Enhance your career, get Certified as a Data Streaming Engineer | Get Certified
Topic Compaction



Jun Rao
Co-Founder, Confluent (Presenter)
Topic Compaction
Topic compaction is a data retention mechanism that opens up a plethora of possibilities within Kafka. Let’s dig deeper into what compaction is and how it works.
Time-Based Retention
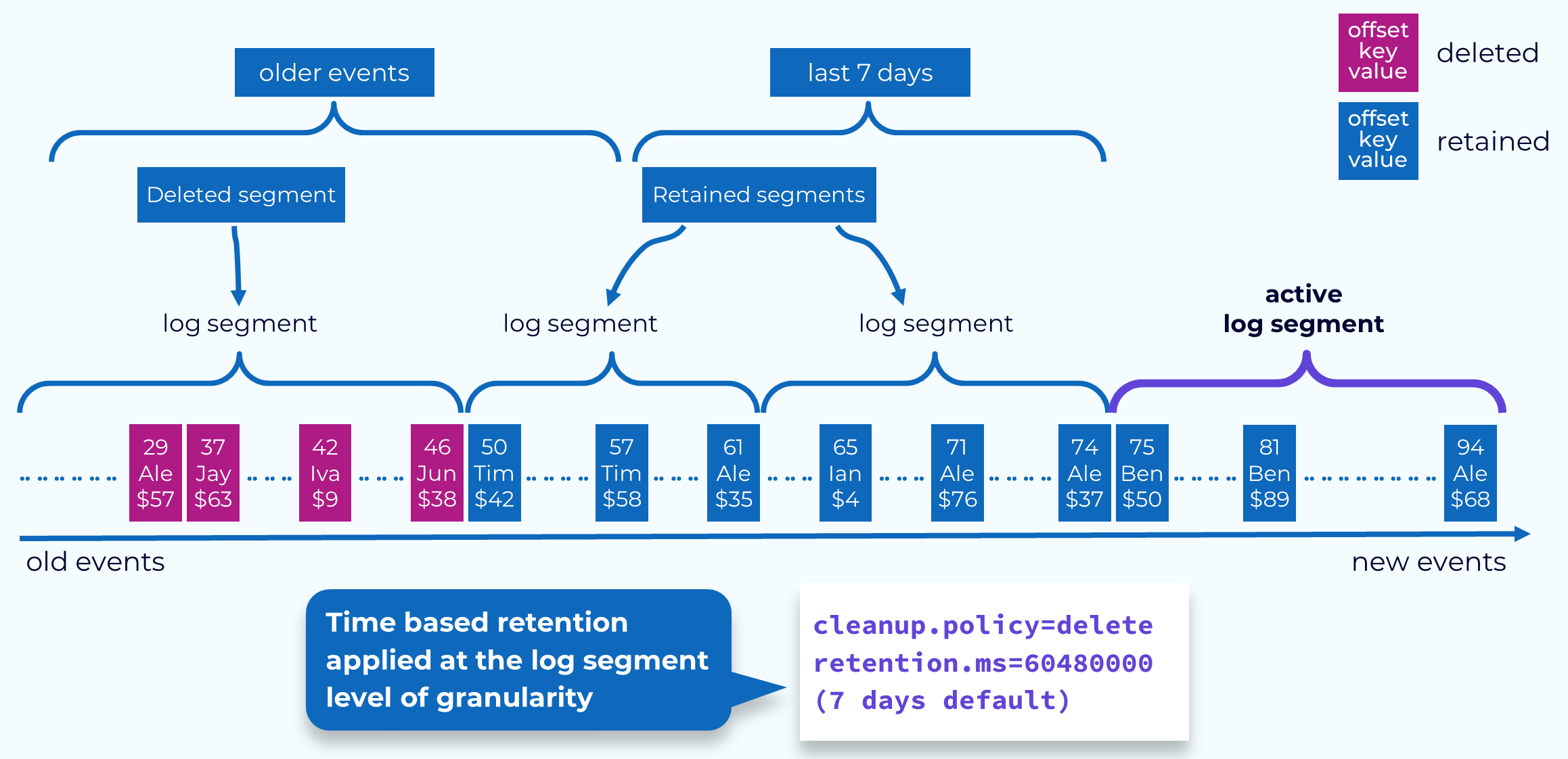
Before we talk more about compaction, let’s discuss its counterpart, time-based retention. Time-based retention is specified by setting the cleanup.policy to delete and setting the retention.ms to some number of milliseconds. With this set, events will be kept in the topics at least until they have reached that time limit. Once they have hit that limit, they may not be deleted right away. This is because event deletion happens at the segment level. A segment will be marked for deletion once its youngest event has passed the time threshold.
