Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Consumer Group Protocol



Jun Rao
Co-Founder, Confluent (Presenter)
Consumer Group Protocol
Kafka separates storage from compute. Storage is handled by the brokers and compute is mainly handled by consumers or frameworks built on top of consumers (Kafka Streams, ksqlDB). Consumer groups play a key role in the effectiveness and scalability of Kafka consumers.
Kafka Consumer Group
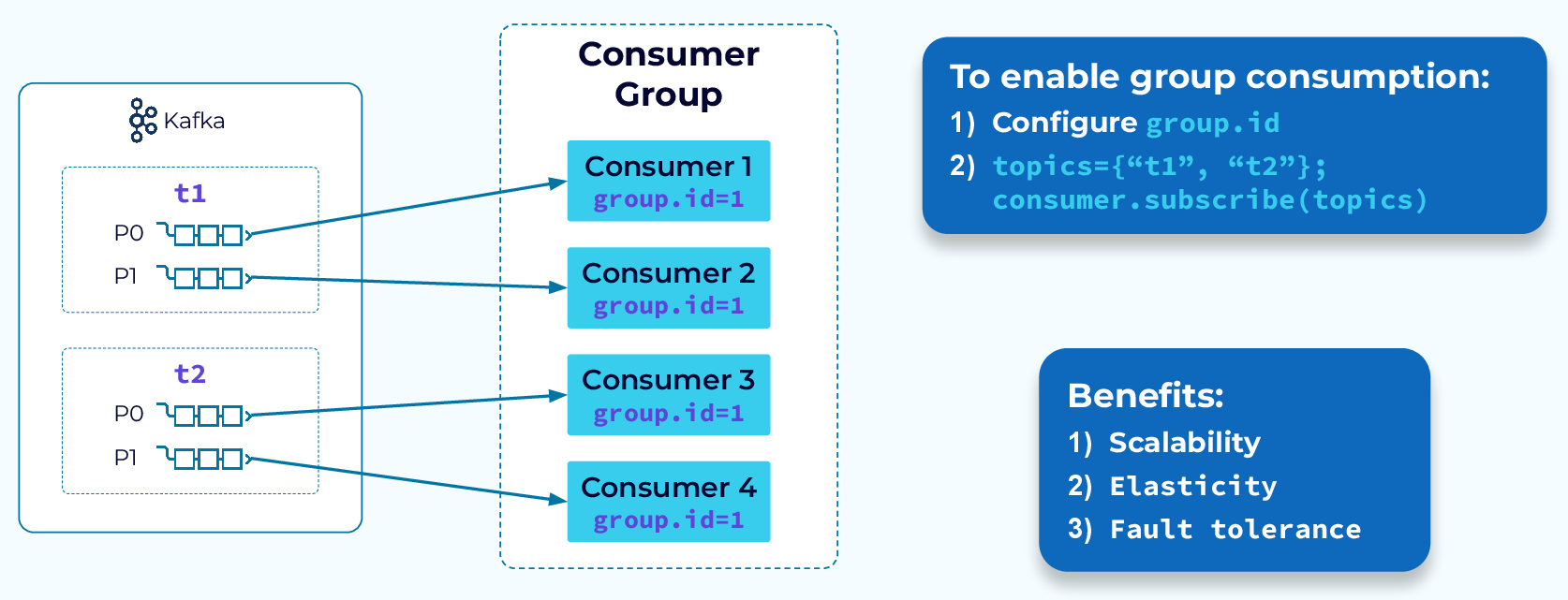
To define a consumer group we just need to set the group.id in the consumer config. Once that is set, every new instance of that consumer will be added to the group. Then, when the consumer group subscribes to one or more topics, their partitions will be evenly distributed between the instances in the group. This allows for parallel processing of the data in those topics.
The unit of parallelism is the partition. For a given consumer group, consumers can process more than one partition but a partition can only be processed by one consumer. If our group is subscribed to two topics and each one has two partitions then we can effectively use up to four consumers in the group. We could add a fifth but it would sit idle since partitions cannot be shared.
The assignment of partitions to consumer group instances is dynamic. As consumers are added to the group, or when consumers fail or are removed from the group for some other reason, the workload will be rebalanced automatically.
Group Coordinator
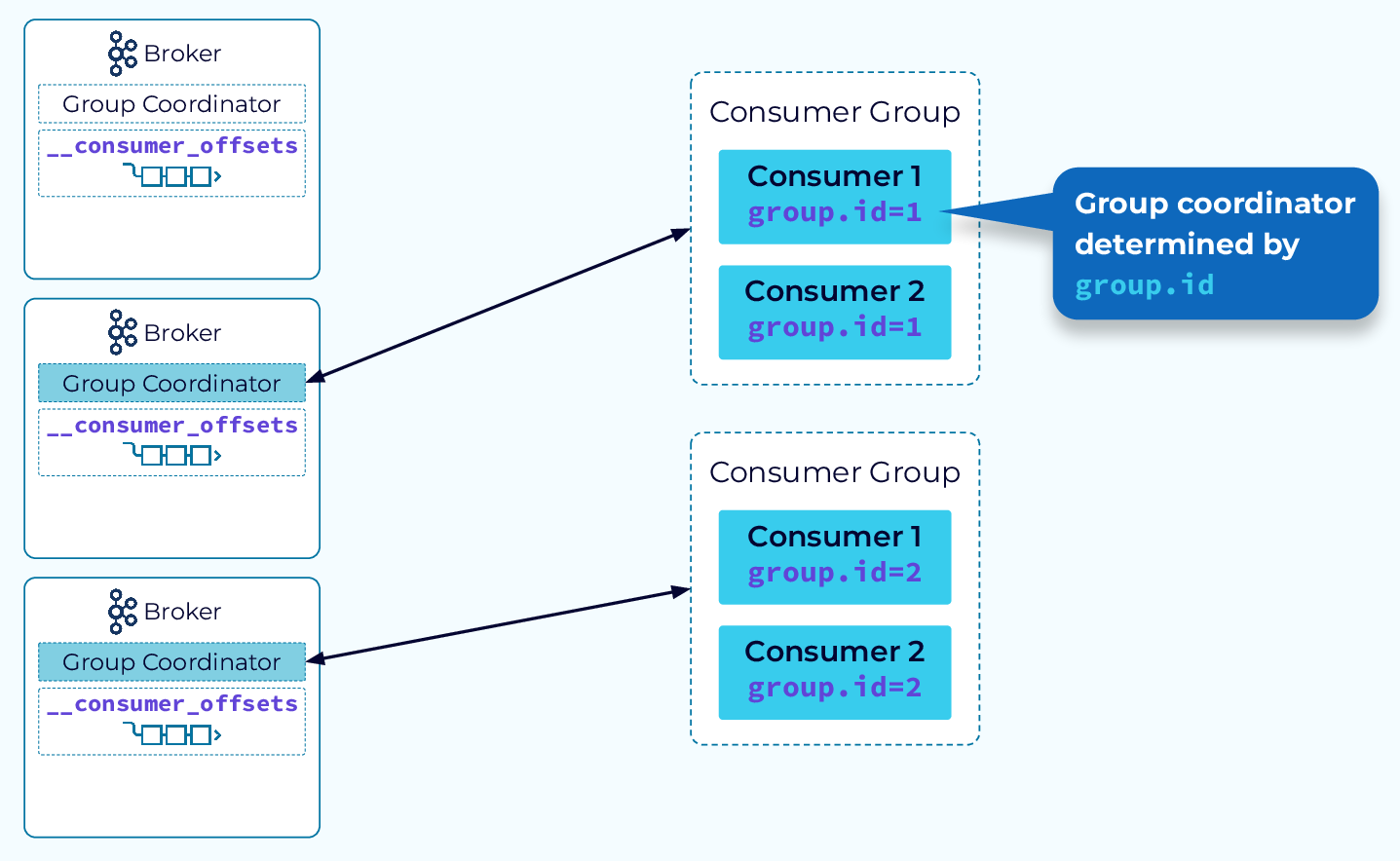
The magic behind consumer groups is provided by the group coordinator. The group coordinator helps to distribute the data in the subscribed topics to the consumer group instances evenly and it keeps things balanced when group membership changes occur. The coordinator uses an internal Kafka topic to keep track of group metadata.
