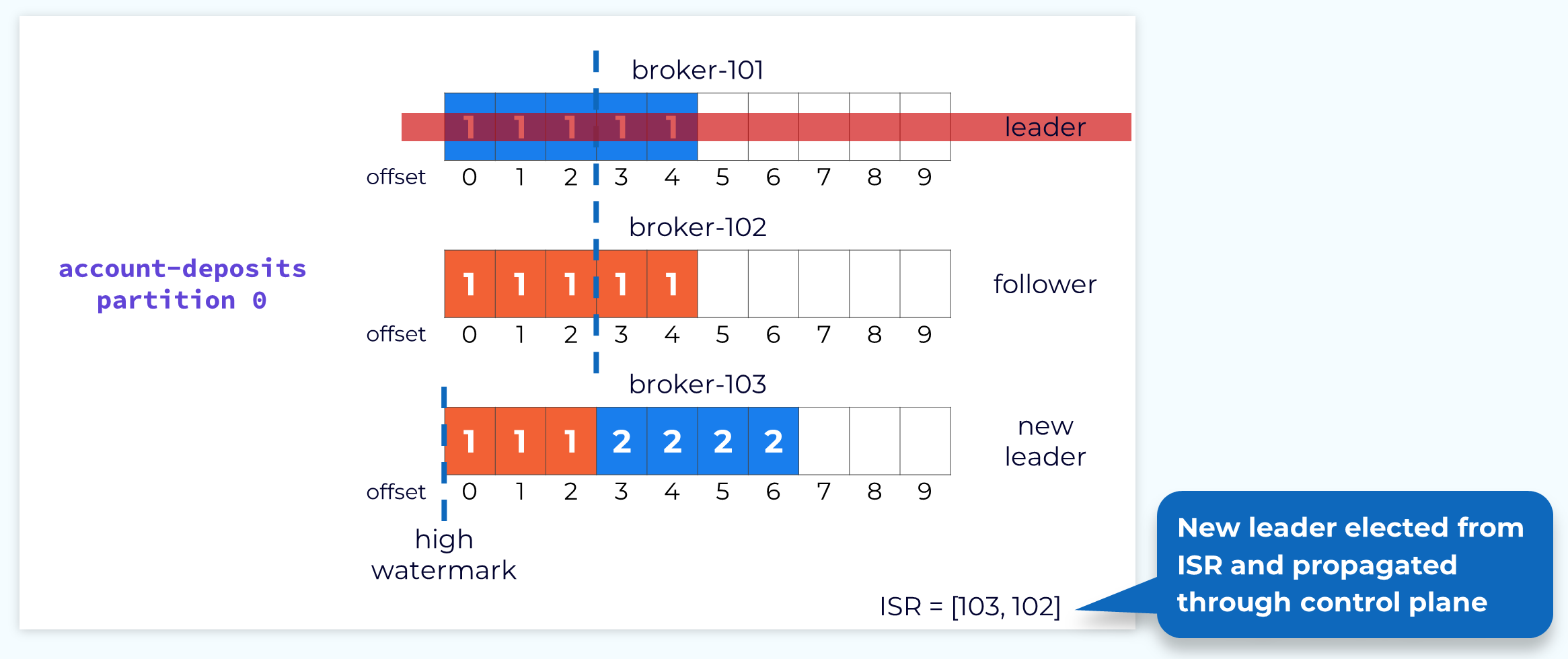
If a leader fails, or if for some other reason we need to choose a new leader, one of the brokers in the ISR will be chosen as the new leader. The process of leader election and notification of affected followers is handled by the control plane. The important thing for the data plane is that no data is lost in the process. That is why a new leader can only be selected from the ISR, unless the topic has been specifically configured to allow replicas that are not in sync to be selected. We know that all of the replicas in the ISR are up to date with the latest committed offset.
Once a new leader is elected, the leader epoch will be incremented and the new leader will begin accepting produce requests.
Temporary Decreased High Watermark
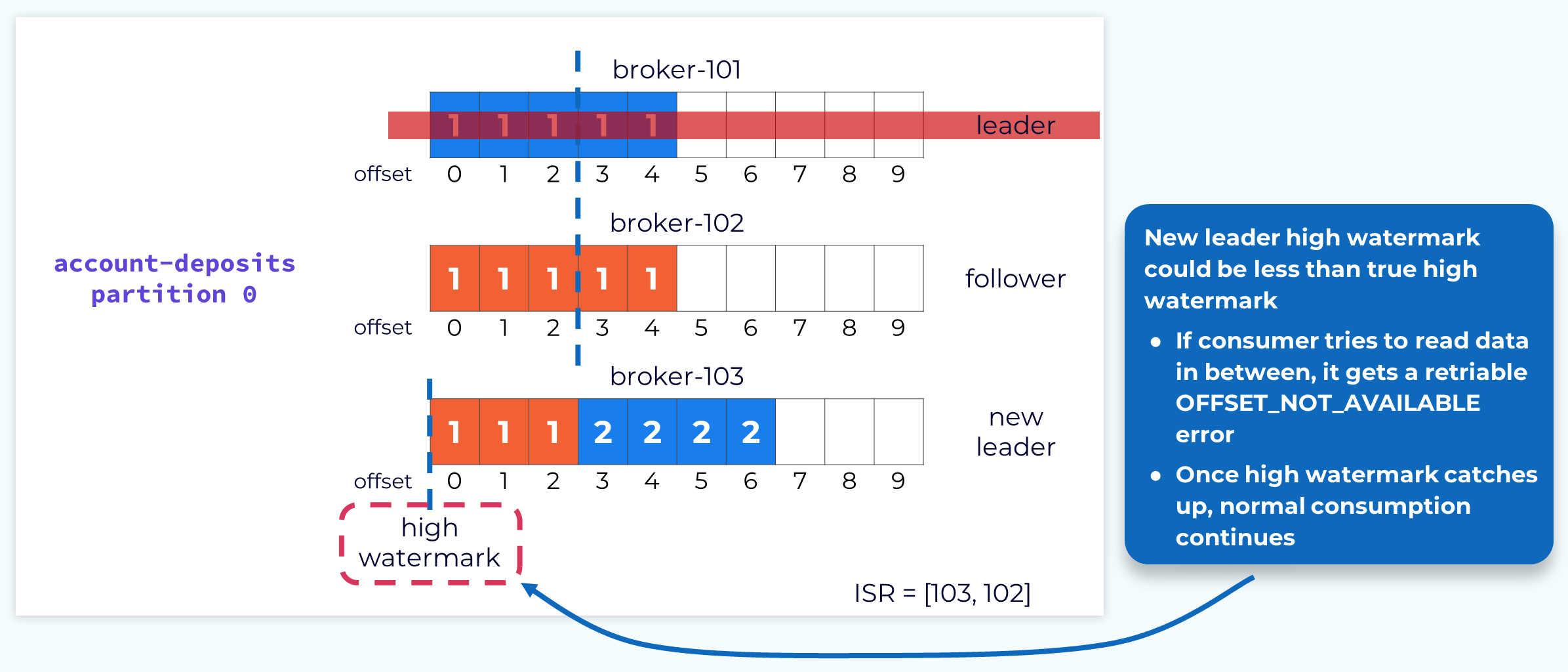
When a new leader is elected, its high watermark could be less than the actual high watermark. If this happens, any fetch requests for an offset that is between the current leader’s high watermark and the actual will trigger a retriable OFFSET_NOT_AVAILABLE error. The consumer will continue trying to fetch until the high watermark is updated, at which point processing will continue as normal.