Topic Compaction: Key-Based Retention
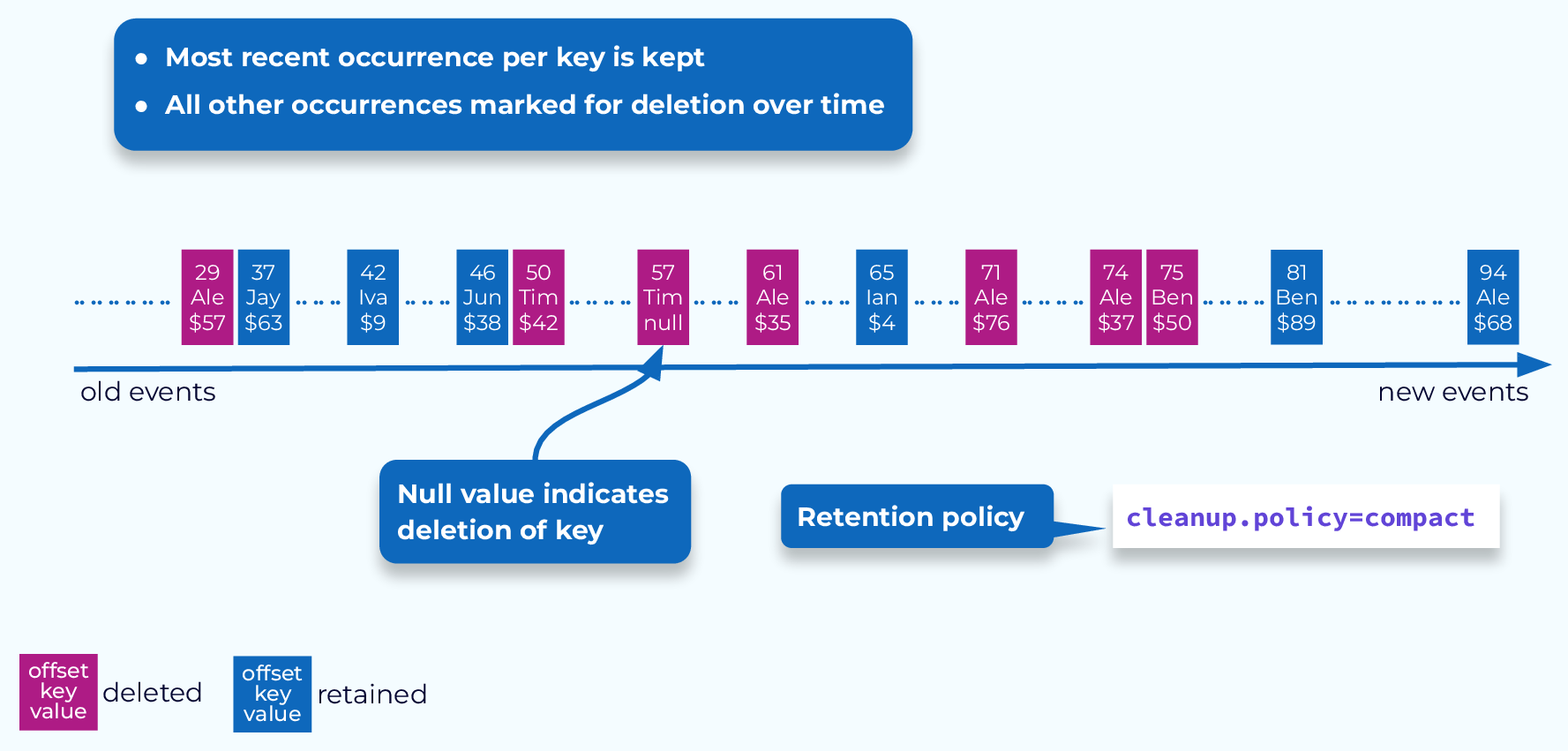
Compaction is a key-based retention mechanism. To set a topic to use compaction, set its cleanup.policy to compact. The goal of compaction is to keep the most recent value for a given key. This might work well for maintaining the current location of a vehicle in your fleet, or the current balance of an account. However, historical data will be lost, so it may not always be the best choice.
Compaction also provides a way to completely remove a key, by appending an event with that key and a null value. If this null value, also known as a tombstone, is the most recent value for that key, then it will be marked for deletion along with any older occurrences of that key. This could be necessary for things like GDPR compliance.
Usage and Benefits of Topic Compaction
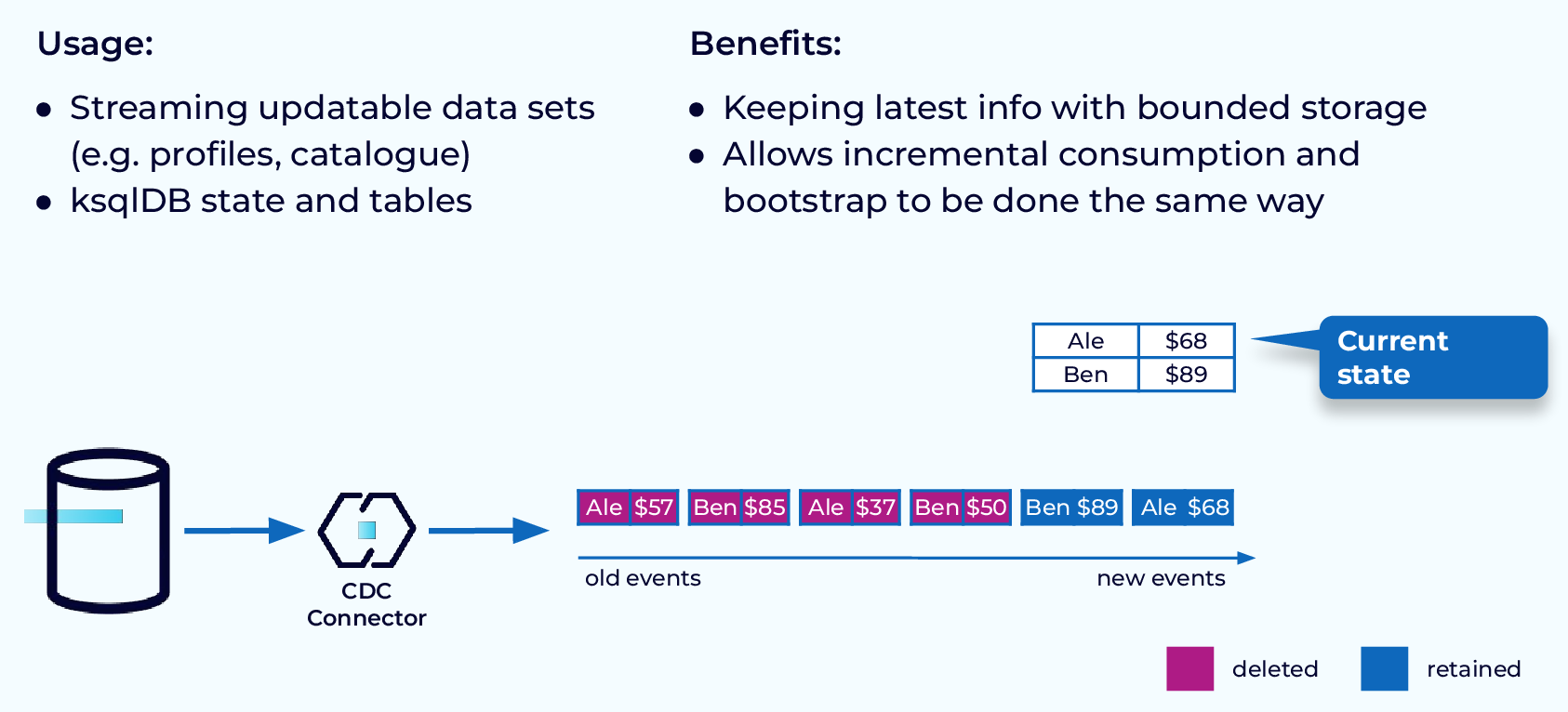
Because compaction always keeps the most recent value for each key, it is perfect for providing backing to ksqlDB tables, or Kafka Streams KTables. For updatable datasets, for example, database table data coming into Kafka via CDC, where the current value is all that matters, compacted topics allow you to continue receiving updates without topic storage growing out of hand.
