Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
The Fundamentals of Apache Kafka Architecture



Jun Rao
Co-Founder, Confluent (Presenter)
Overview of Apache Kafka Architecture
Apache Kafka® is a data streaming system that allows developers to react to new events as they occur in real time. Although Kafka is often compared with message queues, its message broker architecture allows it to go beyond basic messaging capabilities to handle large volumes of data and build fault-tolerant applications and systems.
This course will give you an in-depth introduction to Kafka internals and its architecture, which consists of a storage layer and a compute layer.
Want to focus on Kafka fundamentals first? Take the free Kafka 101 course.
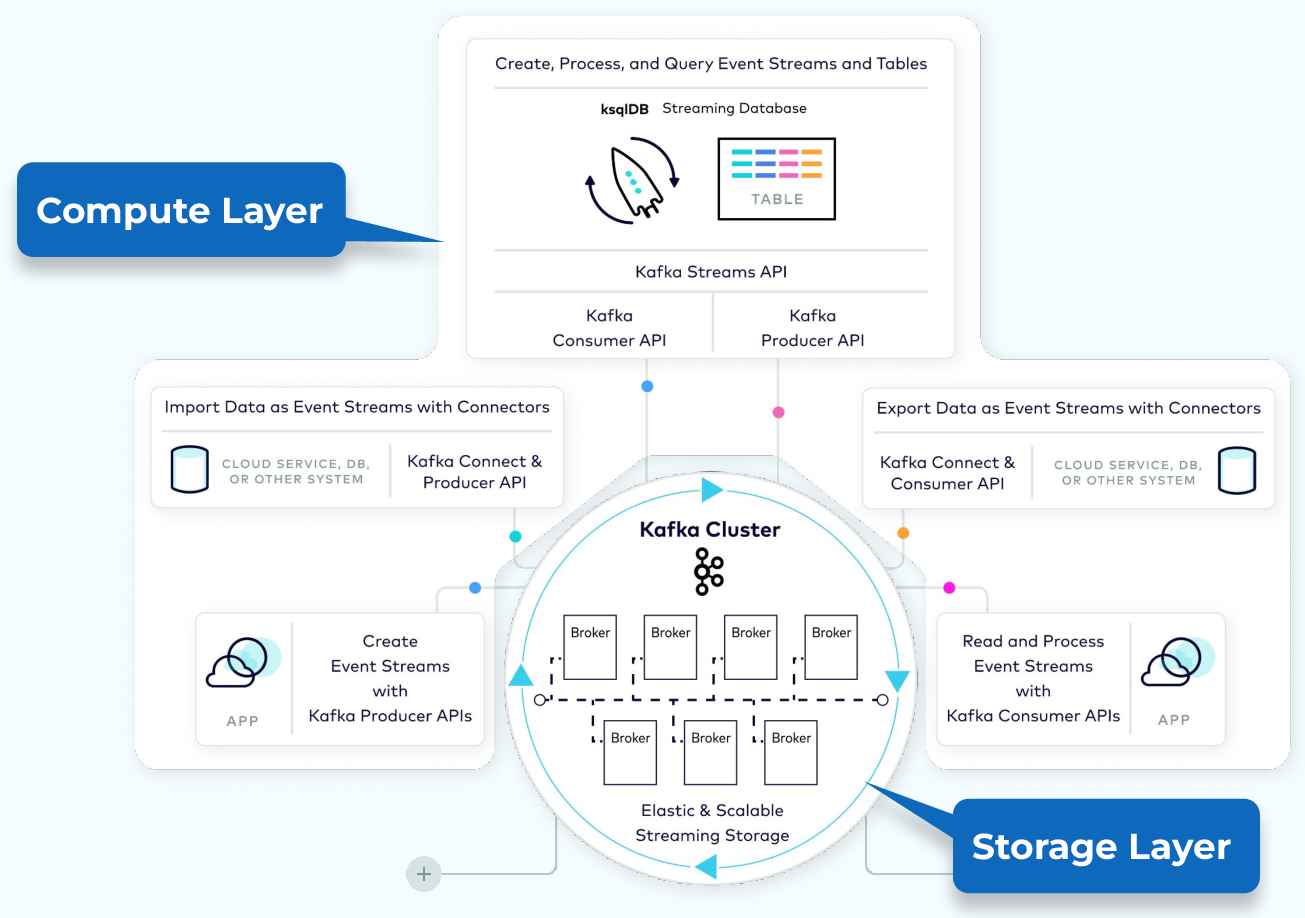
The storage layer is designed to store data efficiently and is a distributed system such that if your storage needs grow over time you can easily scale out the system to accommodate the growth. The compute layer consists of four core components—the producer, consumer, Kafka Streams, and Connect APIs, which allow Kafka to scale applications across distributed systems.
