Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Configuring Durability, Availability, and Ordering Guarantees



Jun Rao
Co-Founder, Confluent (Presenter)
Data Durability and Availability Guarantees
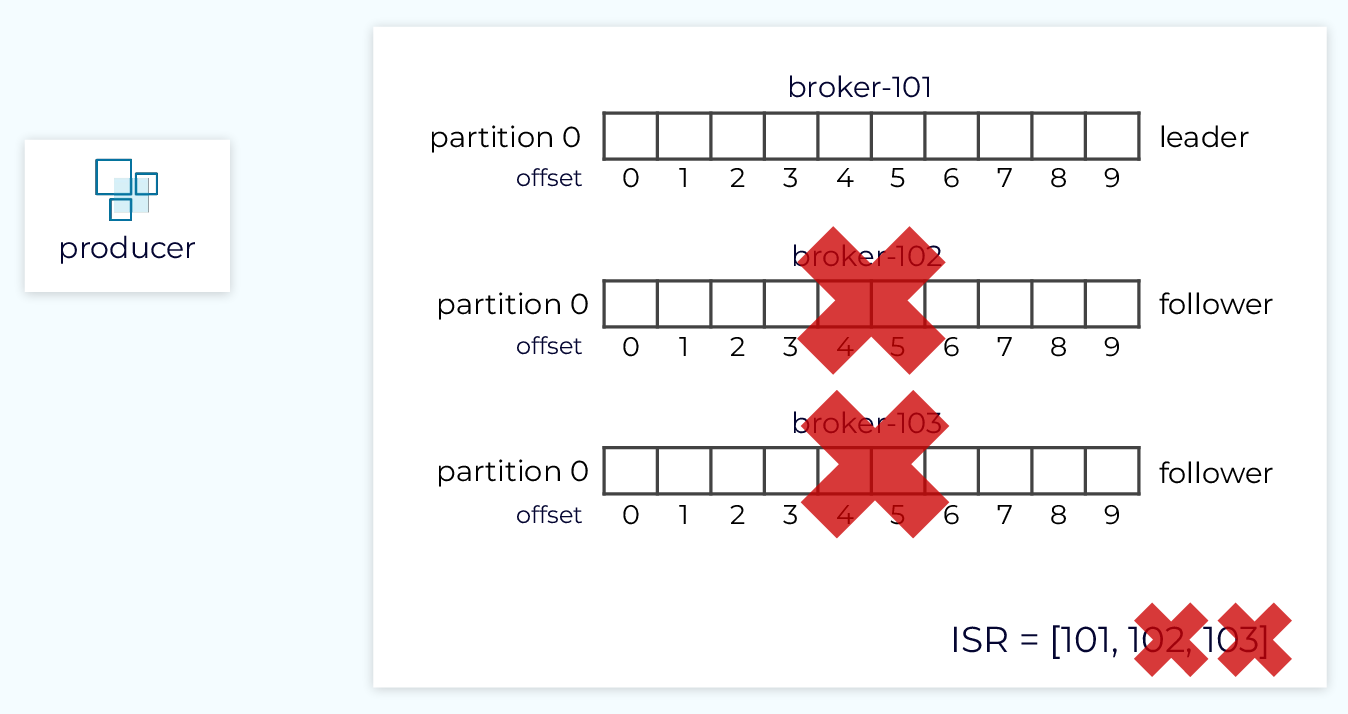
One of the key components of Kafka’s durability and availability guarantees is replication. All data written to a partition will be replicated to N other replicas. A common value for N is 3, but it can be set to a higher value if needed. With N replicas, we can tolerate N-1 failures while maintaining durability and availability.
As mentioned in earlier modules, consumers only see committed records. Producers on the other hand have some choices as to when they receive acknowledgment for the success or failure of a produce request from the broker.