Compaction Process
The process of compacting a topic can be broken down into several distinct steps. Let’s take a look at each of these steps.
Segments to Clean
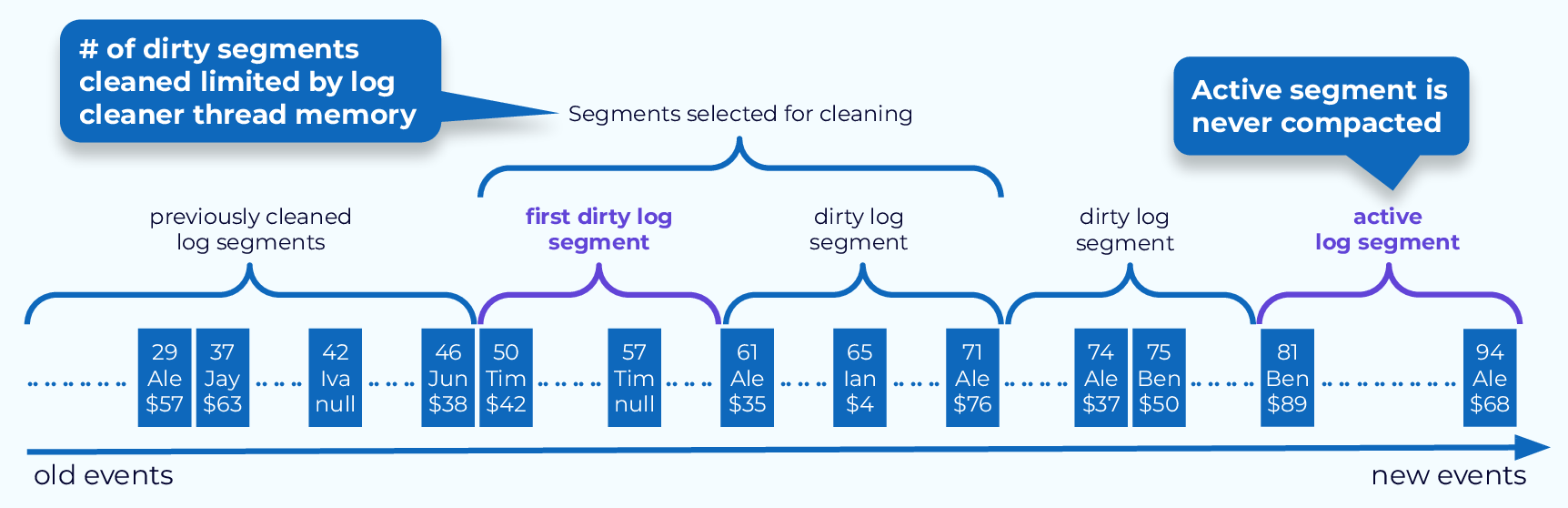
Compaction is done by deleting old events from existing segments and, sometimes, copying retained events into new segments. The first step in all of this is to determine which segments to clean. At the beginning of a compacted topic partition, there will be previously cleaned segments. These are segments that have no duplicate keys in them, though there may be duplicates in newer segments. The segments that are newer than this are considered dirty segments. Starting at the first dirty segment, we will grab some number of segments to clean. The precise number depends on the amount of memory available to the cleaner thread.
Also, note that the active segment is never cleaned by this process.
Build Dirty Segment Map
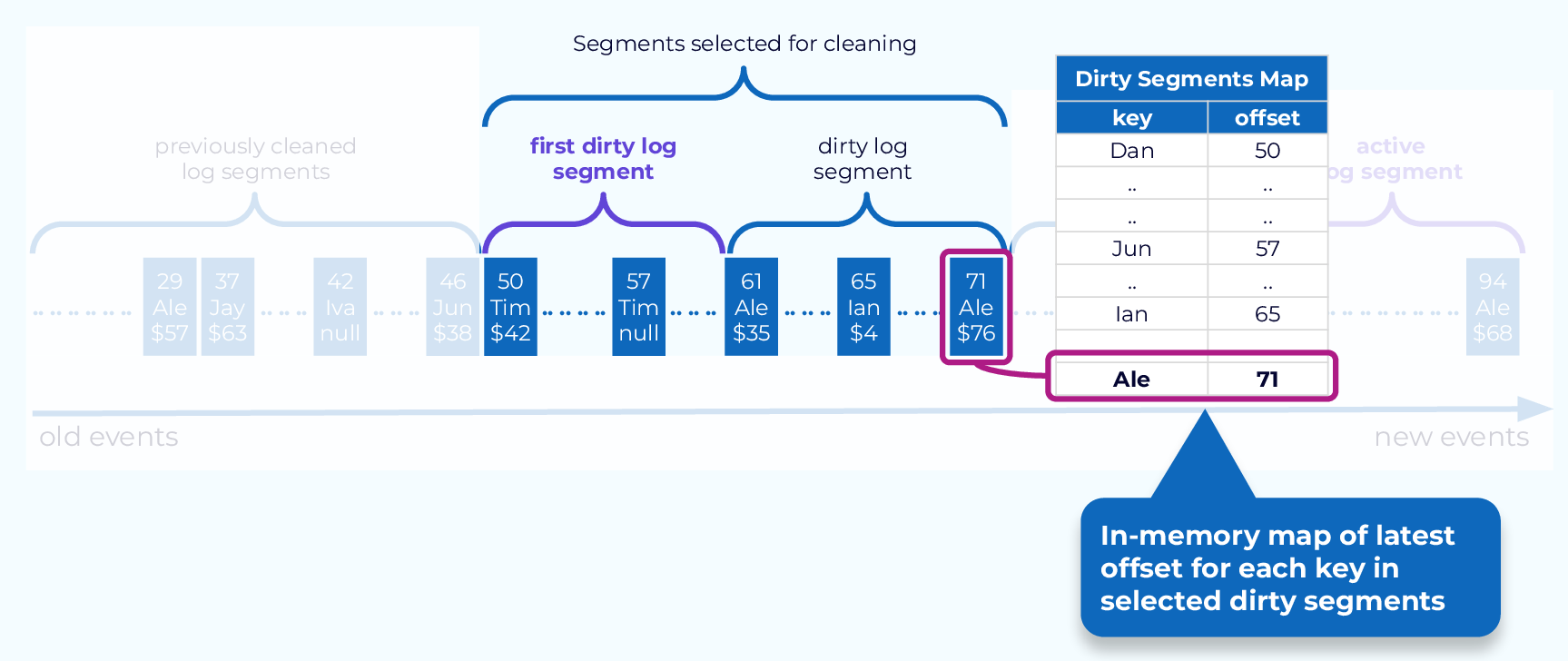
Next we will scan through the selected dirty segments, starting at the earliest offset and build an offset map, keyed on the event keys. As newer offsets are found for a given key, the value is updated. The end result is a map of the most recent offset for each key.