In this guide, we’ll delve into each component of Kafka’s design and how Kafka works internally.
Producer and Consumer APIs
The foundation of Kafka’s powerful application layer is two primitive APIs for accessing the storage layer—the producer API for writing events and the consumer API for reading them. On top of these are additional APIs built for integration and processing via Kafka Connect and Kafka Streams.
Kafka Connect
Kafka Connect, which is built on top of the producer and consumer APIs, provides a simple way to integrate data across Kafka and external systems. Source connectors bring data from external systems and produce it to Kafka topics. Sink connectors take data from Kafka topics and write it to external systems.
Kafka Streams
For processing events as they arrive, we have Kafka Streams, a Java library that is built on top of the producer and consumer APIs. The Kafka Streams architecture allows you to perform real-time stream processing, powerful transformations, and aggregations of event data on top of Kafka, simplifying application development.
ksqlDB
Building on the foundation of Kafka Streams, we also have ksqlDB, a streaming database which allows for similar processing but with a declarative SQL-like syntax.
What Is an Event in Stream Processing?
An event is a record of something that happened that also provides information about what happened. Examples of events are customer orders, payments, clicks on a website, or sensor readings. An event shouldn’t be too large. A 10GB video is not a good event. A reference to the location of that video in an object store is.
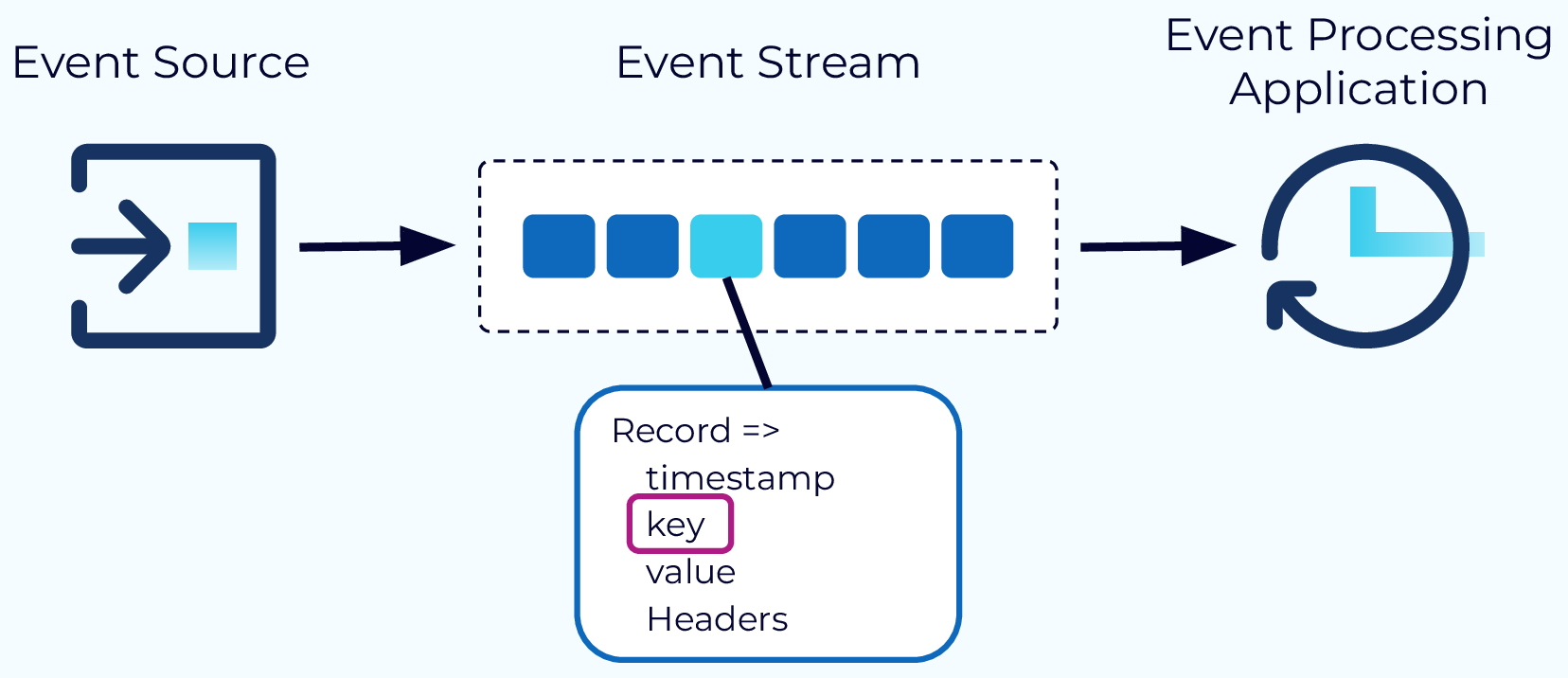
In a Kafka-based architecture, an event record consists of a timestamp, a key, a value, and optional headers. The event payload is usually stored in the value. The key is also optional, but very helpful for event ordering, colocating events across topics, and key-based storage or compaction.