Producer acks = 0
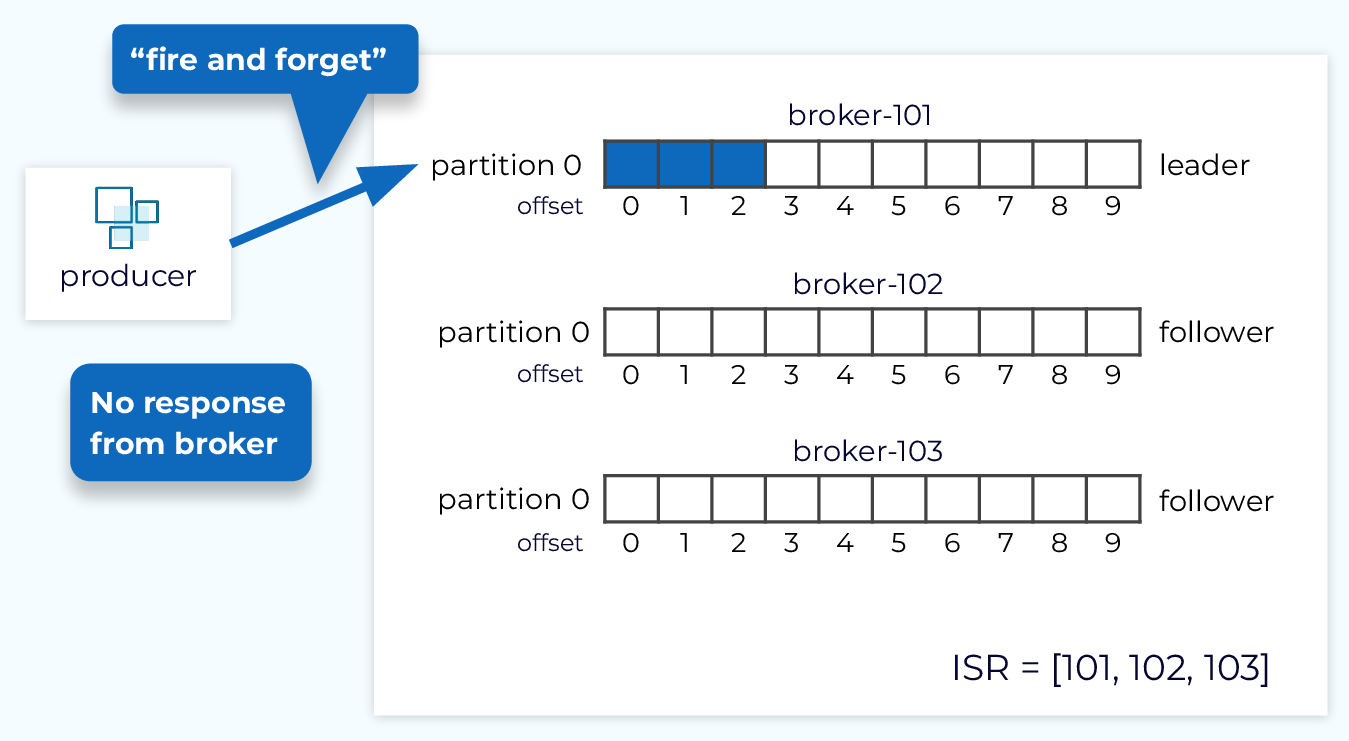
The producer configuration, acks, directly affects the durability guarantees. And it also provides one of several points of trade-off between durability and latency. Setting acks=0, also known as the “fire and forget” mode, provides lower latency since the producer doesn’t wait for a response from the broker. But this setting provides no strong durability guarantee since the partition leader might never receive the data due to a transient connectivity issue or we could be going through a leader election.