Partition Replica Reconciliation
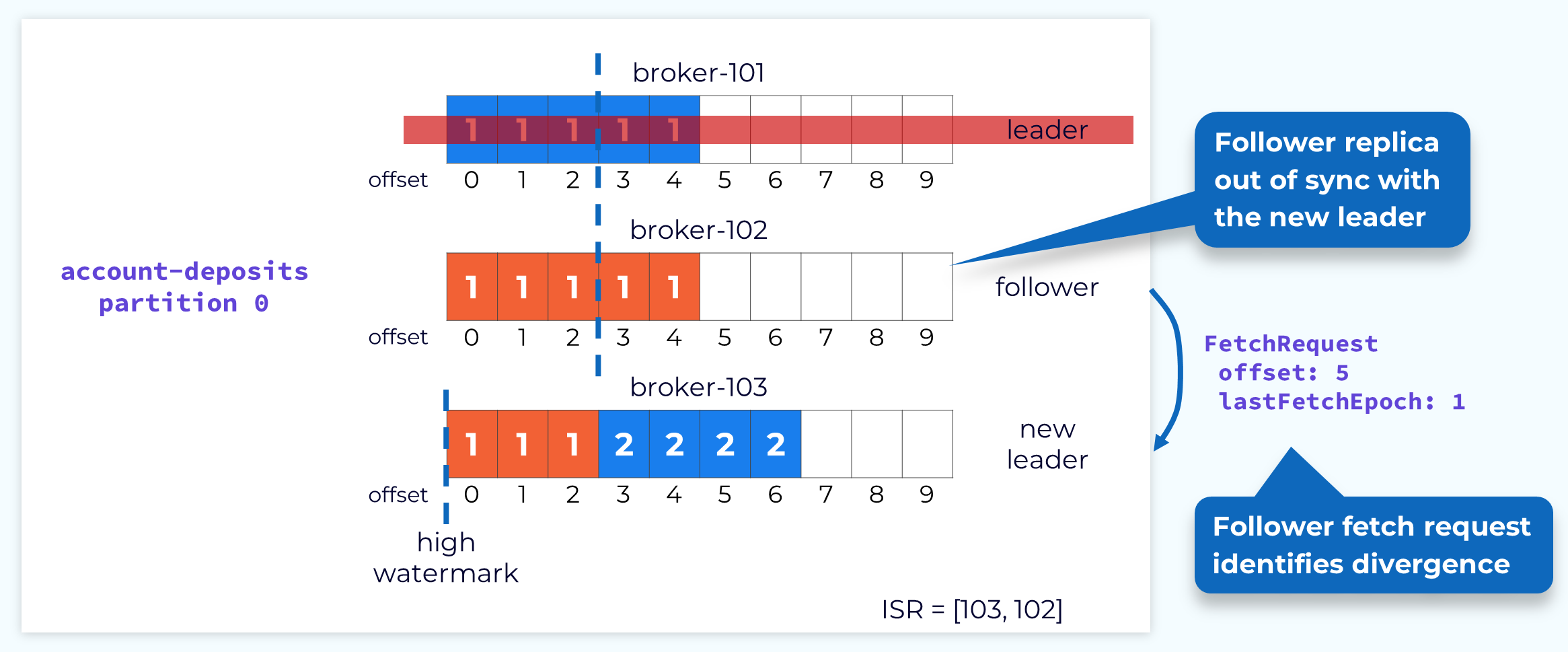
Immediately after a new leader election, it is possible that some replicas may have uncommitted records that are out of sync with the new leader. This is why the leader's high watermark is not current yet. It can’t be until it knows the offset that each follower has caught up to. We can’t move forward until this is resolved. This is done through a process called replica reconciliation. The first step in reconciliation begins when the out-of-sync follower sends a fetch request. In our example, the request shows that the follower is fetching an offset that is higher than the high watermark for its current epoch.