Record Schema
In Kafka, the key and value are stored as byte arrays which means that clients can work with any type of data that can be serialized to bytes. A popular format among Kafka users is Avro, which is also supported by Confluent Schema Registry.
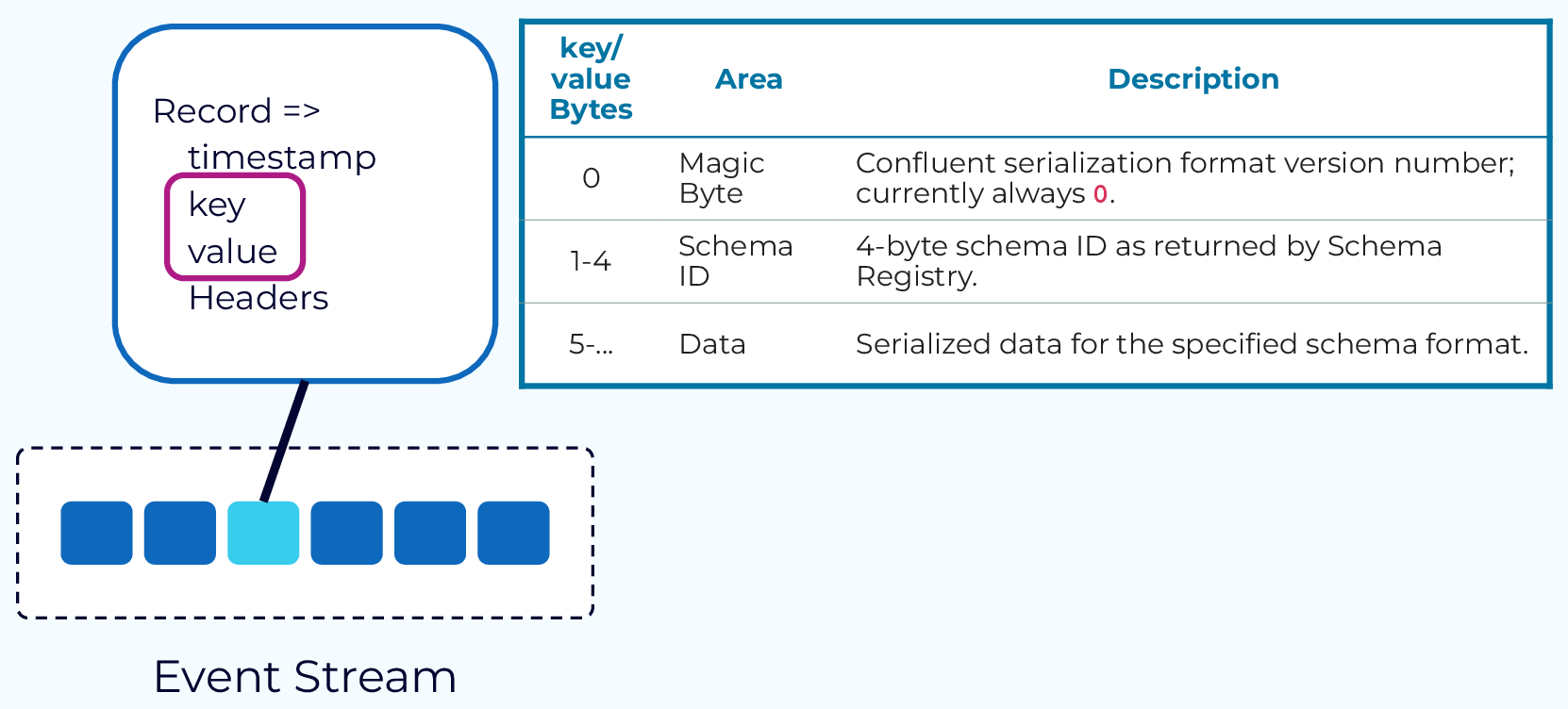
When integrated with Schema Registry, the first byte of an event will be a magic byte which signifies that this event is using a schema in the Schema Registry. The next four bytes make up the schema ID that can be used to retrieve the schema from the registry, and the rest of the bytes contain the event itself. Schema Registry also supports Protobuf and JSON schema formats.