Producer acks = 1
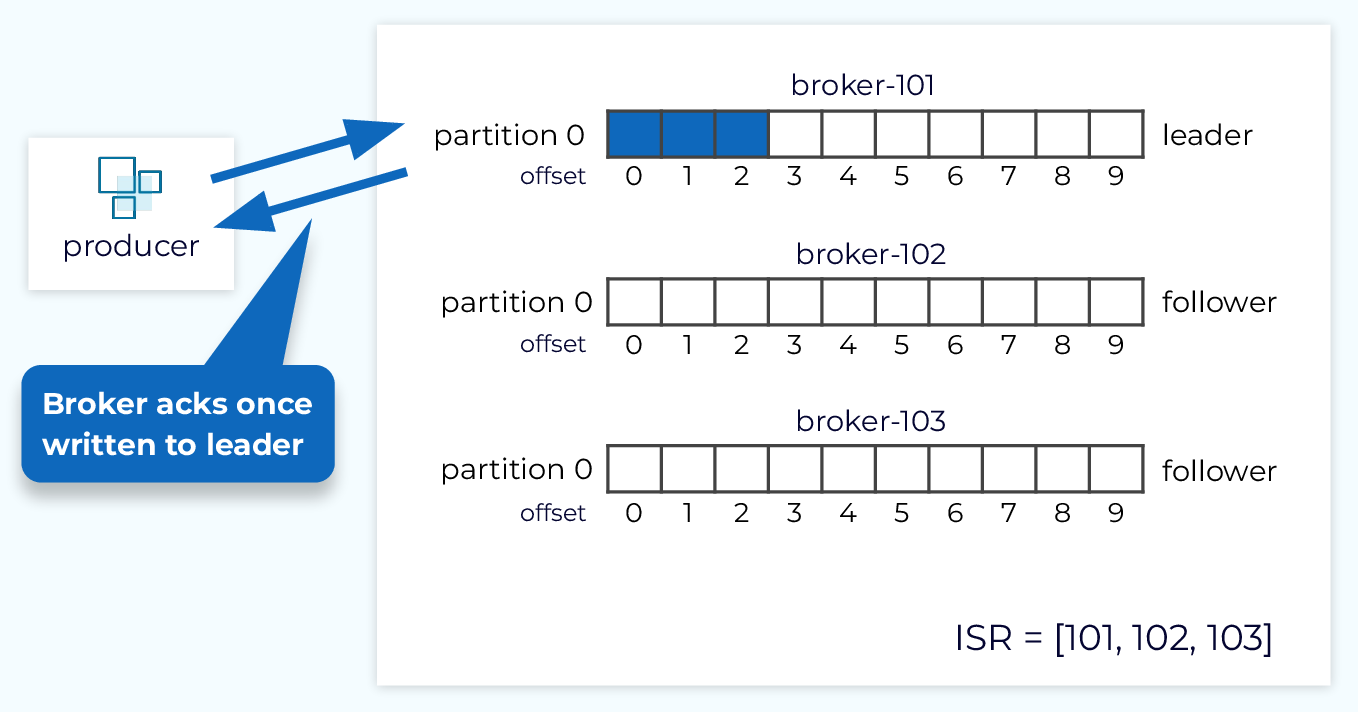
With acks=1, we have a little bit better durability, since we know the data was written to the leader replica, but we have a little higher latency since we are waiting for all the steps in the send request process which we saw in the Inside the Apache Kafka Broker module. We are also not taking full advantage of replication because we’re not waiting for the data to land in the follower replicas.