In a typical Kafka cluster, there will be multiple group coordinators. This allows for multiple consumer groups to be managed efficiently.
Group Startup
Let’s take a look at the steps involved in starting up a new consumer group.
Step 1 – Find Group Coordinator
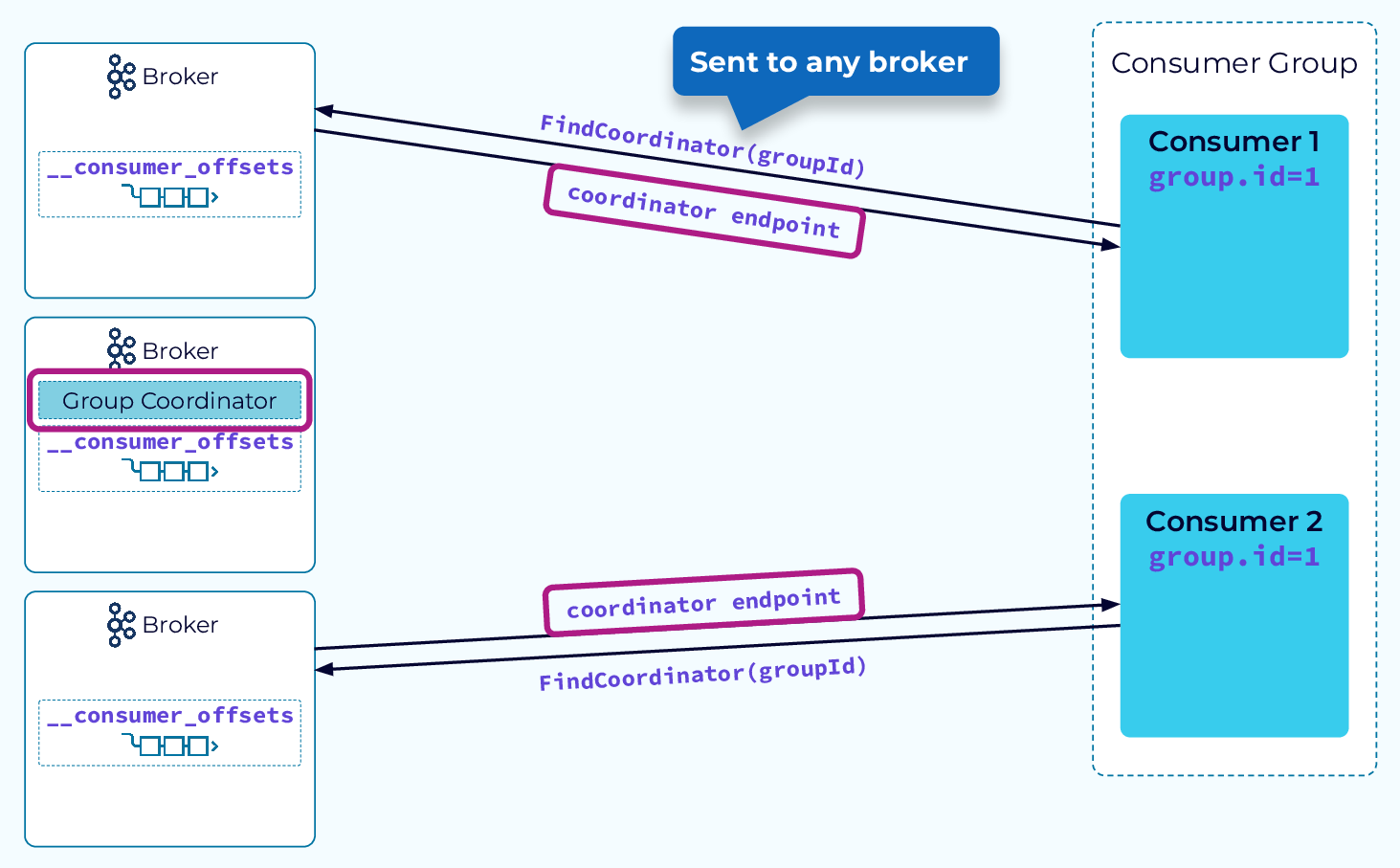
When a consumer instance starts up it sends a FindCoordinator request that includes its group.id to any broker in the cluster. The broker will create a hash of the group.id and modulo that against the number of partitions in the internal __consumer_offsets topic. That determines the partition that all metadata events for this group will be written to. The broker that hosts the leader replica for that partition will take on the role of group coordinator for the new consumer group. The broker that received the FindCoordinator request will respond with the endpoint of the group coordinator.