Kafka Topics
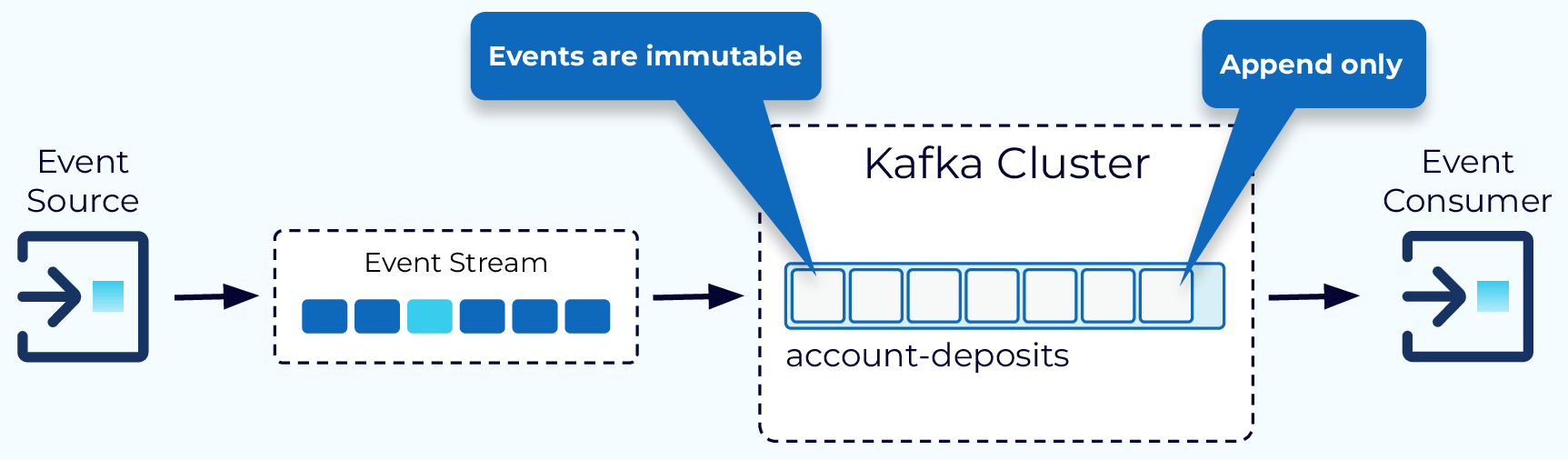
A key concept in Kafka is the topic. Topics are append-only, immutable logs of events. Typically, events of the same type, or events that are in some way related, would go into the same topic. Kafka producers write events to topics and Kafka consumers read from topics.
Kafka Topic Partitions
In order to distribute the storage and processing of events in a topic, Kafka uses the concept of partitions. A topic is made up of one or more partitions and these partitions can reside on different nodes in the Kafka cluster.