Producer acks = all
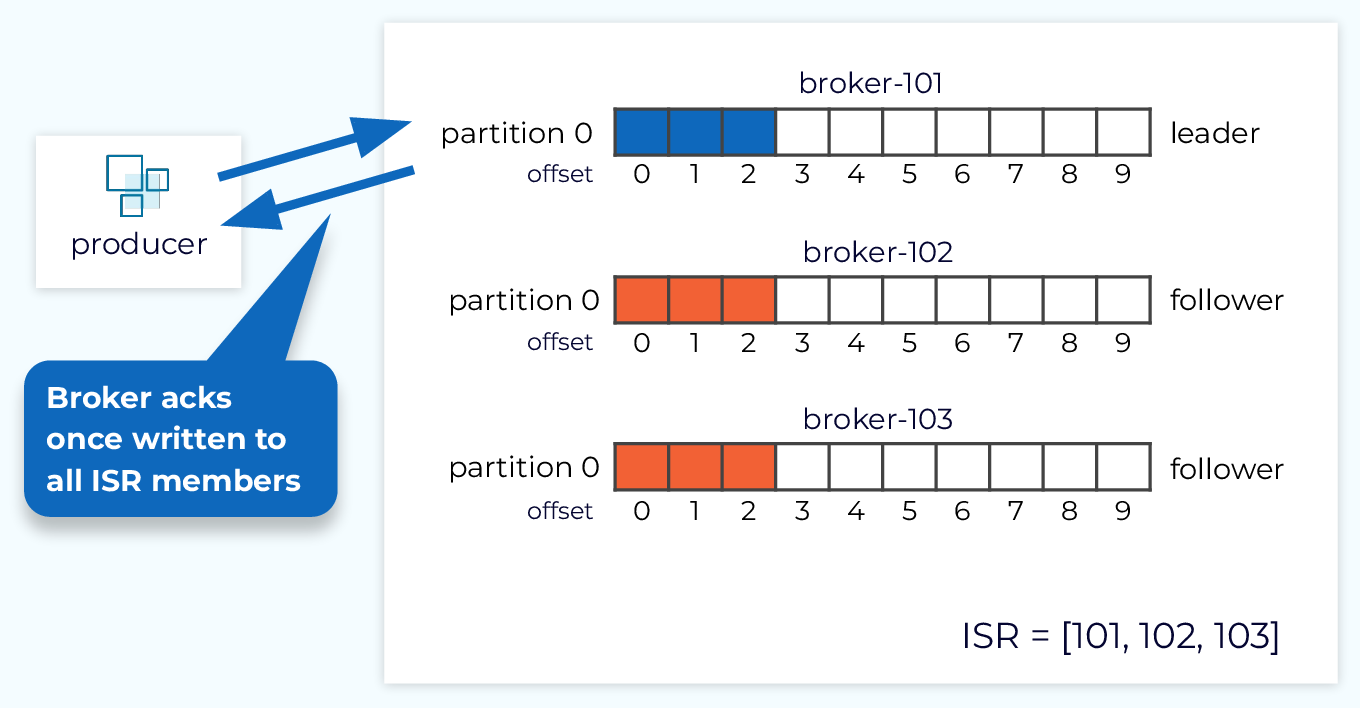
The highest level of durability comes with acks=all (or acks=-1), which is also the default. With this setting, the send request is not acknowledged until the data has been written to the leader replica and all of the follower replicas in the ISR (in-sync replica) list. Now we’re back in the situation where we could lose N-1 nodes and not lose any data. However, this will have higher latency as we are waiting for the replication process to complete.
Topic min.insync.replicas
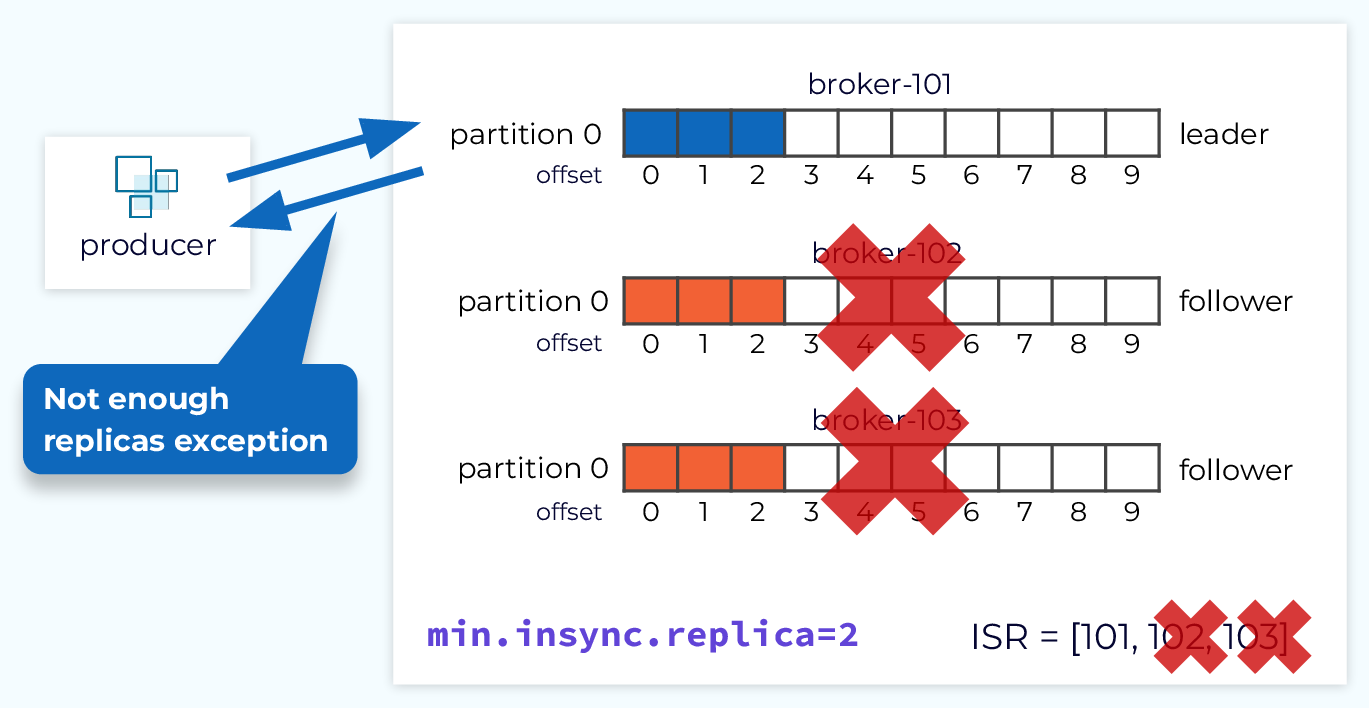
The topic level configuration, min.insync.replicas, works along with the acks configuration to more effectively enforce durability guarantees. This setting tells the broker to not allow an event to be written to a topic unless there are N replicas in the