Step 2 – Members Join
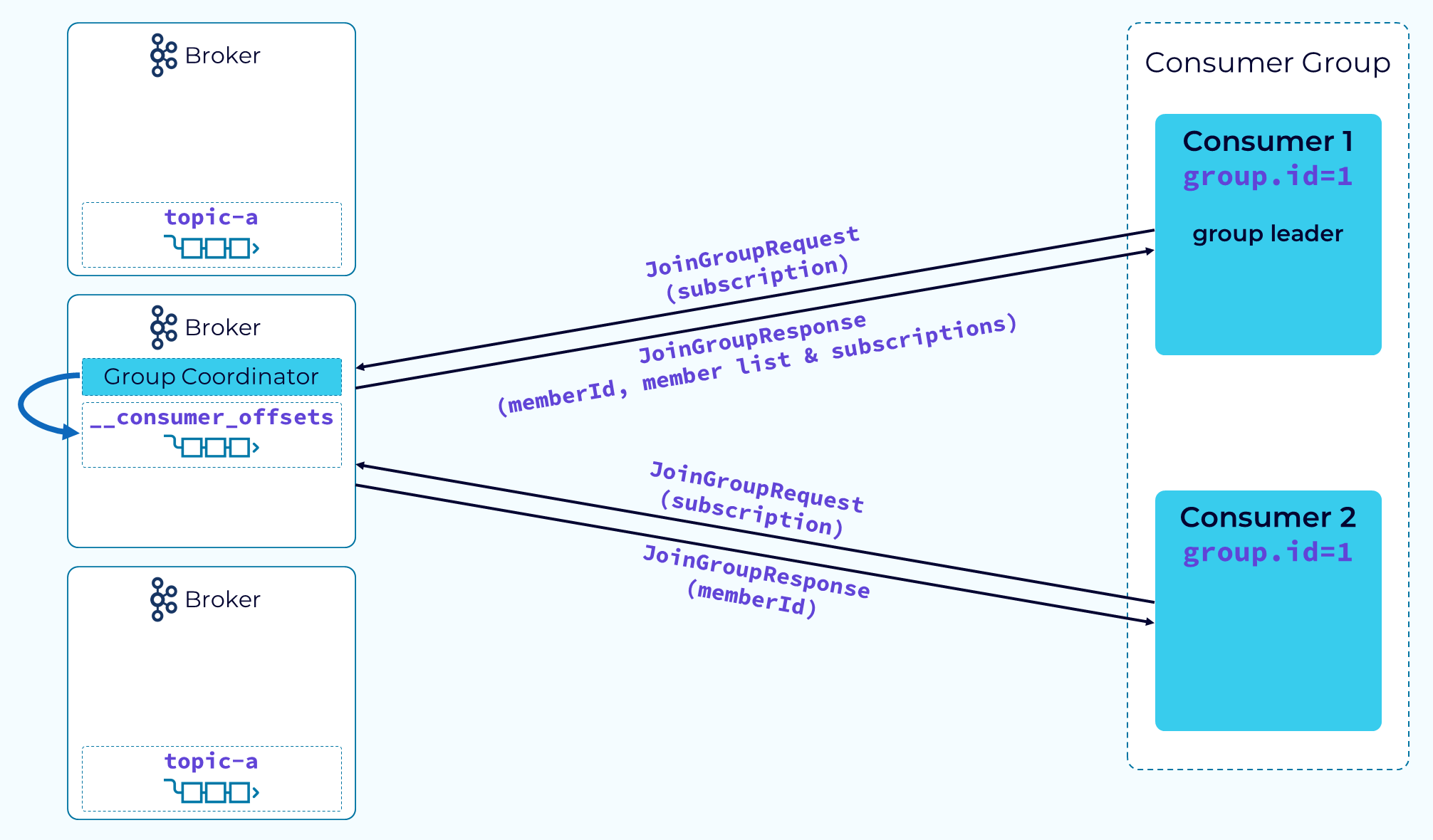
Next, the consumers and the group coordinator begin a little logistical dance, starting with the consumers sending a JoinGroup request and passing their topic subscription information. The coordinator will choose one consumer, usually the first one to send the JoinGroup request, as the group leader. The coordinator will return a memberId to each consumer, but it will also return a list of all members and the subscription info to the group leader. The reason for this is so that the group leader can do the actual partition assignment using a configurable partition assignment strategy.
Step 3 – Partitions Assigned
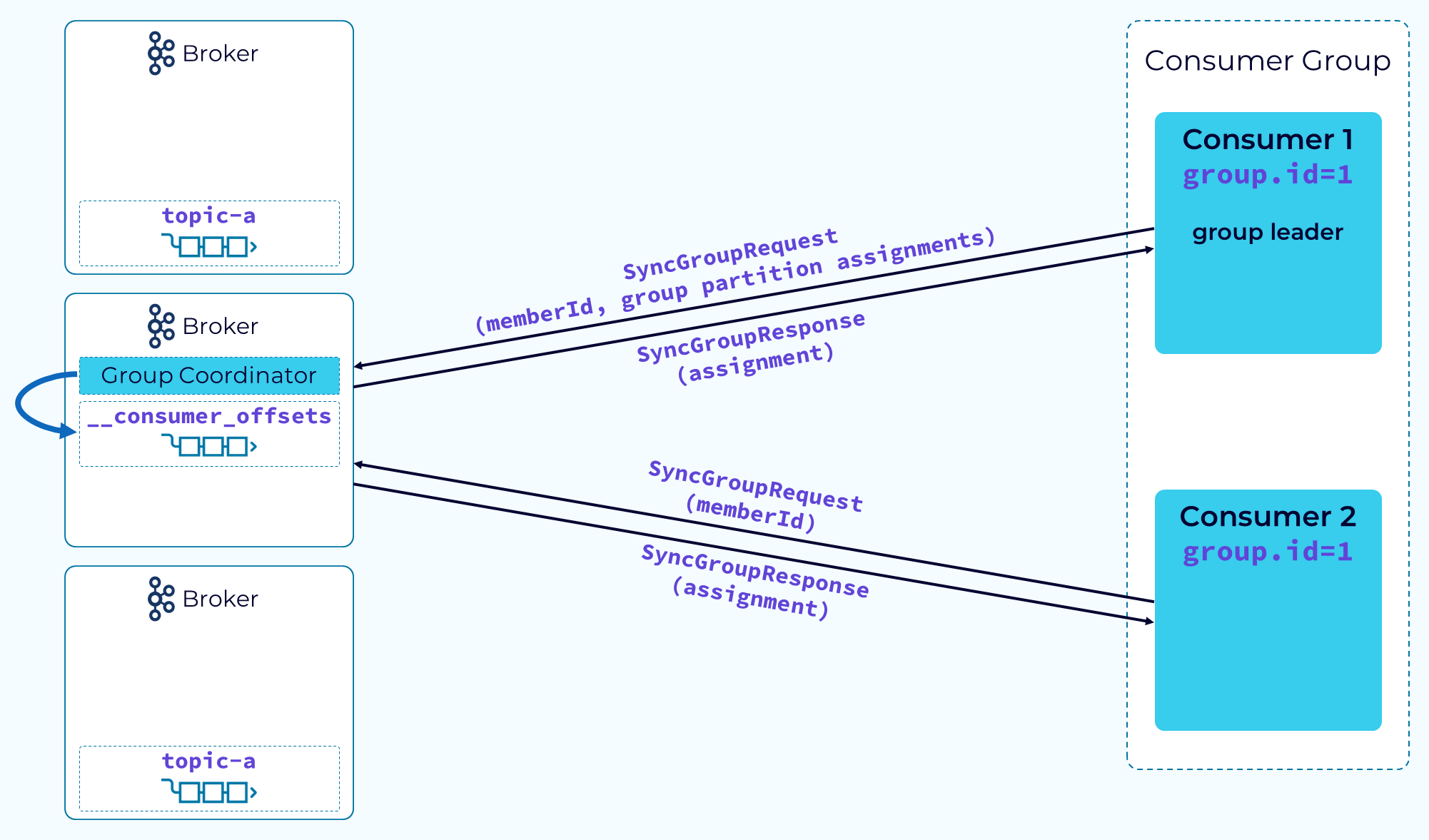
After the group leader receives the complete member list and subscription information, it will use its configured partitioner to assign the partitions in the subscription to the group members. With that done, the leader will send a SyncGroupRequest to the coordinator, passing in its memberId and the group assignments provided by its partitioner. The other consumers will make a similar request but will only pass their memberId. The coordinator will use the assignment information given to it by the group leader to return the actual assignments to each consumer. Now the consumers can begin their real work of consuming and processing data.