Deleting Events
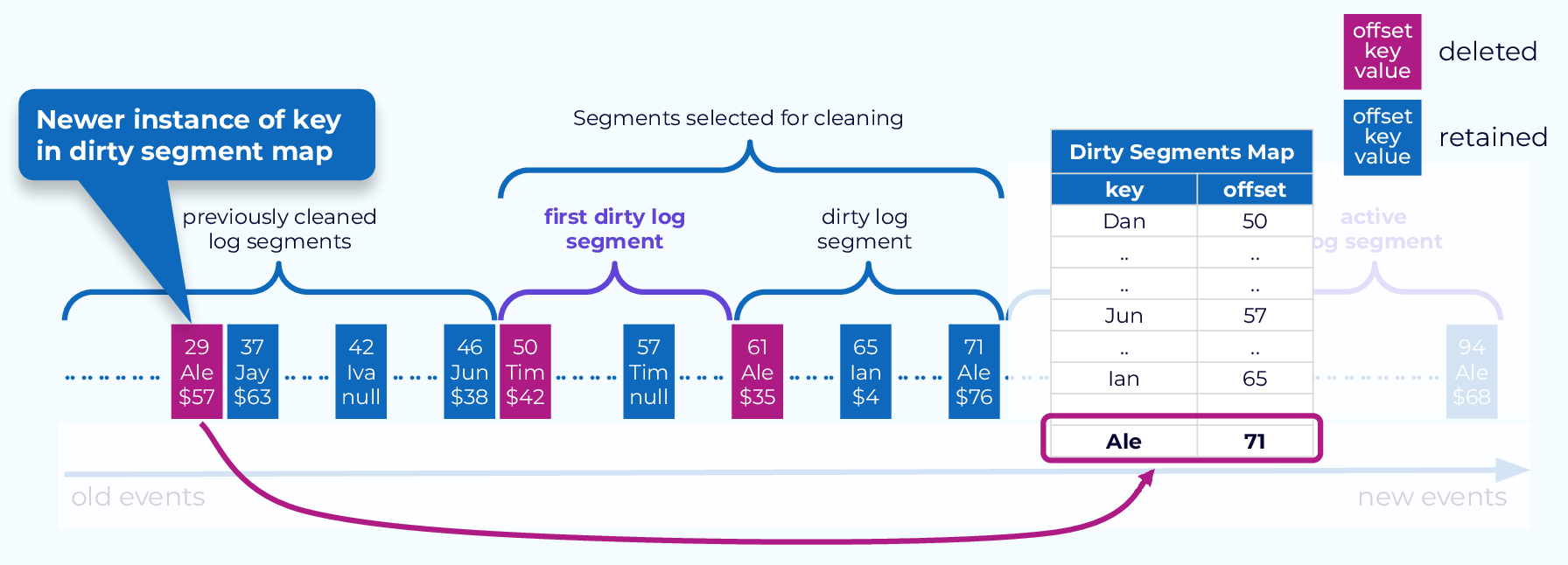
Now we make another pass through the partition, this time from the beginning, including the previously cleaned segments. For each event, we will check in the dirty segment map looking for its key. If the key is found, and the offset value is higher than that of the event, the event will be deleted.
Retaining Events
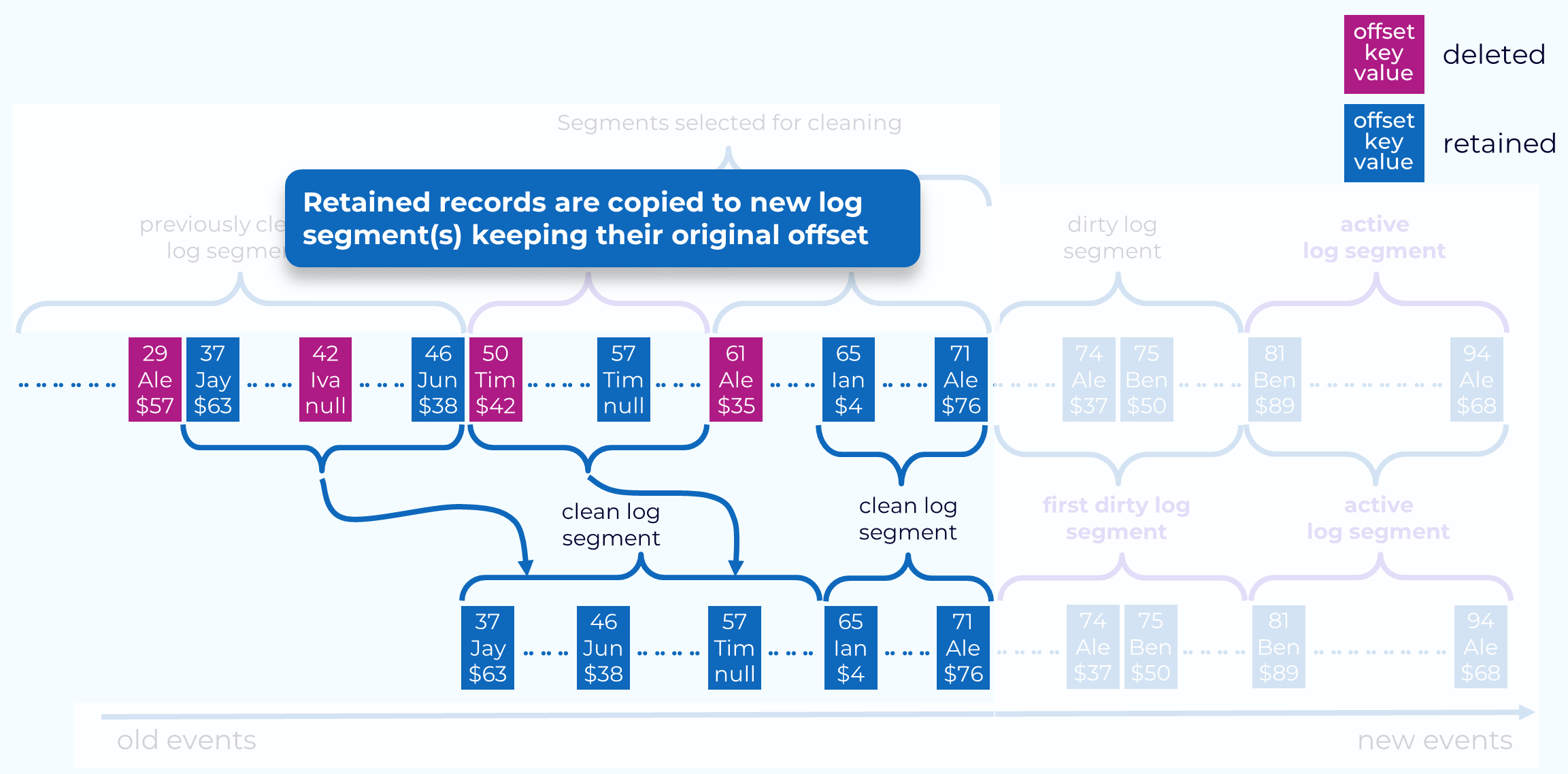
The retained events, in both the dirty and cleaned segments, are copied to new log segments. If the total size of retained events from two log segments is less than the topic segment.bytes value, they will be combined into a single new segment as illustrated in the diagram. It’s important to note here that each event’s original offset is maintained, even though that may leave gaps in the offsets.