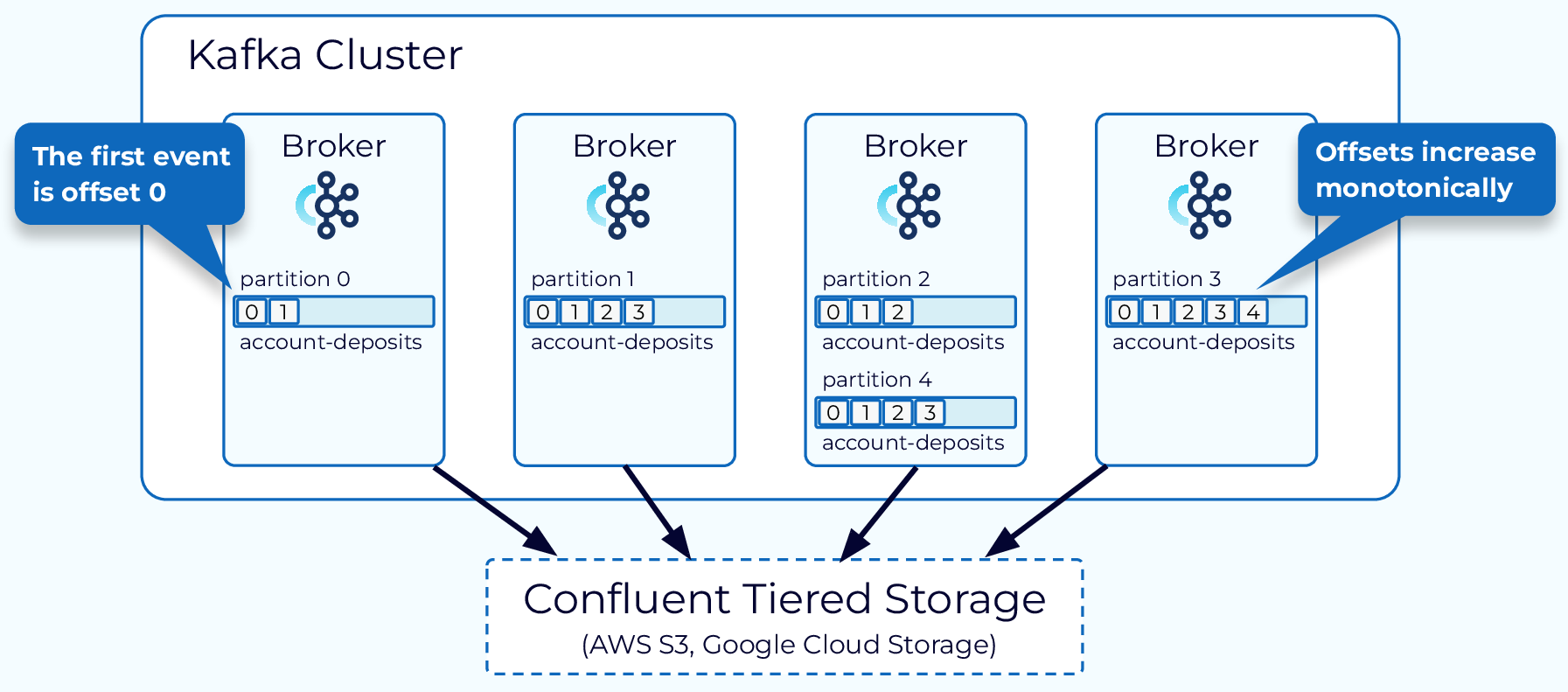
The partition is the main unit of storage for Kafka events, although with Tiered Storage, which we’ll talk about later, some event storage is moved off of partitions. The partition is also the main unit of parallelism. Events can be produced to a topic in parallel by writing to multiple partitions at the same time. Likewise, consumers can spread their workload by individual consumer instances reading from different partitions. If we only used one partition, we could only effectively use one consumer instance.
Within the partition, each event is given a unique identifier called an offset. The offset for a given partition will continue to grow as events are added, and offsets are never reused. The offset has many uses in Kafka, among them are consumers keeping track of which events have been processed.
Start Kafka in Minutes with Confluent Cloud
In this course we will have several hand-on exercises that you can follow along with. These exercises will help to cement what you are learning in the course. The easiest way to follow along with the exercises is with Confluent Cloud.
Get started by learning Kafka fundamentals by taking the Kafka 101 course. If you don’t yet have an account on Confluent Cloud, you can follow these steps to get started completely free!
- Browse to the sign-up page: https://www.confluent.io/confluent-cloud/tryfree/ and fill in your contact information and a password. Then click the Start Free button and wait for a verification email.