Fetch Response Informs Follower of Divergence
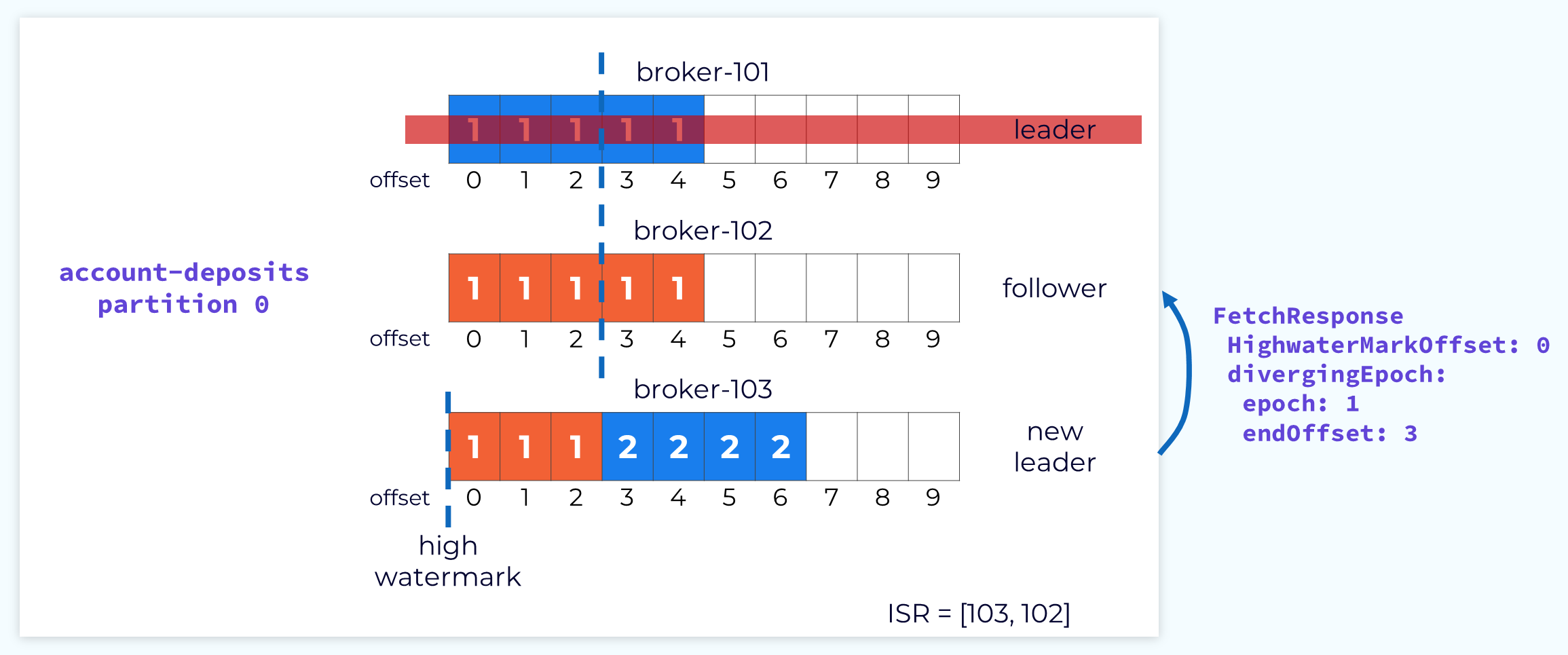
When the leader receives the fetch request it will check it against its own log and determine that the offset being requested is not valid for that epoch. It will then send a response to the follower telling it what offset that epoch should end at. The leader leaves it to the follower to perform the cleanup.
Follower Truncates Log to Match Leader Log
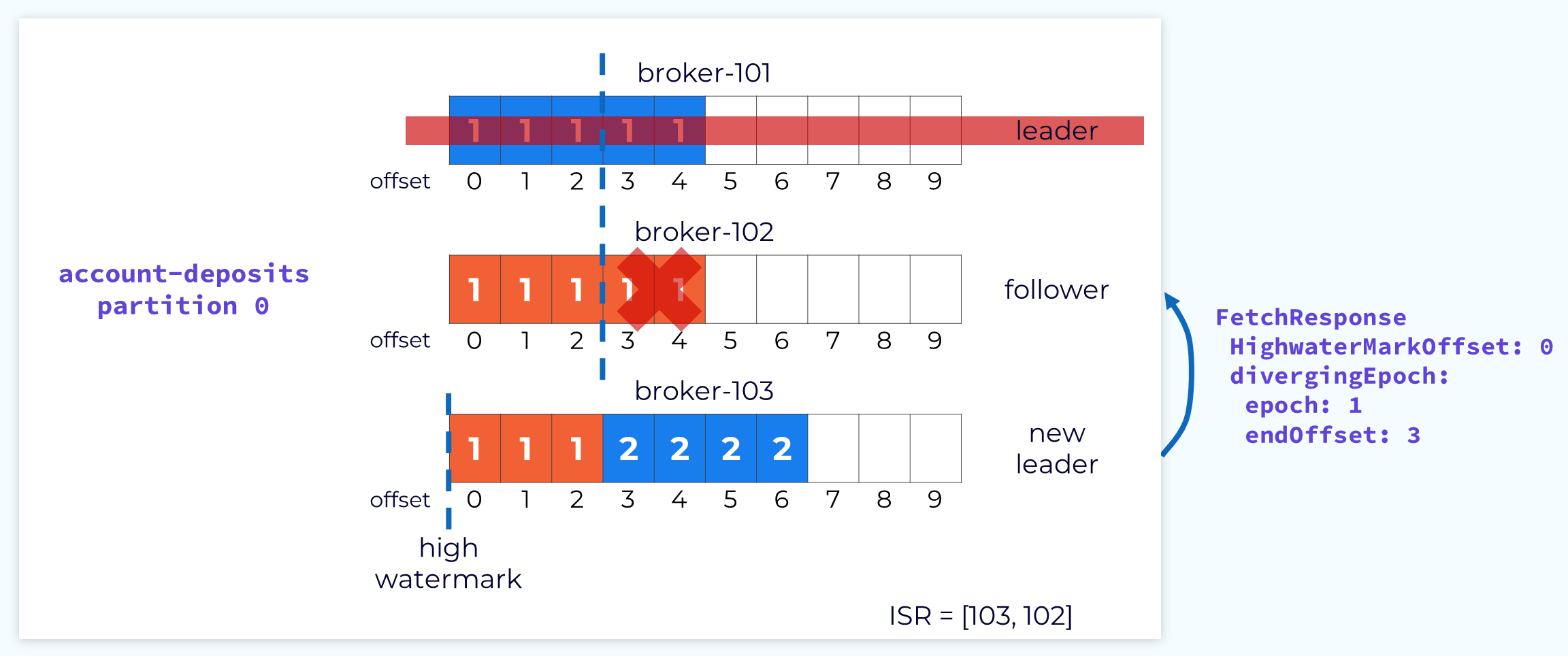
The follower will use the information in the fetch response to truncate the extraneous data so that it will be in sync with the leader.