Range Partition Assignment Strategy
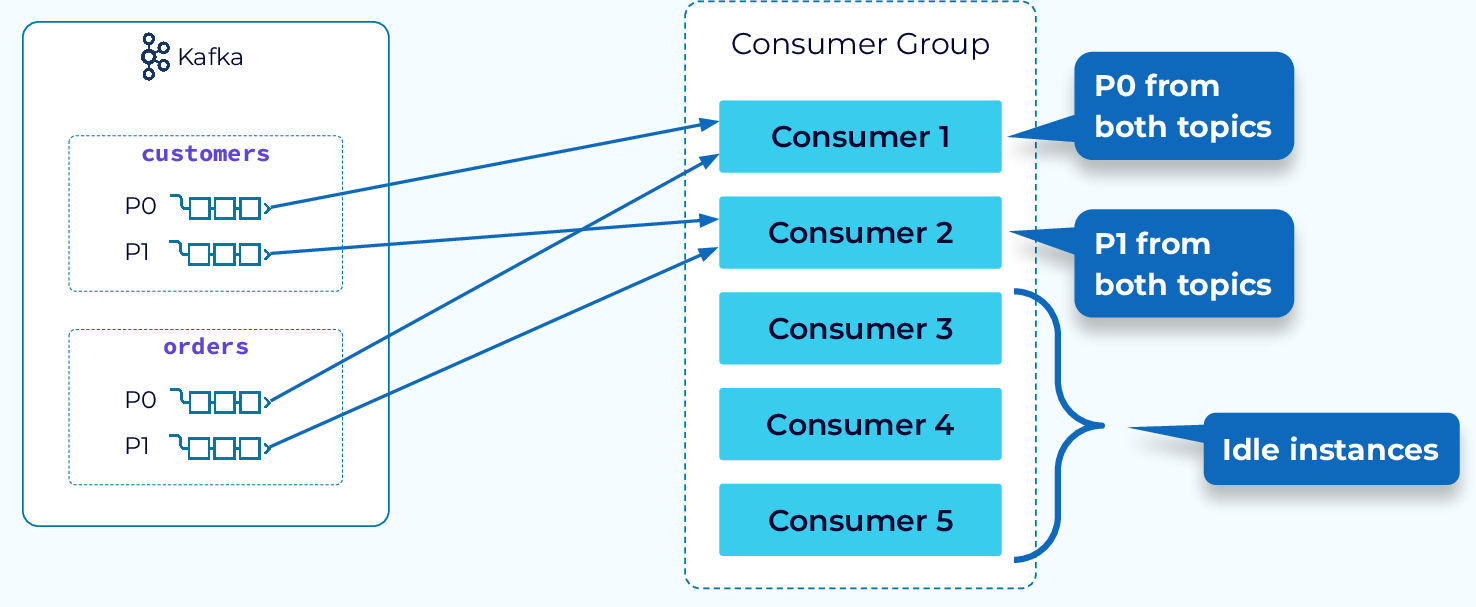
Now, let's look at some of the available assignment strategies. First up is the range assignment strategy. This strategy goes through each topic in the subscription and assigns each of the partitions to a consumer, starting at the first consumer. What this means is that the first partition of each topic will be assigned to the first consumer, the second partition of each topic will be assigned to the second consumer, and so on. If no single topic in the subscription has as many partitions as there are consumers, then some consumers will be idle.
At first glance this might not seem like a very good strategy, but it has a very special purpose. When joining events from more than one topic the events need to be read by the same consumer. If events in two different topics are using the same key, they will be in the same partition of their respective topics, and with the range partitioner, they will be assigned to the same consumer.