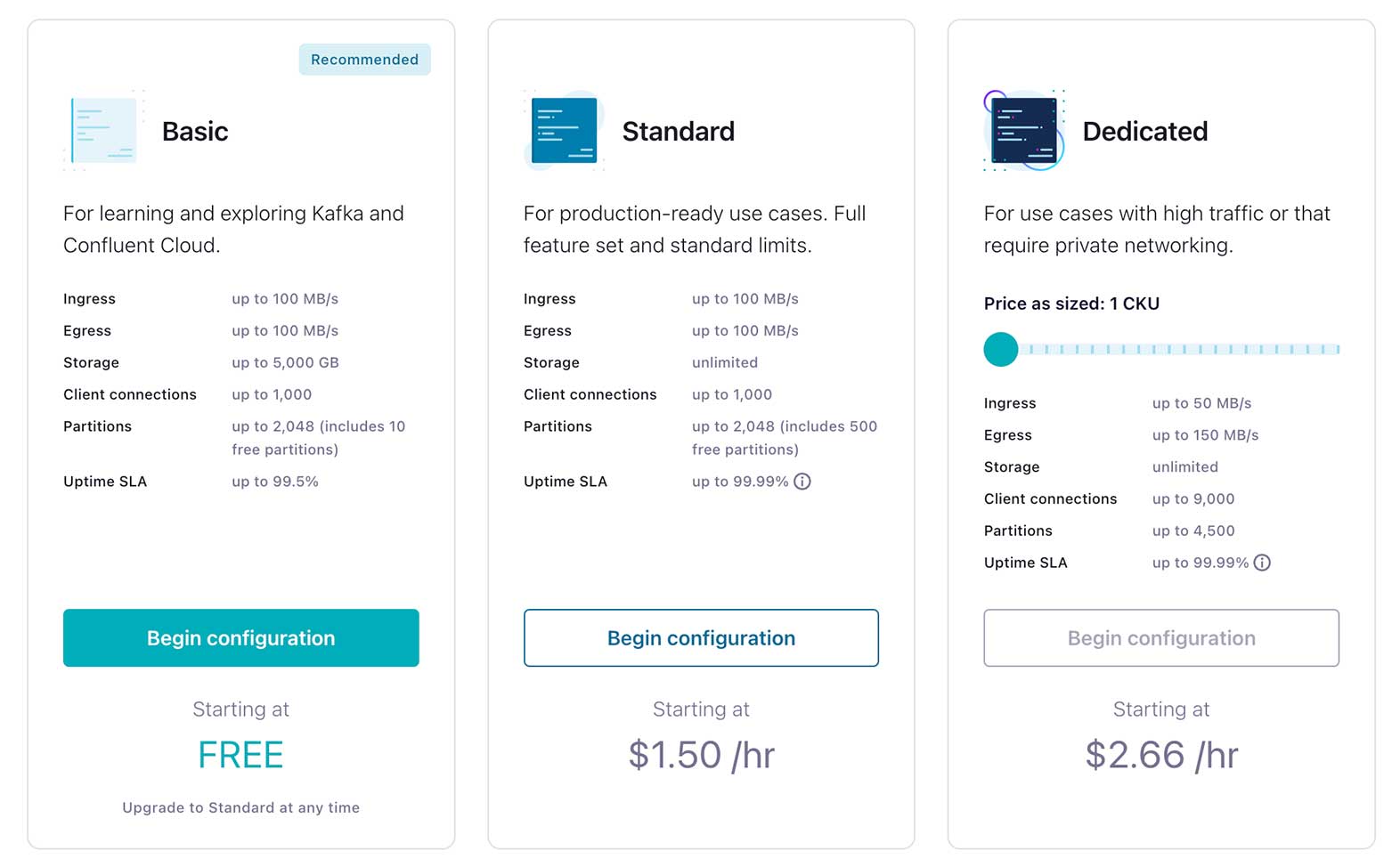
- Click the link in the confirmation email and then follow the prompts (or skip) until you get to the “Create Cluster” page. Here you can see the different types of clusters that are available, along with their costs. For this course, the Basic cluster will be sufficient and will maximize your free usage credits. After selecting Basic, click the Begin configuration button.
- Now you can choose your preferred cloud provider and region, and click Continue.

-
Now you can review your selections and give your cluster a name, then click Launch cluster. This might take a few minutes.