Replace Old Segments
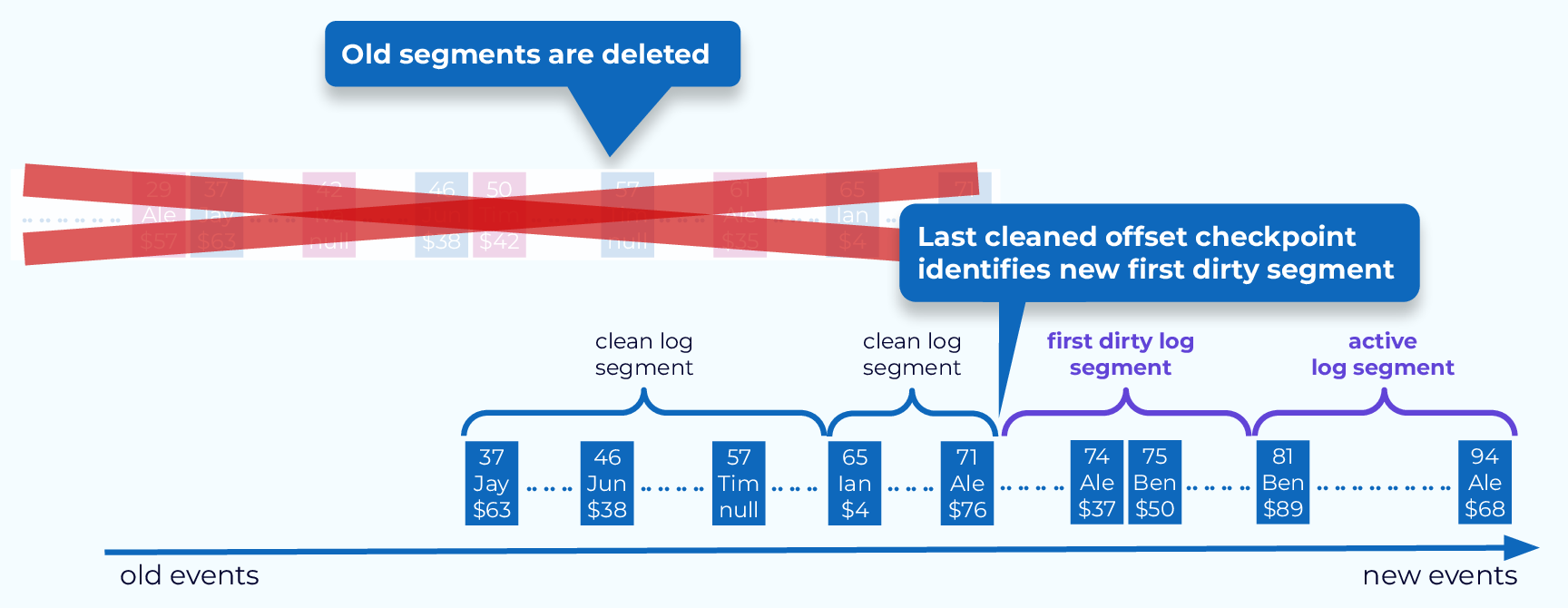
The final step in the compaction process is to remove the old segments and checkpoint the last cleaned offset, which will mark the beginning of the first dirty segment. The next round of log compaction for the partition will begin with this log segment.