ISR. Combined with acks=all, this ensures that any events that are received onto the topic will be stored in N replicas before the event send is acknowledged.
As an example, if we have a replication factor of 3 and min.insync.replicas set to 2 then we can tolerate one failure and still receive new events. If we lose two nodes, then the producer send requests would receive an exception informing the producer that there were not enough replicas. The producer could retry until there are enough replicas, or bubble the exception up. In either case, no data is lost.
Producer Idempotence
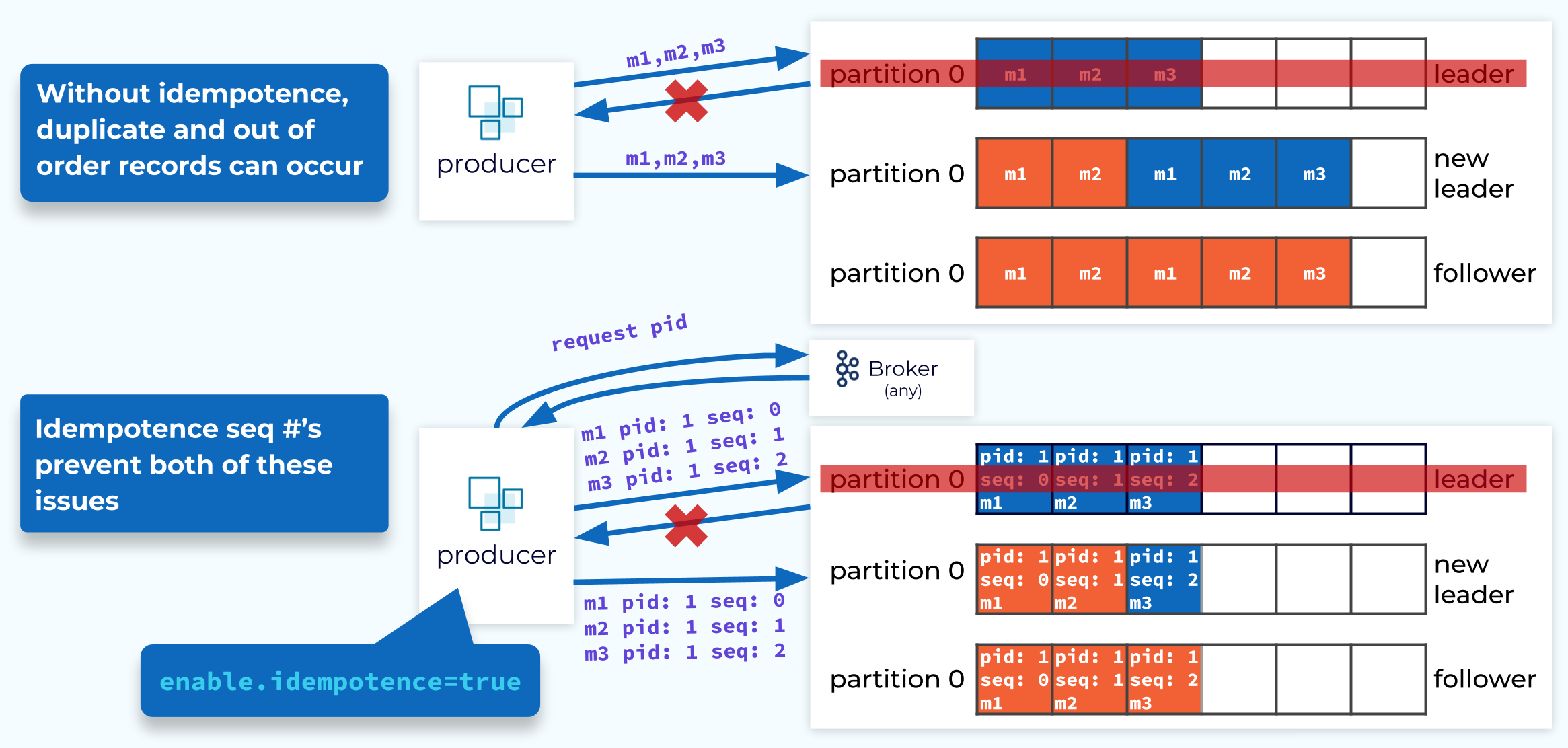
Kafka also has ordering guarantees which are handled mainly by Kafka’s partitioning and the fact that partitions are append-only immutable logs. Events are written to a particular partition in the order they were sent, and consumers read those events in the same order. However, failures can cause duplicate events to be written to the partition which will throw off the ordering.
To prevent this, we can use the Idempotent Producer, which guarantees that duplicate events will not be sent in the case of a failure. To enable idempotence, we set enable.idempotence = true on the producer which is the default value as of Kafka 3.0. With this set, the producer tags each event with a producer ID and a sequence number. These values will be sent with the events and stored in the log. If the events are sent again because of a failure, those same identifiers will be included. If duplicate events are sent, the broker will see that the producer ID and sequence number already exist and will reject those events and return a DUP response to the client.