Round Robin and Sticky Partition Assignment Strategies
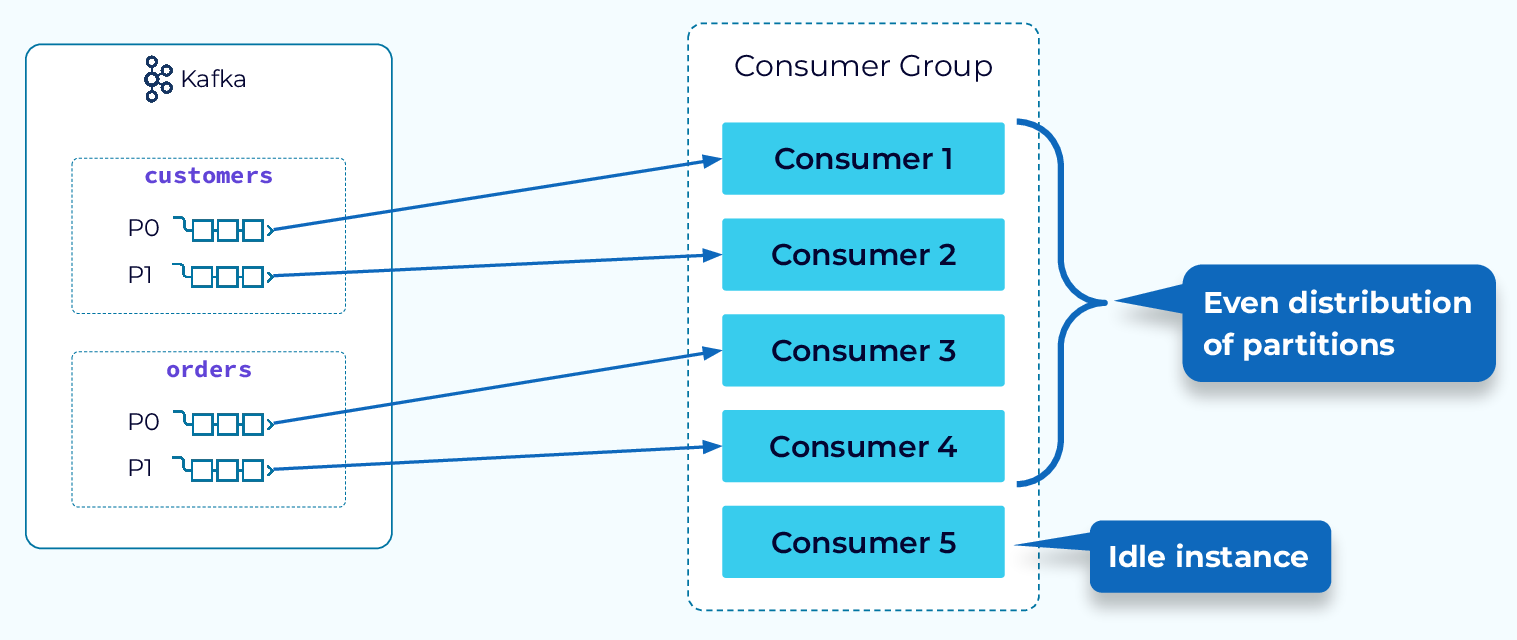
Next, let’s look at the Round Robin strategy. With this strategy, all of the partitions of the subscription, regardless of topic, will be spread evenly across the available consumers. This results in fewer idle consumer instances and a higher degree of parallelism.
A variant of Round Robin, called the Sticky Partition strategy, operates on the same principle but it makes a best effort at sticking to the previous assignment during a rebalance. This provides a faster, more efficient rebalance.
Tracking Partition Consumption
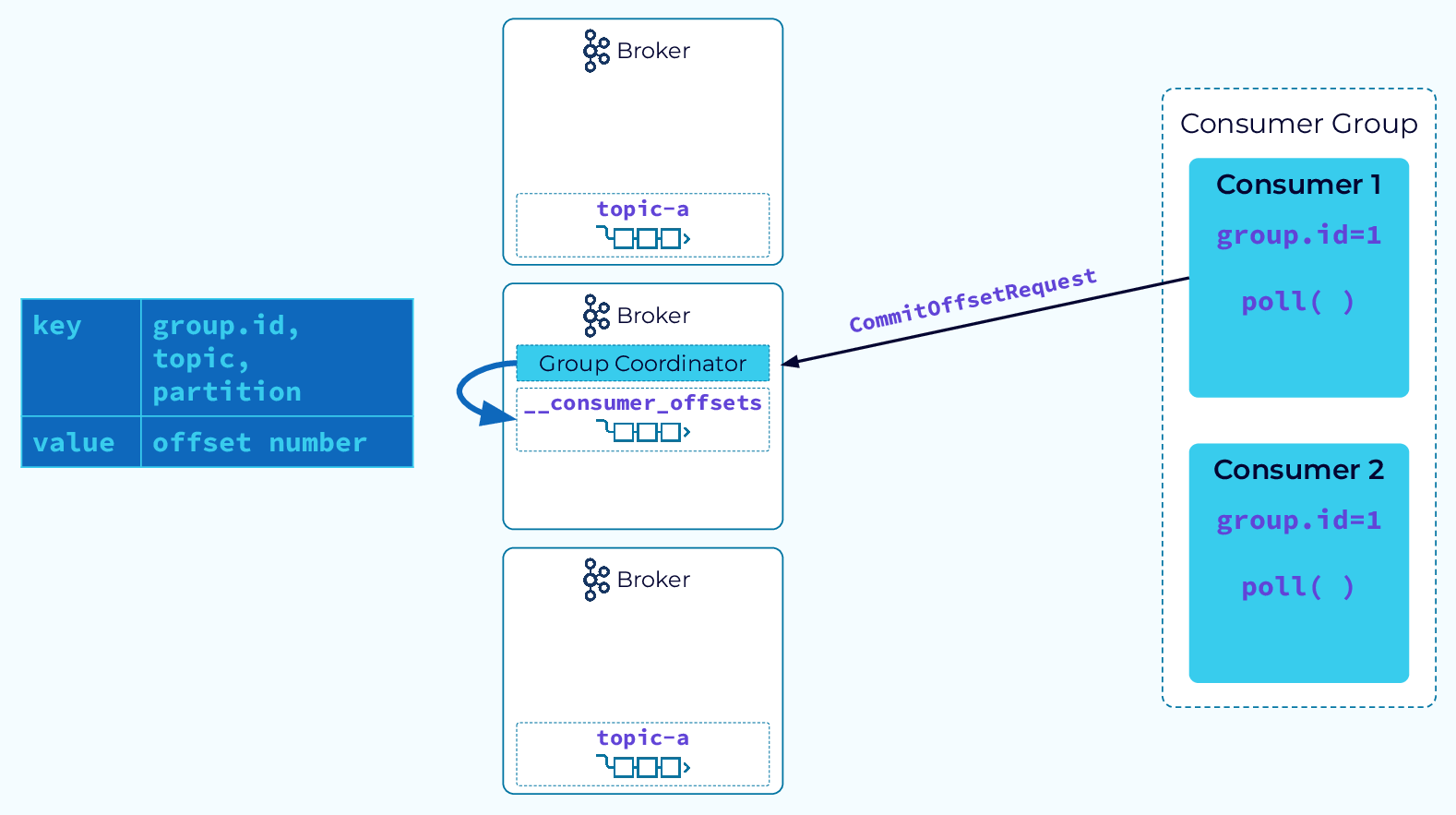
In Kafka, keeping track of the progress of a consumer is relatively simple. A given partition is always assigned to a single consumer, and the events in that partition are always read by the consumer in offset order. So, the consumer only needs to keep track of the last offset it has consumed for each partition. To do this, the consumer will issue a CommitOffsetRequest to the group coordinator. The coordinator will then persist that information in its internal __consumer_offsets topic.