Cleaning Tombstone and Transaction Markers
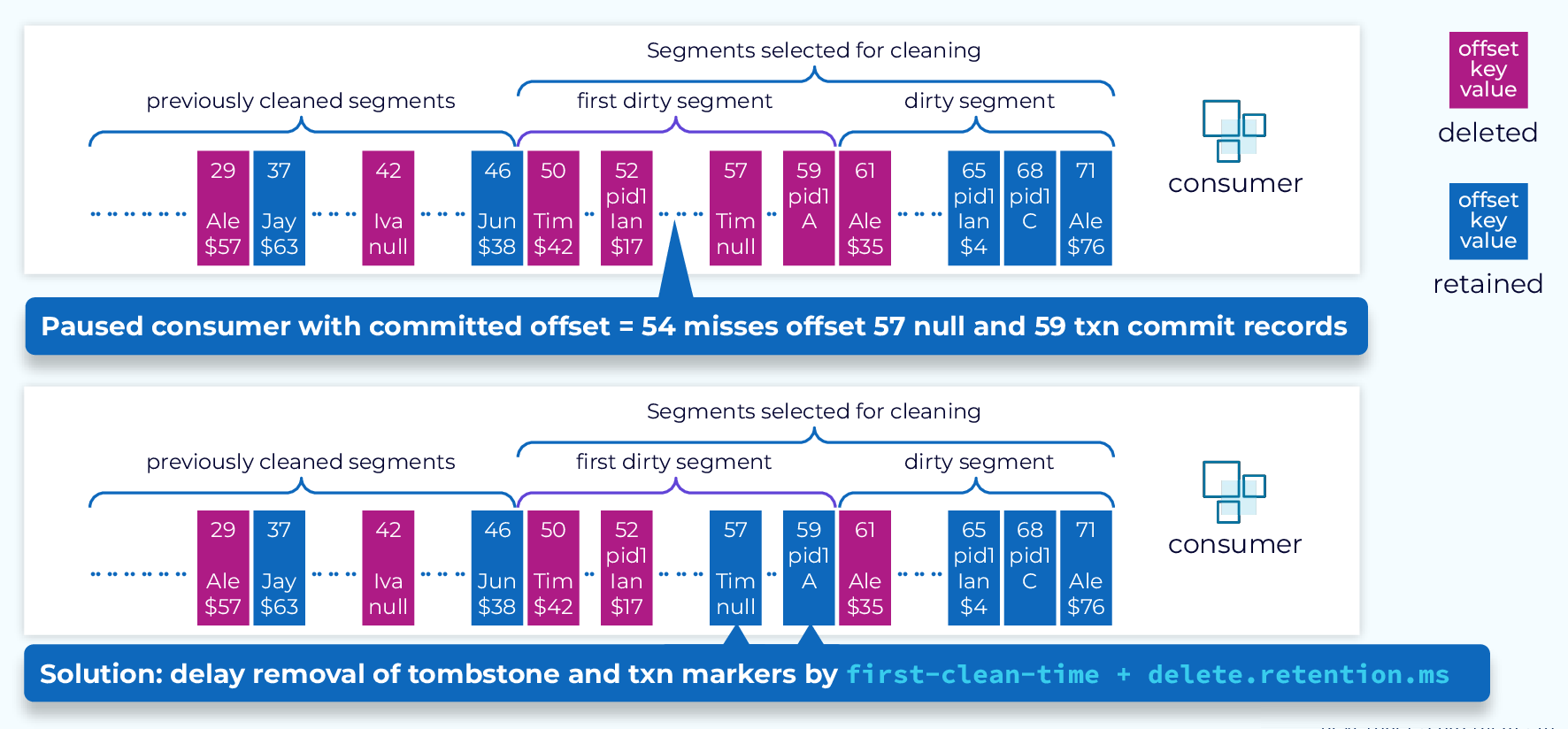
Tombstone and transaction markers have special significance to client applications so we need to take some extra precautions so that client applications don’t miss them.
The way this is handled is with a two-stage process. When tombstones or transaction markers are first encountered during cleanup, they are marked with a to-delete-timestamp which is the time of this cleaning plus delete.retention.ms. They will then remain in the partition and be available for clients.
Then, on subsequent cleanings any events whose time-to-delete timestamp has been reached will be removed.
The delay imposed by this two-stage process ensures downstream consumer applications are able to process tombstone and transaction marker events prior to their deletion.
When Compaction Is Triggered
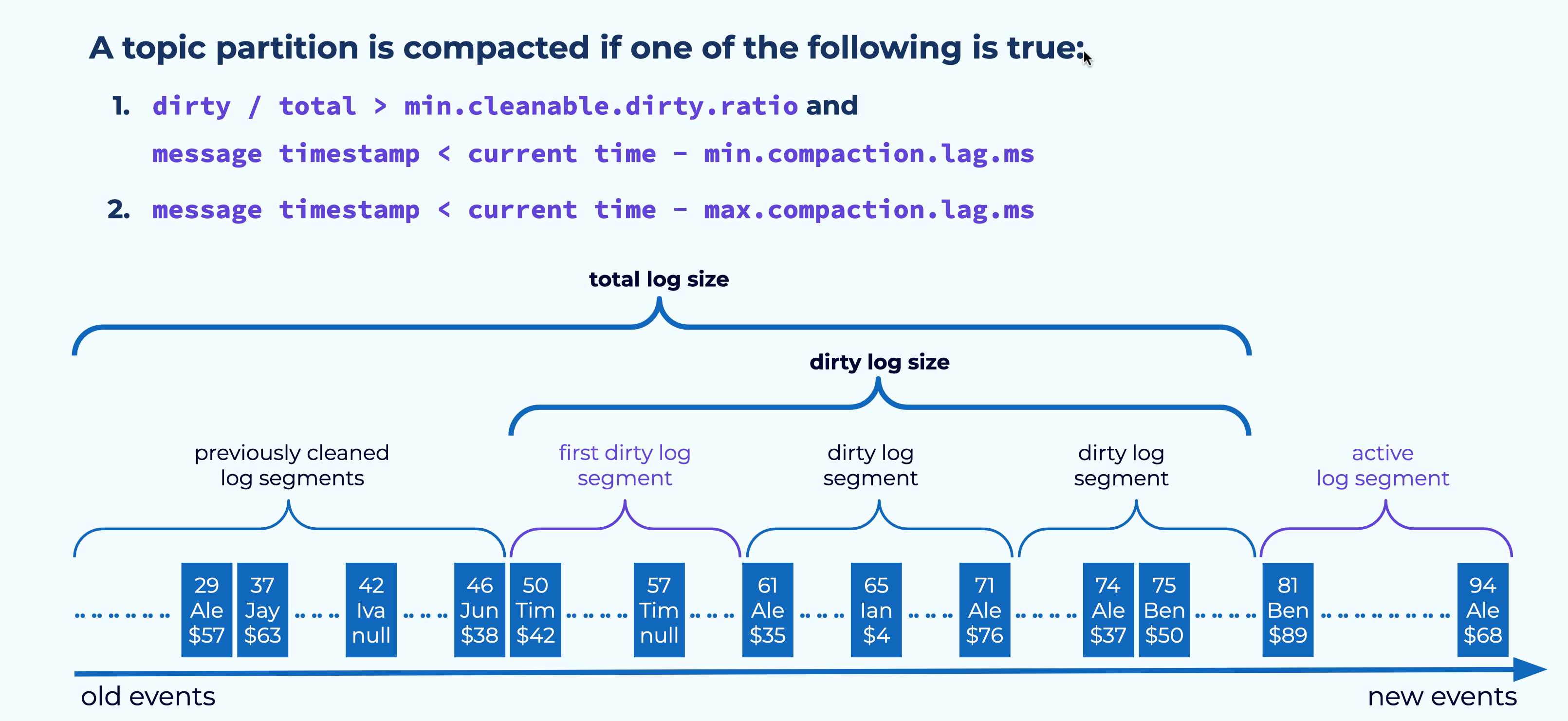
Errata
- Errata: there's a small mistake in the video above at 8:56 in the topic compaction section. The first condition should read: “message timestamp < current time - min.compaction.lag.ms” just like on the diagram above.