-
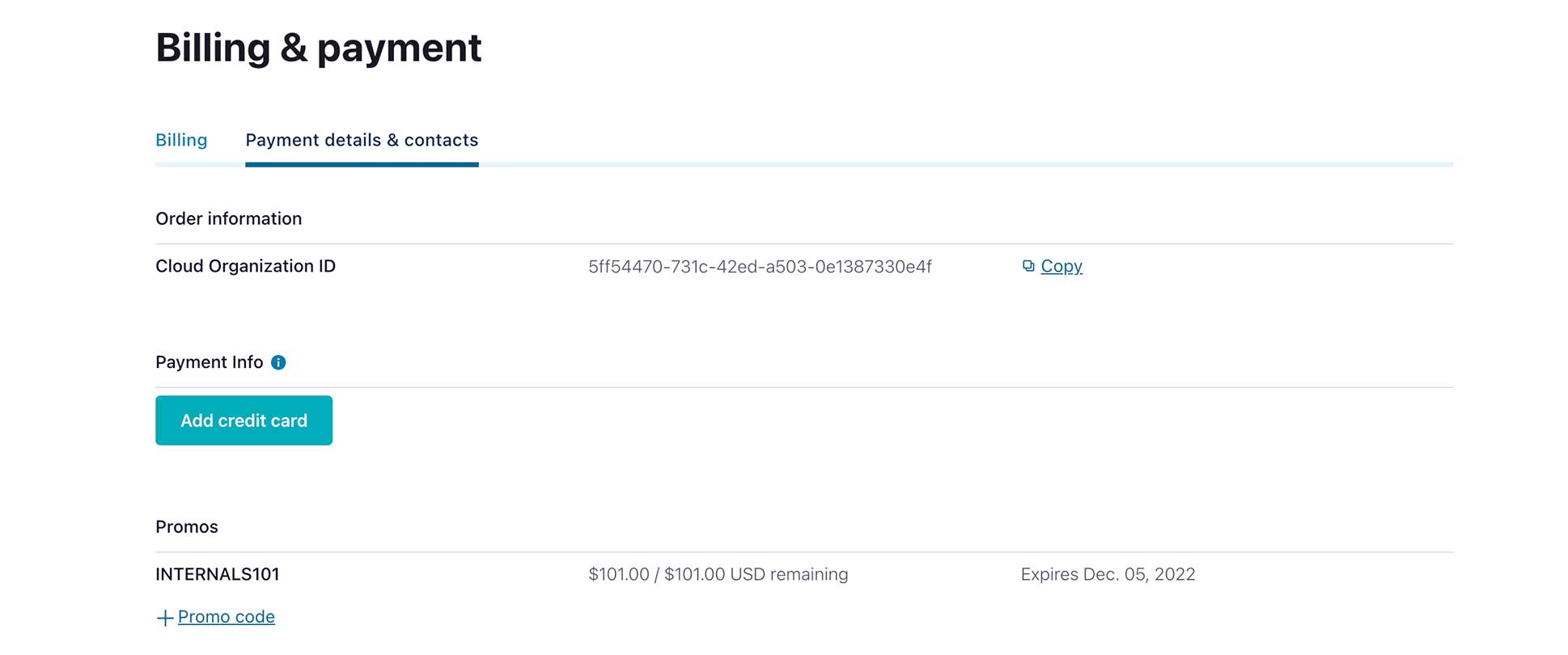
While you’re waiting for your cluster to be provisioned, be sure to add the promo code INTERNALS101 to get an additional $25 of free usage (details). You can also use the promo code CONFLUENTDEV1 to delay entering a credit card for 30 days. From the menu in the top right corner, choose Administration | Billing & Payments, then click on the Payment details tab. From there click on the +Promo code link, and enter the code.
Now you’re ready to take on the upcoming exercises as well as take advantage of all that Confluent Cloud has to offer!
- Previous
- Next
Use the promo code INTERNALS101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
The Fundamentals of Apache Kafka Architecture
Hi everyone. Jun Rao from Confluent, here. One of the original co-creators of Apache Kafka. Welcome to the Kafka Internals course. So here's what we're going to cover in this course. First, we're going to look into what's inside a broker. We're going to talk about how the data plane works, how the control plane works, and also how key-based topic retention works through compaction. We're also going to cover some of the guarantees, including durability guarantees, ordering guarantees, and then we're going to look into some of the more advanced capabilities such as group consumption, transactions, Tiered Storage, elasticity, geo-replication. But for this particular module, I'm just going to talk about fundamentals. If you are already familiar with Kafka, you may want to just skip this module and then continue with the next module. Kafka Architecture So this is a quick overview of the overall architecture of Kafka. As most people already know, Kafka is designed as an event streaming system. So it's designed so that applications can act on those new events immediately as they occur. The core of that is the storage system. This is depicted at the bottom. This is designed for storing those data efficiently as events and it's also designed as a distributed system such that if your needs grow over time, you can easily scale out the system to accommodate it for that growth. We have two primitive APIs for accessing the data stored in the storage layer. One is the Producer API that allows people to publish events into the storage layer and the other is the Consumer API that allows the application to read those events from the storage layer. On top of that, we built two higher-level APIs. One is called the Connect API. This is actually designed for integrating Kafka with the rest of ecosystems. For example, if you have some external data sources and you want to get those data into Kafka, you can use source connectors to get data into Kafka. If you have some data sinks for example, like a search engine or maybe a graph engine, you want Kafka's data flowing to those systems, you can also use those sink connectors to flow Kafka's data into those data sinks. Another high-level API we have designed is for processing. One of the APIs we have designed is for Java developers, it's called Kafka Streams and another is more declarative, it's called KSQL. Because it uses SQL-like syntax to allow the applications to build continuous processing of those events using SQL-like syntax. So the whole system is designed to have the processing layer separated from the storage layer. This way, the storage need and the processing need can be scaled out independently. Events The core concept in Kafka is called an "event." So what's an event? Well, an event is just something that happens in the world. This can be a purchase order, this can be a payment, can be a click of a link, can be like an impression you show for a web page. So each of these events is modeled in Kafka as a record. Each record has a timestamp, a key, a value, and optional headers. The payload is typically included in the value. The key is used typically for three purposes. It's used for enforcing ordering. It's used for colocating the data that have the same key property. It can also be used for key retention which we'll talk about later. Both the key and the value are typically just byte arrays. This gives people the flexibility to encode data in whatever way they want, using their favorite serializer. For example, you have integrated Kafka with Confluent Schema Registry, using Avro serializer then the value of the key and value may look something like this. For