Determining Starting Offset to Consume
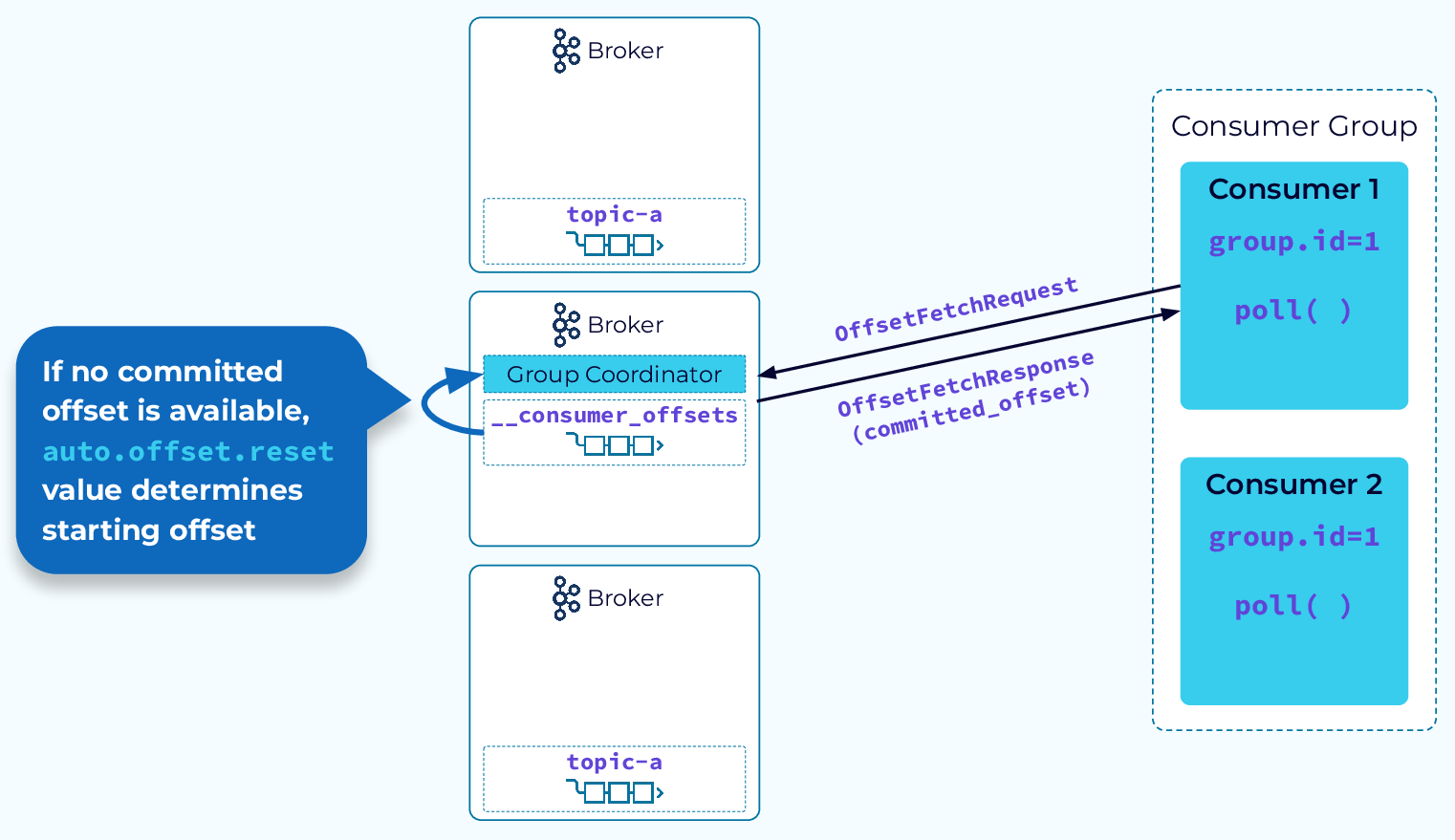
When a consumer group instance is restarted, it will send an OffsetFetchRequest to the group coordinator to retrieve the last committed offset for its assigned partition. Once it has the offset, it will resume the consumption from that point. If this consumer instance is starting for the very first time and there is no saved offset position for this consumer group, then the auto.offset.reset configuration will determine whether it begins consuming from the earliest offset or the latest.
Group Coordinator Failover
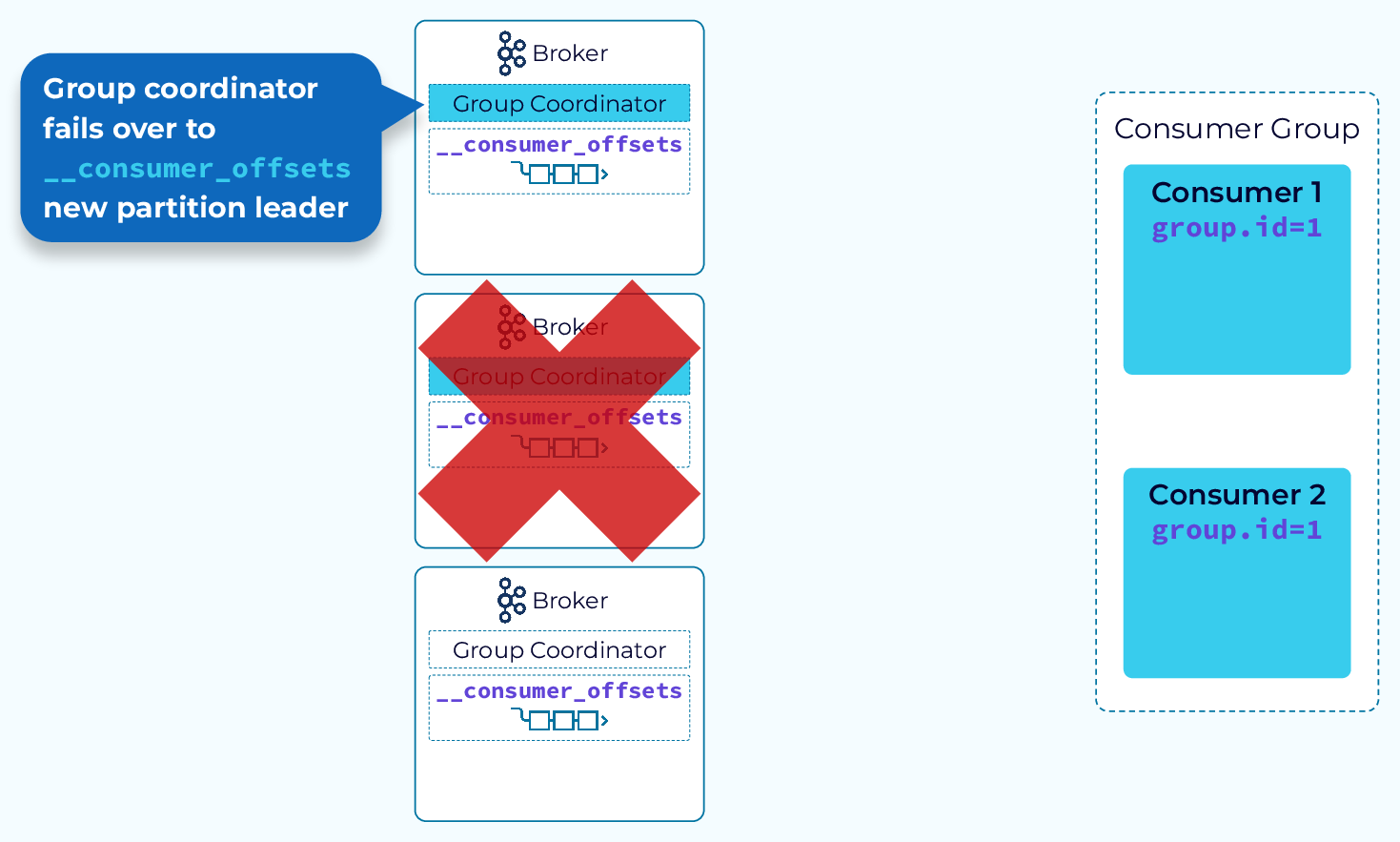
The internal __consumer_offsets topic is replicated like any other Kafka topic. Also, recall that the group coordinator is the broker that hosts the leader replica of the __consumer_offsets partition assigned to this group. So if the group coordinator fails, a broker that is hosting one of the follower replicas of that partition will become the new group coordinator. Consumers will be notified of the new coordinator when they try to make a call to the old one, and then everything will continue as normal.