Subsequent Fetch with Updated Offset and Epoch
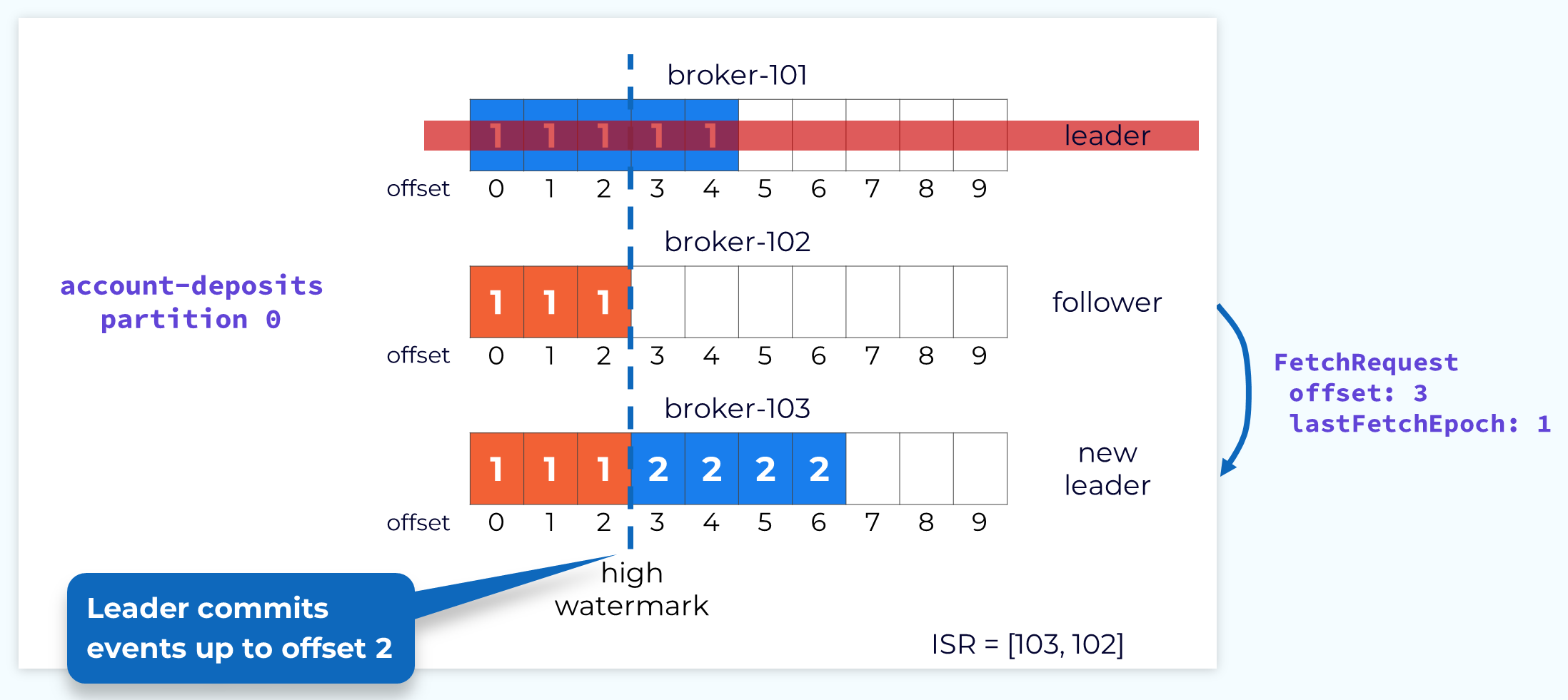
Now the follower can send that fetch request again, but this time with the correct offset.
Follower 102 Reconciled
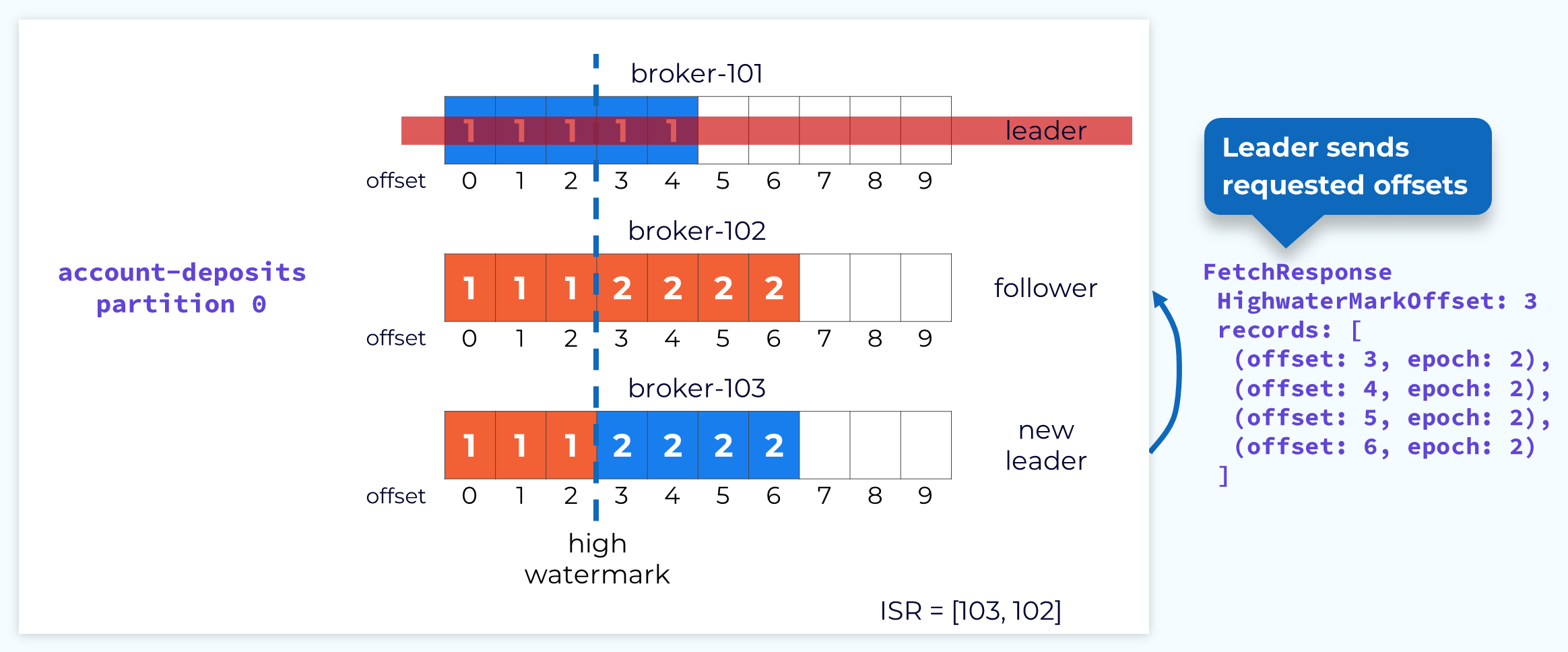
The leader will then respond with the new records since that offset includes the new leader epoch.