End-to-End Ordering Guarantee
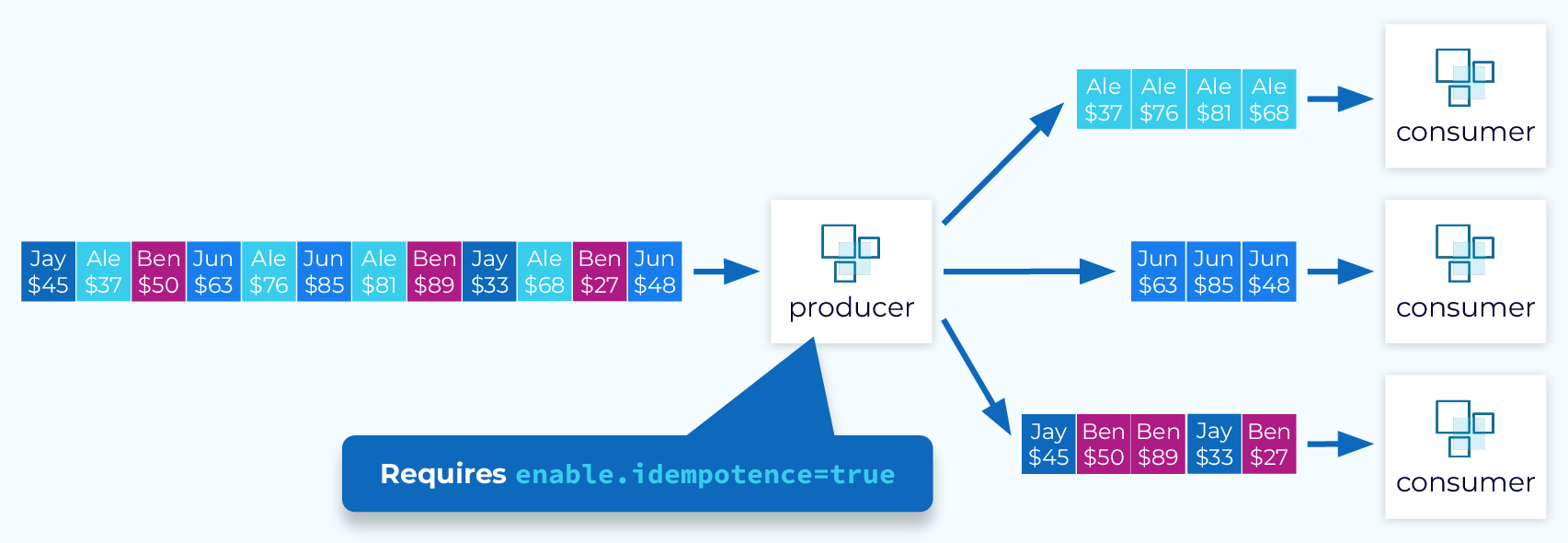
Combining acks=all, producer idempotence, and keyed events results in a powerful end-to-end ordering guarantee. Events with a specific key will always land in a specific partition in the order they are sent, and consumers will always read them from that specific partition in that exact order.
In the next module we will look at transactions which take this to the next level.
Use the promo code INTERNALS101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Configuring Durability, Availability, and Ordering Guarantees
Hey, everyone. Welcome back. This is Jun Rao from Confluent. In this module, we're going to talk about how to configure some of the durability, availability and ordering guarantees within Kafka. (playful music) In some of the previous modules, we talked about how the control plane and the data plane work within a Kafka cluster. In this module, we're going to switch gears a little bit and talk about some of the guarantees. Kafka Replication Let's first talk about some of the durability and availability guarantees. Earlier, we talked about Kafka replication being a great way of providing durability and availability. So when you create a topic, you can specify the number of replicas you want to have. If you specify N number of replicas, then we can tolerate N - 1 failures. For mission critical applications, you can potentially configure even more replicas to tolerate a greater number of failures. Only the committed data will be exposed to the consumers. Now what about the producers? The producers actually have some choice as to when to receive the acknowledgement. Producer Modes The simplest form for a producer is to have this acks equals zero mode. This is a little bit like a fire-and-forget mode. So it's pretty good for latency because you don't need to wait for the response to be sent, but there's no strong guarantee of durability because the data can be lost before it even reaches the broker. The second mode the producer can have is acks equals one. In this mode, the producer will wait for the data to be received and added into the log of the leader replica before the response is sent to the producer. In this case, the latency will be longer because you have to wait for this round trip between the producer client and the leader broker. The durability story is much improved but there's still a little bit of chance when there's something like a leader election while a message is being produced, some of the records or events could be lost. The strongest mode we have is called acks equals all Axis Mode If you configure this, then the producer will only be acknowledged once the data is fully replicated to all the in-sync replicas. This is actually the strongest mode for durability guarantees. And it's important for mission-critical applications. In terms of latency, it's a little longer than the acks that are smaller. It's roughly two point times longer than the acks equals one mode. Because in addition to the round trip between the producer and the leader, you have to wait for another round trip for the data to be replicated from a leader to the follower potentially in parallel, if you have multiple followers. But you have to wait another round, a half round trip, for the follower to acknowledge the receipt of those events. So it's roughly 2.5 times then, the latency of the leader. Minimum insync replicas Now let's talk about some of the other guarantees. For some of the mission critical applications, they might may want to say, if I produce some records I only want to have the records acknowledged successfully if it's guaranteed that records will be inserted into at least a certain number of replicas. Otherwise, I'd rather choose that they not be taken. So this can be supported with a top-level configuration called minimum in-sync replicas. If you configure this, then when you append the data to this log, it will only successfully replicate the data and acknowledge it if at that point, there are enough replicas, more than this minimum insync replicas in the insync replica set. If there are fewer replicas, then this configuration in ISR will send a "not enough replicas" error back to the producer indicating that your