Consumer Group Rebalance Triggers
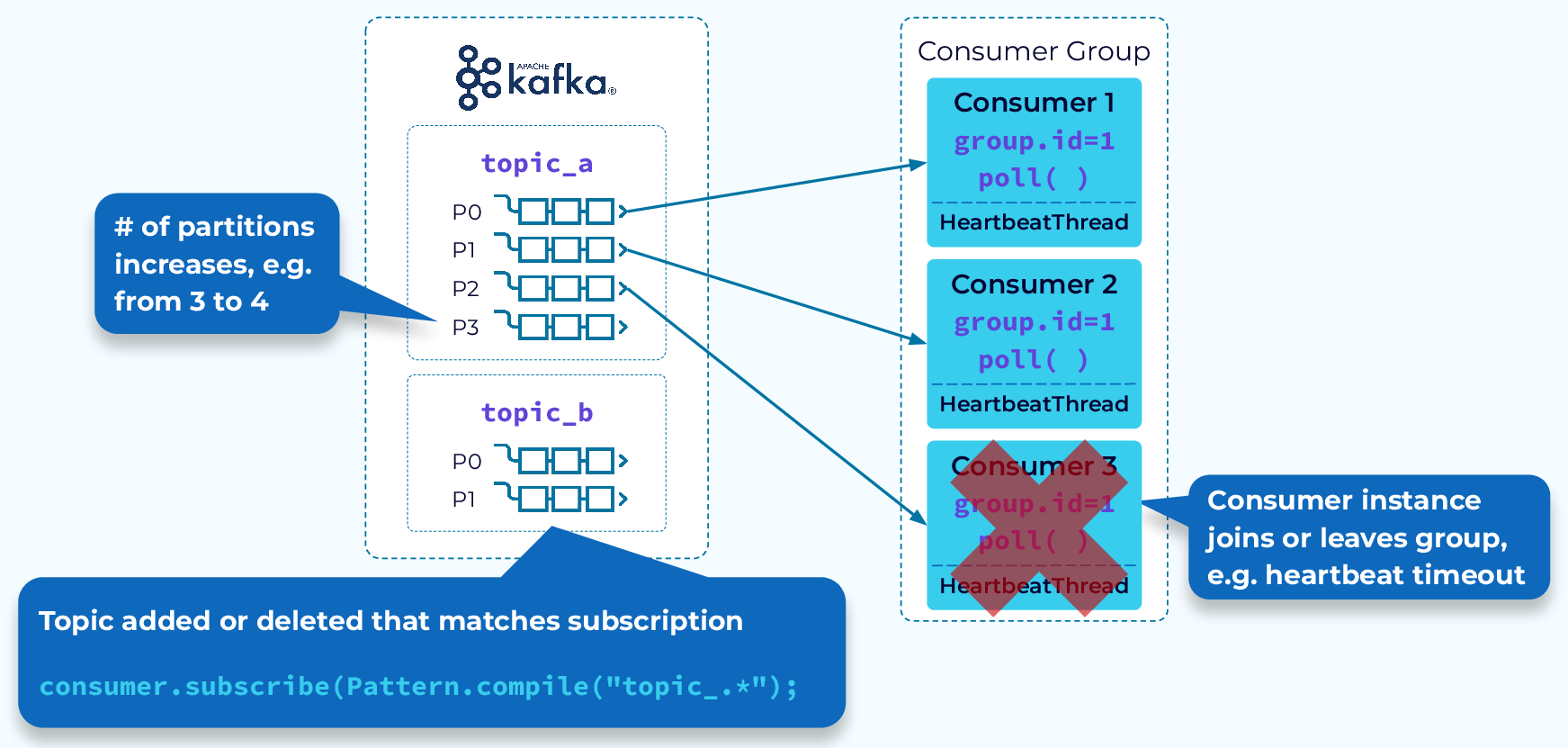
One of the key features of consumer groups is rebalancing. We’ll be discussing rebalances in more detail, but first let's consider some of the events that can trigger a rebalance:
- An instance fails to send a heartbeat to the coordinator before the timeout and is removed from the group
- An instance has been added to the group
- Partitions have been added to a topic in the group’s subscription
- A group has a wildcard subscription and a new matching topic is created
- And, of course, initial group startup
Next we’ll look at what happens when a rebalance occurs.