Normally, compaction will be triggered when the ratio of dirty data to total data reaches the threshold set by the min.cleanable.dirty.ratio configuration, which defaults to 50 percent. However, there are a couple of other configurations that can affect this decision.
To prevent overly aggressive cleaning, we can set the value of min.compaction.lag.ms. With this set, compaction won’t start more frequently than its value even if the dirty/total ratio has been exceeded. This provides a minimum period of time for applications to see an event prior to its deletion.
On the other end of the spectrum, we can set max.compaction.lag.ms, which will trigger a compaction once the time limit has been reached, regardless of the amount of dirty data.
Topic Compaction Guarantees
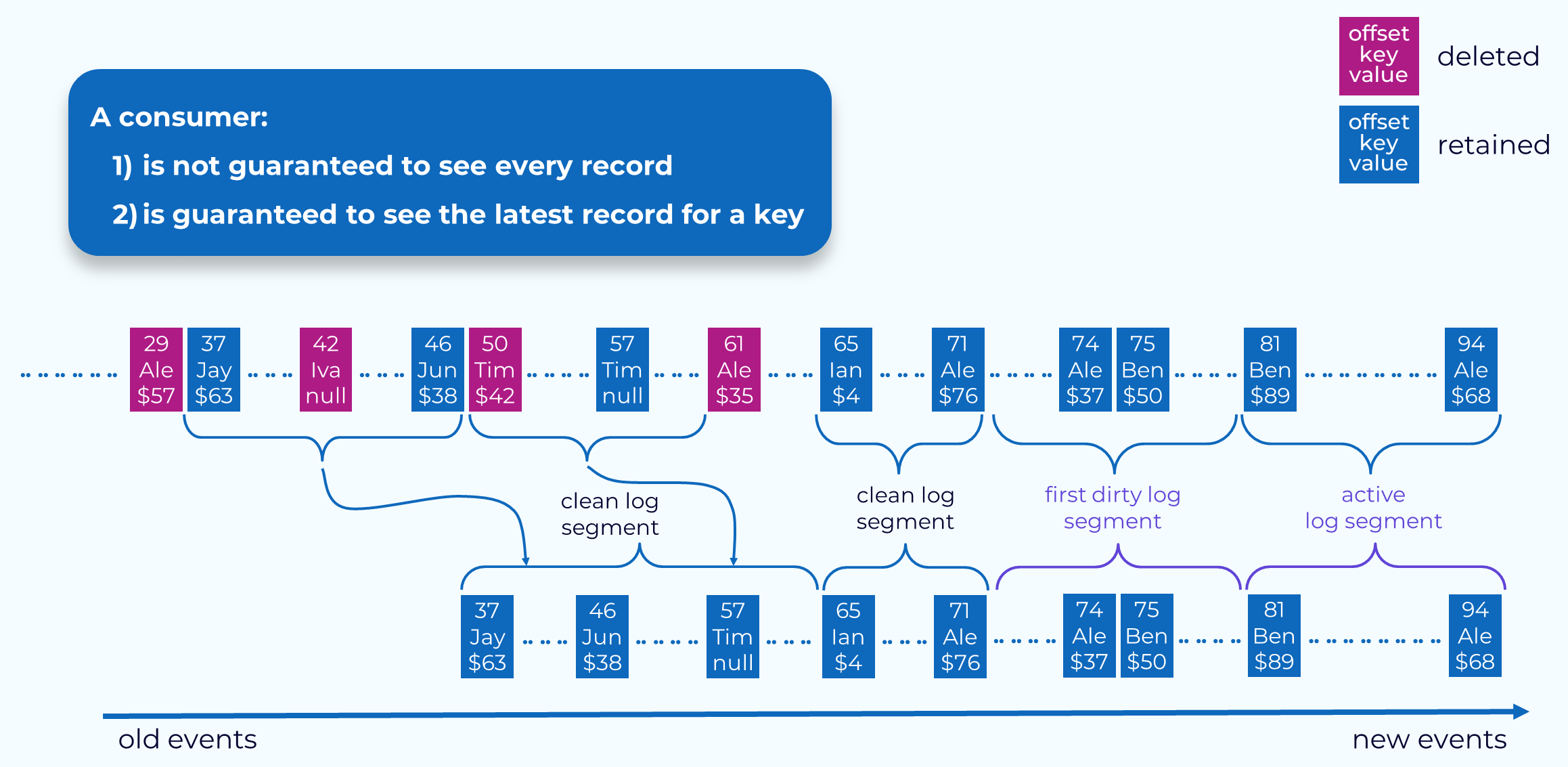
Applications reading from compacted topics are guaranteed to see the most recent value for a given key, which is the main use case for compacted topics. But keep in mind that they are not guaranteed to see every value for a given key. Some values may be deleted due to new values being appended, before the application sees them. Some extra steps are made for the case of tombstones and transaction markers, but some other types of events may still be missed.