Follower 102 Acknowledges New Records
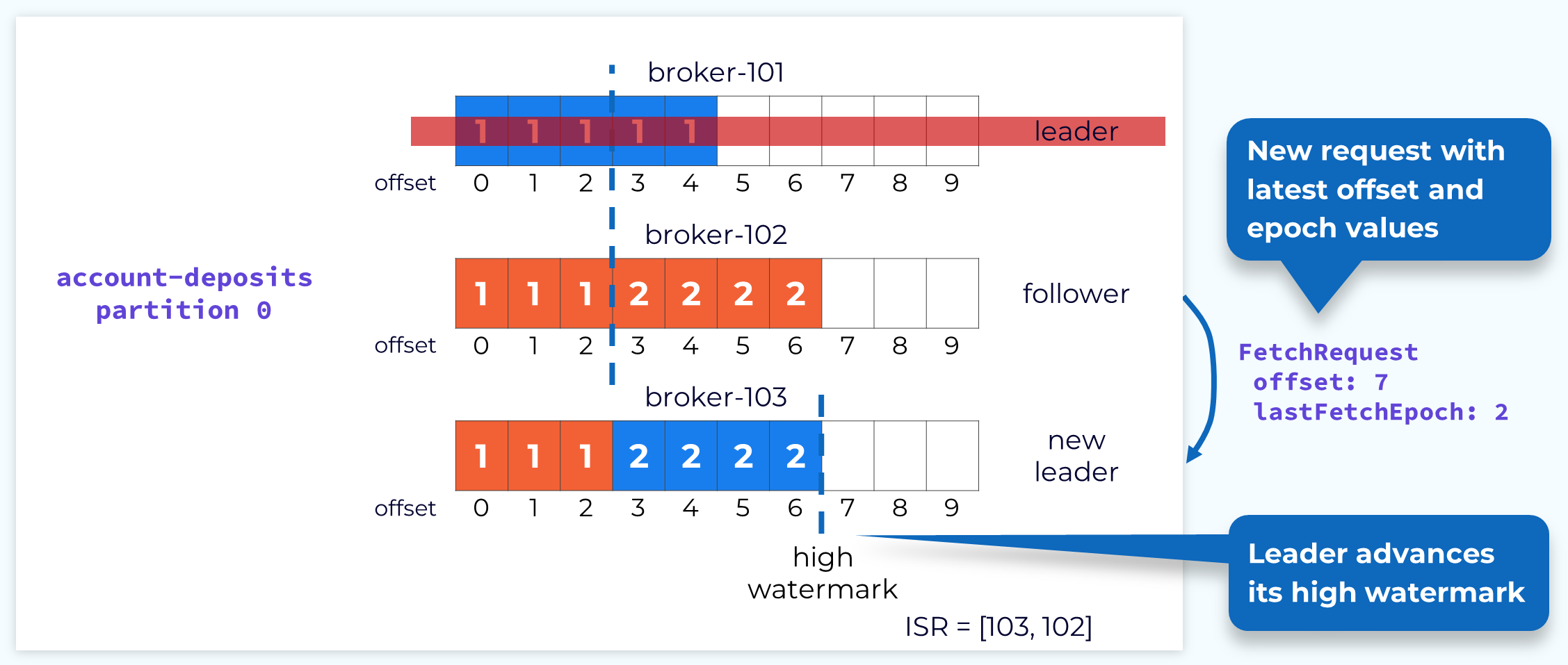
When the follower fetches again, the offset that it passes will inform the leader that it has caught up and the leader will be able to increase the high watermark. At this point the leader and follower are fully reconciled, but we are still in an under replicated state because not all of the replicas are in the ISR. Depending on configuration, we can operate in this state, but it’s certainly not ideal.
Follower 101 Rejoins the Cluster
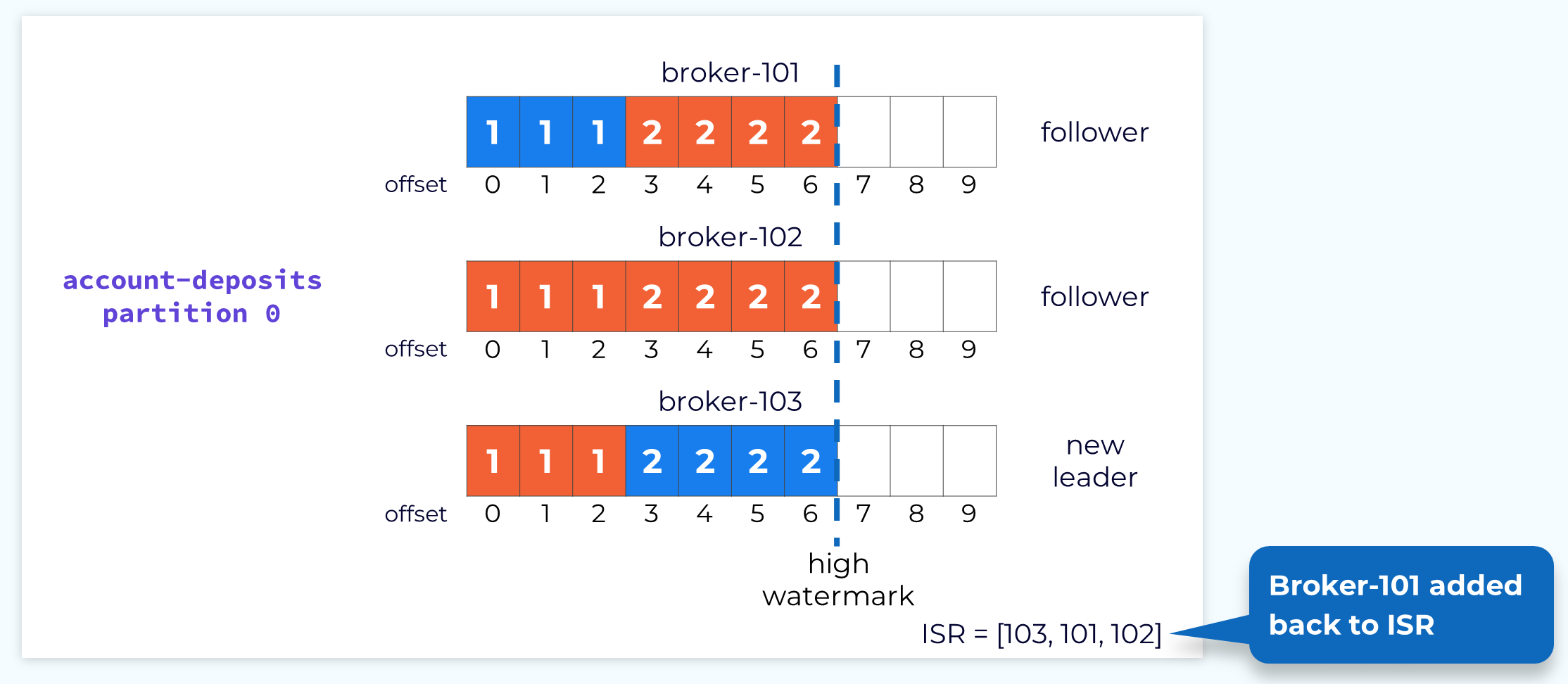
At some point, hopefully soon, the failed replica broker will come back online. It will then go through the same reconciliation process that we just described. Once it is done reconciling and is caught up with the new leader, it will be added back to the ISR and we will be back in our happy place.