example, it will start with a magic byte followed by the Schema ID which is four bytes, followed by the rest of the serialized data using the Avro encoding. Topic Another key concept in Kafka is "topics." So think of a topic as like a database table. It's a concept for organizing events of the same type, together. So when you publish the events into Kafka, you need to specify which topic you want to publish this into and then similarly, when you read an event, typically you want to specify the set of topics you want to subscribe or read from. So all the events published to a topic are immutable so they are append-only. Since Kafka is designed as a distributed system, we need a way to distribute the data within that topic into the different computing nodes in the Kafka cluster. Partition So this is achieved through this concept called partitions. When you create a topic, you can specify one or more of those partitions. And a partition would be the unit of data distribution. And for a given partition, its data is typically stored within a single broker in the Kafka cluster, although with the Tiered Storage support from Confluent, we actually do allow the data for a partition to go beyond the capacity of a single broker. A partition is also the unit for parallelism. Each partition can be accessed independently and they can be accessed in parallel by writing from the producer and reading from the consumers. Offset Each of the events within the Kafka topic partition has a unique ID which we call an offset. This is a monotonically increasing number and once it's given out, it's never reused. So all the events are stored in the particular topic or partition in that offset order, and it will be given and delivered to the consumer in that event order. As we'll see later, this will make it easier for the consumer to keep track of where they are at. Demo Okay, that's pretty much the end of the first module. And if what we have talked about so far is still new to you, you may want to review some of the basic concepts by watching this Kafka 101 course from Confluent. Otherwise, see you in the next module. - Hi everyone. Danica Fine, here. You'll see me in the following exercises as we walk through some pretty cool Kafka Internals demos. In those, we'll be using Confluent Cloud, which is the easiest and fastest way to get started with Apache Kafka. If you don't already have an account, it's pretty important that you sign up. Just in case, and to get everyone on the same page, I'll walk you through the process. First off, you'll want to follow the URL on the screen. And keep note of that handy Internals 101 promo code. You'll need that later. On the signup page, enter your name, email, and password. Be sure to remember these sign in details as you'll need them to access your account later. Click the Start Free button and wait to receive a confirmation email in your inbox. The link in the confirmation email will lead you to the next step where you'll be prompted to set up your cluster. You can choose between a basic, standard, or dedicated cluster. Basic and standard clusters are serverless offerings where your free Confluent Cloud usage is only exhausted based on what you use, perfect for what we need today. For the exercises in this course, we'll choose the basic cluster. Usage costs will vary with any of these choices, but they are clearly shown at the bottom of the screen. That being said, once we wrap up these exercises, don't forget to stop and delete any resources that you created to avoid exhausting your free usage. Click Review to get one last look at the choices you've made and give your cluster a name, then launch. It may take a few minutes for your cluster to be provisioned. And that's it. You'll receive an email once your cluster is fully provisioned. But in the meantime, let's go ahead and leverage that promo code that we saw earlier. From Settings, choose Billing and Payment. You'll see here that you have $400 of free Confluent Cloud usage. But if you select the Payment Details and Contacts tab, you can either add a credit card or choose to enter a promo code. We'll enter INTERNALS101, [please refer to video description for details]. Which will be more then enough to get you through these course exercises. And with that done, you're ready to dive in. See ya there.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.