Use the promo code INTERNALS101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Topic Compaction
Hi, everyone. Welcome back. This is Jun Rao from Confluent. In this module, I want to talk about how compaction works in Apache Kafka. (playful music) Time-Based Retention Well, most people will be mostly familiar with time-based retention in Kafka. In this case, you set up the cleaning policy to be deletion and then you set an amount of time, how long you want to keep the data in Kafka. Then as those new log segments are generated, the oldest set of log segments will be deleted over time if they pass that retention time. Now what's compaction? Compaction is a different way of retaining data. Instead of retaining data by time, it'll be retained by key. Let's take a look at this example. In this example, all the records are published with keys. Topic Compaction: key-based retention As you can see, some of the records, some of the keys, are duplicated over time. So with compaction, you basically set the cleanup policy to be compact, and then what's going to happen is over time only the records with the latest record will be kept. If you have some older records with the same key, those will be garbage collected over time like those in the pink. There's a special payload. If the payload is set to now, that's an indication that you want to delete this particular key. Then at some point, this is what we call a tombstone. It will also be cleaned up over time. So this is actually how compaction works. It is a key-based retention. What are some use cases for compaction? It's actually a pretty useful concept. It's very useful to capture all those event changes for something that's updateable like in the database table. For example, if you have a profile for the customers or you have a catalog for all the product descriptions, as those customer profiles and the product descriptions change, you may want to keep getting the latest changes of what's happening. But what compaction gives you is in addition to keeping track of the latest changes, it can also bound the total amount of space that you need to store in this topic. Because over time, all the old records with the same key, they can be garbage collected. This is actually pretty useful for applications to keep up with the incremental changes but also do some bootstrapping occasionally. So in this case, let's say, if you have applications starting from the very beginning, you may want to bootstrap its state by getting the latest value from all the keys in a particular topic. You can do this by consuming from the very beginning of the offset in a compacted topic, and once this process is done, you can continue with newer changes to this topic. So it's actually a pretty convenient way of doing this kind of thing because there's only a single Kafka topic you need to deal with instead of having to have two systems, one dealing with bootstrapping, the other dealing with incremental consumption. Now let's look at how compaction works in Kafka. Compaction Process - Segments to Clean Developer This is a compacted log. So over time, this compacted log will be divided into two parts. On the left side, these are the smaller offsets in the log. These will be the portion of what we call the cleaned log. In this portion of a log, there are no duplicate keys. All the duplicates have been removed. On the right hand side, these over time, these are the accumulated dirty segments. This is the dirty portion of the log. In those segments, the data can have duplicates among themselves. It can also duplicate some of the cleaned records as well. So the first step during cleaning is we have to determine a subset of the dirty segments to clean. The exact number of segments that you can choose depends on how much memory you have in the broker and also how many keys you have in this particular topic. Compaction Process - Build Dirty Segment Map Once we have decided the segments to clean, what we'll do is we'll scan through all of the selected dirty segments and then build an in-memory offset map. In this map, we'll be keeping the key as the key entry for the map, and for each of the keys, we'll be keeping track of the latest offset we have seen for this particular key. This will be used for cleaning subsequently. After all the segments have loaded, and these offsets have been built, we'll be going through the actual cleaning phase. In this cleaning phase, we'll be scanning Compaction Process - Deleting Events from the very beginning of this log including all of the cleaned portions of the log and the previously loaded dirty segments. As we are scanning through each of the records, we'll be using the key in the record, to do a lookup in this offset map. If the key is not present in the map, we know this record is still the latest for this key and we'll be retaining this record. If this key is present in the map, we'll be comparing the record offset with the offset stored and associated with the key in this offset map. If the record offset is higher or equal, we know this other record is still the latest record for this particular key and it will be retaining this record. Otherwise this record will be deleted. So once we know which records need to be retained, Compaction Process - Retaining Events we'll be copying over those retained records into a new set of segments. When we are copying them over to the new segments, we'll be preserving the exact offsets of those records as they are in the old segments. This means, between two consecutive records, there could be some holes in the offsets because some of the records in the middle could have been deleted. This is fine because the consumer application knows how to skip those holes in the offset gap. Once those new segments have been generated, Compaction Process - Replace Old Segments we'll be doing a swap of the old segments with the newest ones. Now if you have a consumer that tries to ask to consume some of the data within this offset range it will be directed to the new set of segments. And over time we'll be deleting the old segments. Once the cleaning process is done, we will also save the position which is the offset of the last dirty segments we have loaded into the map so that if the broker fails and starts over again, it will be resuming the cleaning from this particular offset afterwards for subsequent cleaning. Cleaning Tombstone and Transaction Markers Okay, now let's take a look at how we can clean tombstones. This can be a little tricky because if we are not very careful, we can get into a situation where some of the delete records will never be propagated to the application. So this example shows this. So let's say we have this record at an offset in the 50s. This record is subsequently deleted because we have a key within our payload at offset 57. So when we try to clean this segment, the naive way is we can remove both the record in the 50s and the record 57 because the key is subsequently deleted. But if we do that, it's possible for an application that has just finished reading the record at the 50s offset and then took a pause, and then when it resumed consumption, it will no longer find the deleted record at offset 57. Then in this particular case, it just means this application will never realize that particular key has been deleted. Similar issue can happen if we are deleting a transactional marker too early. In this case, for example, we have this record as part of a transaction which is aborted, and if you remove this aborted record and the transaction aborted marker, together too quickly, then we can have the same situation where a consumer may have read this aborted record but without reading the marker. So it doesn't know this actually is aborted. So to solve this issue, when we are dealing with the tombstone deletion we clean in two separate rounds. In the first round of cleaning, we will only remove the record in the 50s, but we'll leave the tombstone marker at offset 57 as it is. When we keep it, we also set a time for when it can be safely deleted. And that time is set from the time when we clean the record plus a configured amount of retention time. So the expectation is an application within this amount of time is expected to finish consuming all of this partition's data, all the way to the end. So by retaining this data for long enough, now we will allow the applications enough time to finish resuming the consumption of this deleted marker, and after that, we can safely delete the tombstone. And we can do the same thing for the transaction marker as well. Now, when this compaction is triggered, When Compaction is Triggered A topic partition is compacted if one of the following is true this is controlled with a few of the parameters. By default, we don't want the cleaning to happen too frequently because it can be resource-intensive. So instead, what we want to do is to balance the cleaning with the amount of dirty data we have accumulated. So we'll be measuring how much additional dirty portion of the data we have accumulated and will compare that with the total amount of data we have accumulated in this log. If that exceeded a certain threshold, by default, it's like 50%, then we'll be triggering a cleaning. Some applications may want to defer the cleaning a little bit because they may want to see every record if possible. So in this case, they can set like a minimum amount of delay for compaction, and then the clean will happen after that. Some applications don't want to see duplicates too much. So they want to be able to clean the data as aggressively as possible. For them, they can also set a max-compaction lag, in this case, it will be cleaning the data if it's older than this amount of time. To summarize, compaction is a very effective way Topic Compaction Guarantees of retaining the data by keys and is very important for applications that want to keep track with updateable records by key. The guarantees you have when you use compaction is you are always guaranteed to see the latest record for a particular key, but you are just not always guaranteed to see every update of the record for every key. And that's it for this module. Thanks for listening.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.