Handling Failed or Slow Followers
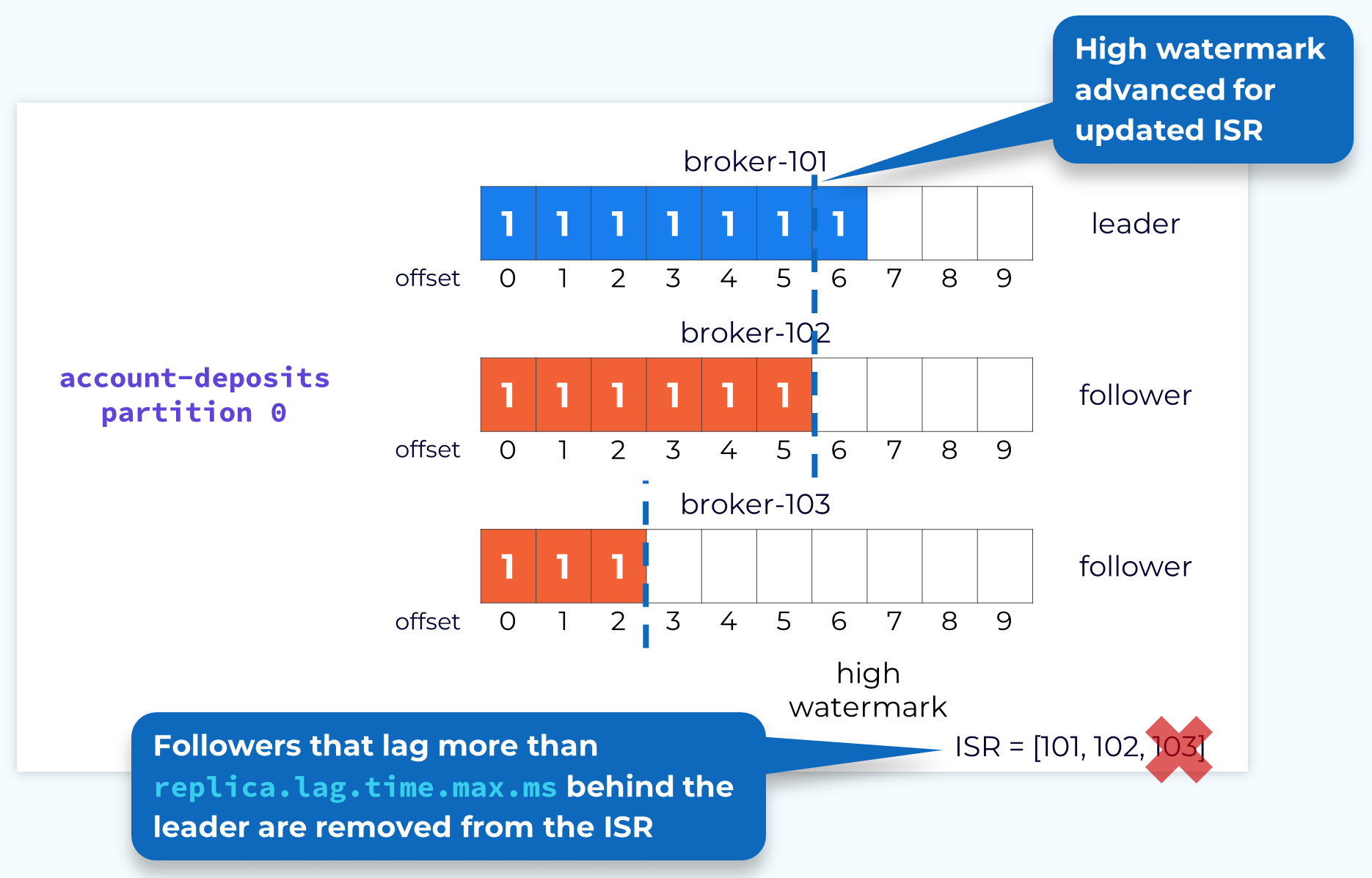
Obviously when a leader fails, it’s a bigger deal, but we also need to handle follower failures as well as followers that are running slow. The leader monitors the progress of its followers. If a configurable amount of time elapses since a follower was last fully caught up, the leader will remove that follower from the in-sync replica set. This allows the leader to advance the high watermark so that consumers can continue consuming current data. If the follower comes back online or otherwise gets its act together and catches up to the leader, then it will be added back to the ISR.