data is rejected. So this is another way for mission critical applications to strengthen some of their durability guarantees. Ordering guarantees Now let's switch gears a little bit to talk about some of the ordering guarantees. In the earlier modules, we have talked about how in general, we are already enforcing strong ordering from the producer all the way to the consumers. For the producers, for all the messages sent from a single producer to a given partition, they will be stored in the commit log for that partition in the order they are sent and they will be delivered in the same order to the consumer in normal mode. But sometimes, the ordering guarantee can be a little tricky if there are failures. Let's consider this example. For example, in this case, the producer is trying to send three records m1, m2, m3 into the leader. Let's say halfway through, maybe only two of the records have been fully replicated and considered committed. But at that point, the leader is dead. Or the producer didn't get any acknowledgement for all those three messages. Then in order not to lose those events, what a producer needs to do is to retry sending those three messages to the new leader. So it will send m1, m2, and m3 again. In this case, since the new leader doesn't know this is actually a duplicate of the previous send, it will just forcefully take those records in this log. Now you can see, we have introduced some duplicates because m1 and m2 have been received twice. And we are also introducing some of the violation of the ordering guarantees because now, m1 appears to happen after m2 even though technically, it's sent before m2. So to solve this problem, we have introduced another feature called idempotent producer. This is actually pretty easy to enable. You just need to set this configuration in the producer. Set or enable idempotency to true. Once you have set this mode, the producer will try to avoid those duplicates and reordering even when there are failures. So let's see how it works. The way this works is when the producer is first started in this mode, the first thing it will do is to ask the broker for a producer ID. This is a unique ID intended for the lifetime of this producer. Then each time the producer tries to send some of the events to the leader, it will tag all those events with the producer ID as well as the corresponding sequence number associated with each record. The sequence number is uniquely used to identify each of the messages the producer will be sending. Once the leader receives those records, it'll append those records with the pid and the corresponding sequence number in this commit log. And this will be replicated to other replicas as well. Now, let's say the same thing happens. About halfway, you only have two messages, m1 and m2 that have been fully replicated. And then the old leader dies. In this case, a new leader will be elected. And when the producer is trying to resend the same three events to the new leader, it'll be sending those three events with the same pid and sequence numbers. And once the new leader receives them, it can compare those sequence numbers with the last sequence number it has seen with this producer ID. In this case, it will notice that message one and message two, based on sequence number, are duplicates because it has seen them before in its own log. So it will only take the last message, which is m3, in its log. As you can see, with idempotency introduced, now we can truly avoid the duplication as well as avoiding changing the ordering of those events. So this leads us to ordering guarantees. End to end ordering guarantee If you have idempotency enabled in the producer and you also have acks equals all set in the producer, in general, you are guaranteed this end-to-end ordering guarantee. In particular, if you have a single producer sending keyed messages, we guarantee all the events sent with the same key they will be landing in the same partition in exactly the same order they are sent and they will be delivered to the same consumer in the exact order they are sent. So this is actually an end-to-end key-ordering guarantee that we support. That's it for this module. Thanks for listening.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.