Partition Leader Balancing
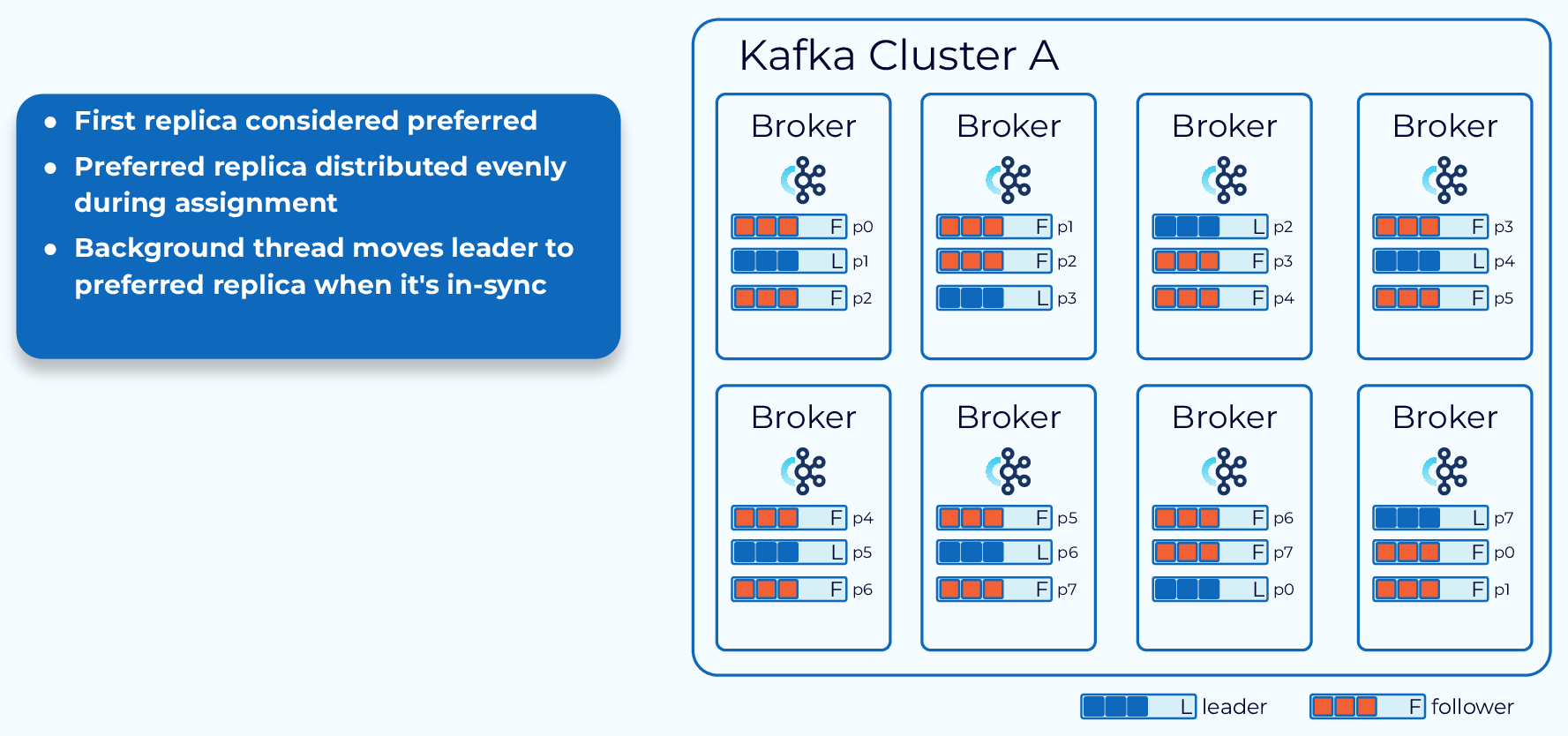
As we’ve seen, the broker containing the leader replica does a bit more work than the follower replicas. Because of this it’s best not to have a disproportionate number of leader replicas on a single broker. To prevent this Kafka has the concept of a preferred replica. When a topic is created, the first replica for each partition is designated as the preferred replica. Since Kafka is already making an effort to evenly distribute partitions across the available brokers, this will usually result in a good balance of leaders.
As leader elections occur for various reasons, the leaders might end up on non-preferred replicas and this could lead to an imbalance. So, Kafka will periodically check to see if there is an imbalance in leader replicas. It uses a configurable threshold to make this determination. If it does find an imbalance it will perform a leader rebalance to get the leaders back on their preferred replicas.
Use the promo code INTERNALS101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Data Plane: Replication Protocol
Hey everyone, Jun Rao from Confluent. In this module, we're going to talk about how Kafka replicates data in the data plane. Earlier I mentioned that within a Kafka cluster, we have this control plane and the data plane and in this particular case, we're going to talk about how the data plane handles data replication. Replication is a pretty critical feature within Kafka. Kafka Data Replication It's a critical feature to enable higher durability and availability and it's used to build mission-critical applications on top of Kafka. Enabling replication is actually pretty easy. So when you create a topic, you can specify how many replicas you want to have. Once you specify the number, then all of the partitions in the topic will be created with the number of replicas. If you create a replication factor of N, in general we can tolerate N-1 failures. Here are a few key concepts with replication. Leader, Follower, and In-Sync Replica (ISR) List Once you have created those replicas, one of the replicas will be designated as the leader of that partition and the rest of the replicas are called followers. The producer will first send this data to the leader and from there, all the followers will retrieve the data from the leader and the consumer typically reads data from the leader but as we'll see later on, it can be configured to consume data from a follower as well. Another key concept in Kafka is called in-sync replicas or ISR. Intuitively, ISR is a set of data that captures all of the replicas that have fully caught up with the leader. In the normal case when all the replicas are live and are healthy, all of the replicas will be part of ISR or the in-sync replicas. Each of the leaders is also associated with a leader epoch. Leader Epoch So this is actually a unique number that's monotonically increasing and it's used to capture the generation of the lifetime of a particular leader. So every time when a leader takes the data from the produce request to write to its local log, it needs to check all the records of dispatch with its leader epoch. As we'll see later on, this leader epoch is pretty critical and important for doing log reconciliation among all the replicas. Follower Fetch Request So once the leader has appended the produced data into its local log, all the followers will be trying to retrieve the new data from the leader. A follower does that by issuing a fetch request to the leader, including the offset from which it needs to fetch data. After the leader receives this data request, Follower Fetch Response the leader will be returning the new records from that particular offset to the follower. Once the follower receives a response, it'll be appending those new records in its own local log. As you can see, as the follower is appending the data to its local log, it keeps the same leader epoch included in those record batches. We need a way to commit the offsets, meaning that those records have been considered safe. In Kafka, the way we commit those records is defined by once a particular record is included in all the in-sync replicas, then the record is considered committed and then can be safely returned to the consumer. So now, how does the leader know whether a particular follower has received a particular record? This is actually piggybacked on the fetch request from the follower. So by sending a fetch request from a particular offset, in this case offset three, the leader knows that the follower has received all of the records up to offset three. And in this case, if both followers are doing the same thing of issuing fetch requests at offset three, then the leader will know that all of the records, zero, one, and two have been received by all of the replicas in this in-sync replica set and those records can be considered as committed. The way we model committed records is through this concept called high watermark. It marks the offset before which all the records are considered as committed. In this case, it will advance the high watermark on the leader to offset three after the fetch requests have gone through at offset three. All the records up to the high watermark are exposed to the consumer. Once the leader has advanced the high watermark, Advancing the follower High Watermark it will also need to propagate this information to the followers. This is done by piggybacking in the fetch response. As you can see here in the fetch response, the leader will also include the latest high watermark to the follower. As you can see, since this is done asynchronously, the follower's high watermark typically is a little bit behind the true high watermark of the leader. Now let's talk about how we handle leader failure. Handling Leader Failure Let's say in this case, the old leader, broker-101, has failed. We need a way to elect the new leader. The leader election in Kafka for the data plan is pretty simple because through the protocol, we know all the replicas that are in ISR, all of those in-sync replicas have all of the previously committed records. So we can pick any of those replicas in ISR as the new leader. In this case, both controller 102 and 103 can be the new leader. Let's say we picked 103 as the new leader. This information will be propagated through the control plane. Once replica 103 notices that it's the new leader, it can start taking new requests from the producer. As you can see, for the new produce request, it'll be tagged with a new bumped up leader epoch, which is two. If you are careful, you will notice Temporary Decreased High Watermark there's a subtle issue with the high watermark once a new leader is elected. As you can see, the high watermark in this new leader is actually less than the true high watermark in the previous leader. Now what happens if a consumer is issuing a fetch request in this time window asking for offsets in the middle, let's say offset one? In this case, we don't want to send a response to give the consumer the wrong indication that its request is invalid because this is transient and temporary. So instead what we do is we'll be issuing a retryable error back to the consumer client so that it can keep retrying until this high watermark catches up to the true high watermark. This should be done pretty quickly. Once a new leader is elected, some of the followers Partition Replica Reconciliation may need to reconcile their data with the new leader. As you can see in this case, the follower on broker-102, it actually has some data in offsets three and four. Those are actually the records that never committed and you can see they are actually quite different from the corresponding records in the new leader. So we need to have a way to clean those records. This is done through the replication reconciliation logic. The way we do this is through another detail in the fetch request. When the follower is issuing a fetch request, in addition to the offset from which it wants to fetch data, it also includes the latest epoch it has seen in its local log. In this case, it's epoch one. Once the leader receives the fetch request, Fetch Response Informs Follower of Divergence it will use the epoch information to check the consistency with its local log. In this case, it realized that within its local log, epoch one really ends at offset two instead of the offset four indicated by the follower. So the leader will send a response indicating to the follower that you really need to make the log consistent with respect to epoch one. In this case where epoch one really ends before offset three. When a follower receives this fetch response from Follower Truncates Log To Match Leader Log the leader, it will know it needs to truncate the data at offset three and four and at this point, the data is consistent with the leader up to offset two. Next, the follower issues the next fetch Subsequent Fetch with Updated Offset & Epoch request starting with offset three with the last epoch one. Once the leader receives it, it notices this is actually consistent with its local log and this will cause its local high watermark to be advanced to offset three. Next, the leader will be returning new data Follower 102 Reconciled back to the follower and the follower will take this data and then append that to its local log. Then the follower will fetch again Follower 102 Acknowledges New Records with the latest offset or offset seven. This will cause the high watermark in the leader to be advanced to offset seven. Now this completes the reconciliation between the follower's log and the leader's log. Now you can see they are identical. At this point, we are still in this under- replicated mode because not all the replicas are in ISR. At some point, this failed replica on broker 101 Follower 101 Rejoins the Cluster will come back and it will catch up from the leader and will go through a similar reconciliation logic as replica 102 and eventually it will catch up all the way to the end of the log and then it will be added back to ISR. Now we are back into the fully replicated mode. Now let's take a look at how follower failure is handled Handling Failed or Slow Followers since sometimes a follower can fail or sometimes maybe a follower is slow. It can't catch up with the leader. In this case, if we keep waiting for that follower, then we'll never be able to advance the high watermark. So what we do instead is the leader will keep monitoring the progress of the follower. It will measure, what's the last time this particular follower has caught up all the way with the leader? And if it's lagging by more than a configured amount of time based on this property, then this follower is considered out of sync. Then it will be dropped out of ISR. At that point, the leader can now advance the high watermark based on the reduced in-sync replica set. This is how we handle the follower failure. Partition Leader Balancing The last thing I want to talk about is balancing the load of the leaders. As you can see, the leader replica typically does a little bit more work than the followers because all the followers are fetching data directly from the leader. So in a healthy cluster, we want the load on all the leaders to be balanced. This is achieved through a concept called preferred replica. So when you create a topic, we'll designate the first replica of each partition as the preferred replica. So when we assign the preferred replica, we try to assign it in such a way that the preferred replica will be distributed evenly among all of those brokers. So when we do the leader election, what we try to do is to periodically look at it to see if the preferred replica is healthy and then whether the current leader is on the preferred one. If not, we'll try to move the leader back to the preferred replica. So in the end, all of the leaders will be moved onto the preferred replica since these are evenly distributed among all the brokers, we can achieve a balanced load among the leaders in the cluster as well. This is the end of this module and thanks for listening.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.