Consumer Group Rebalance Notification
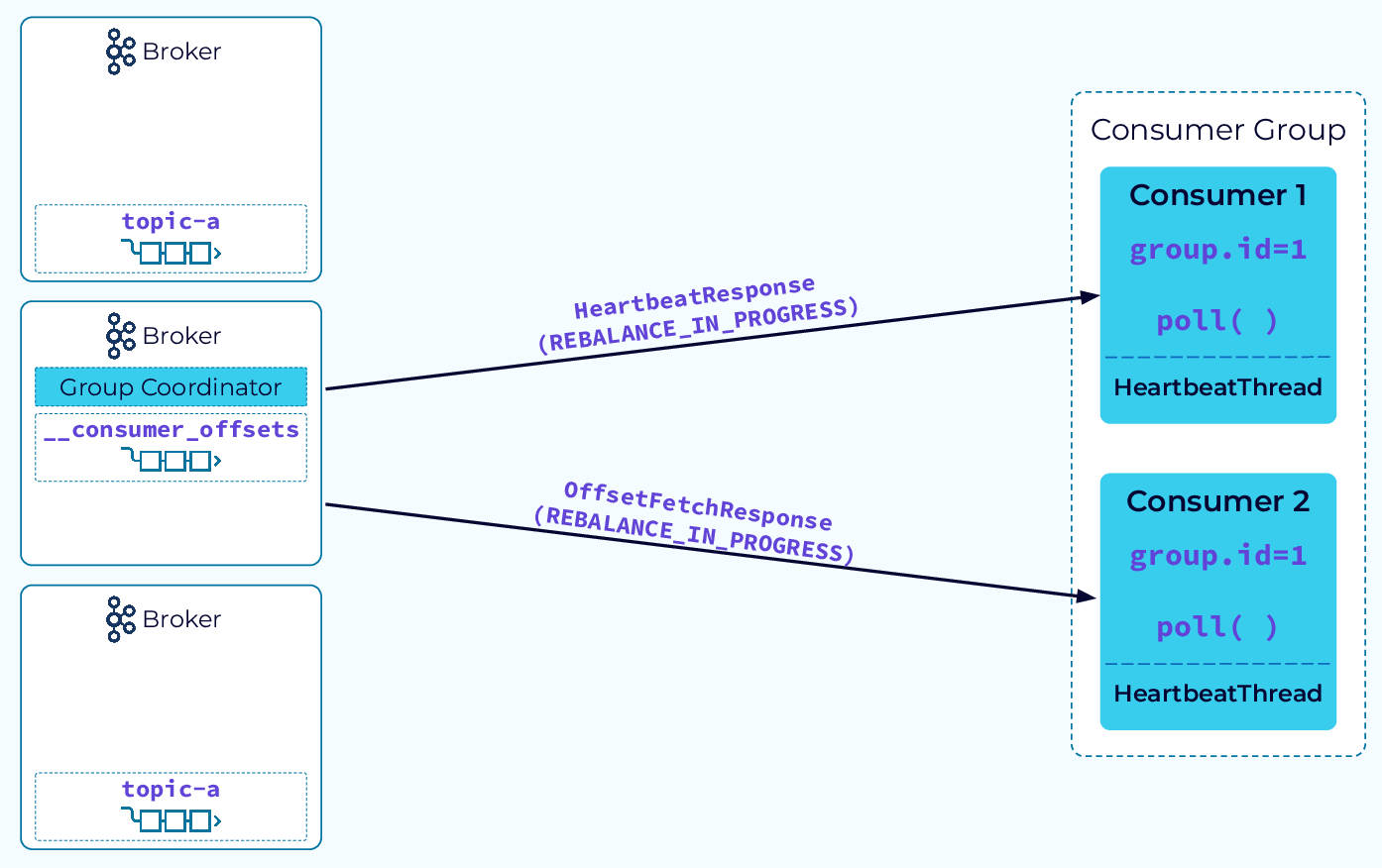
The rebalance process begins with the coordinator notifying the consumer instances that a rebalance has begun. It does this by piggybacking on the HeartbeatResponse or the OffsetFetchResponse. Now the fun begins!
Stop-the-World Rebalance
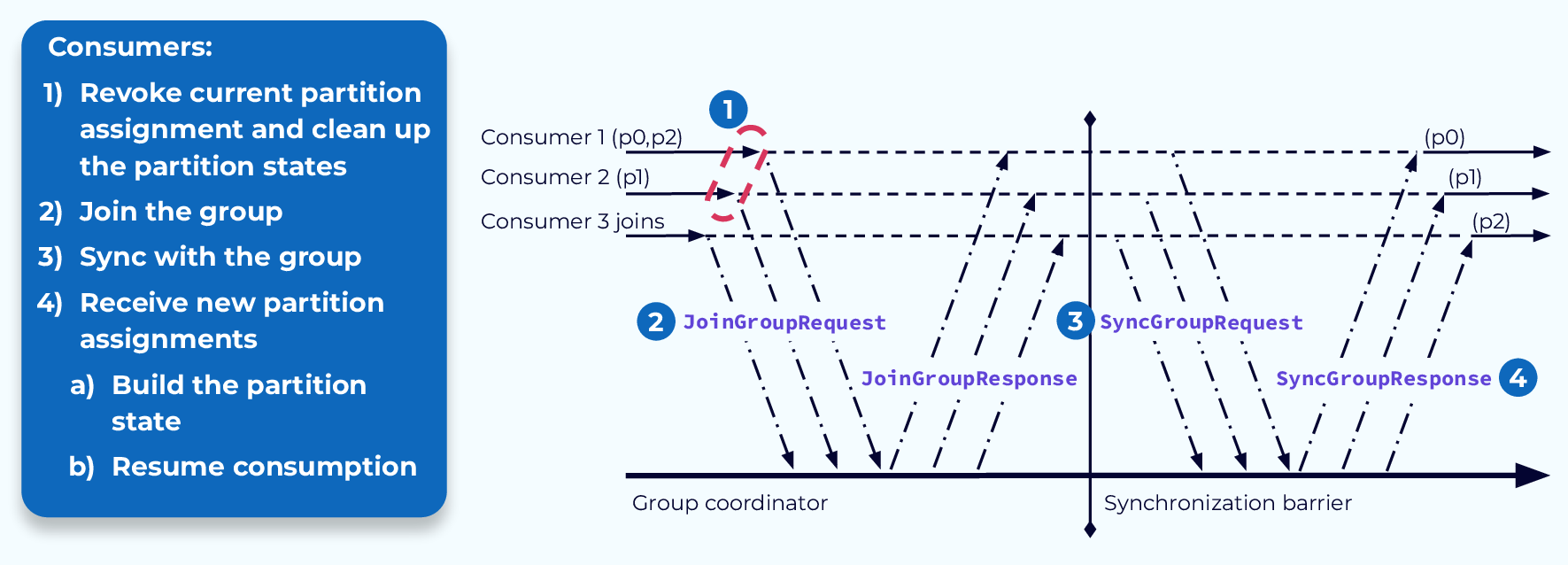
The traditional rebalance process is rather involved. Once the consumers receive the rebalance notification from the coordinator, they will revoke their current partition assignments. If they have been maintaining any state associated with the data in their previously assigned partitions, they will also have to clean that up. Now they are basically like new consumers and will go through the same steps as a new consumer joining the group.
They will send a JoinGroupRequest to the coordinator, followed by a SyncGroupRequest. The coordinator will respond accordingly, and the consumers will each have their new assignments.
Any state that is required by the consumer would now have to be rebuilt from the data in the newly assigned partitions. This process, while effective, has some drawbacks. Let’s look at a couple of those now.
Stop-the-World Problem #1 – Rebuilding State
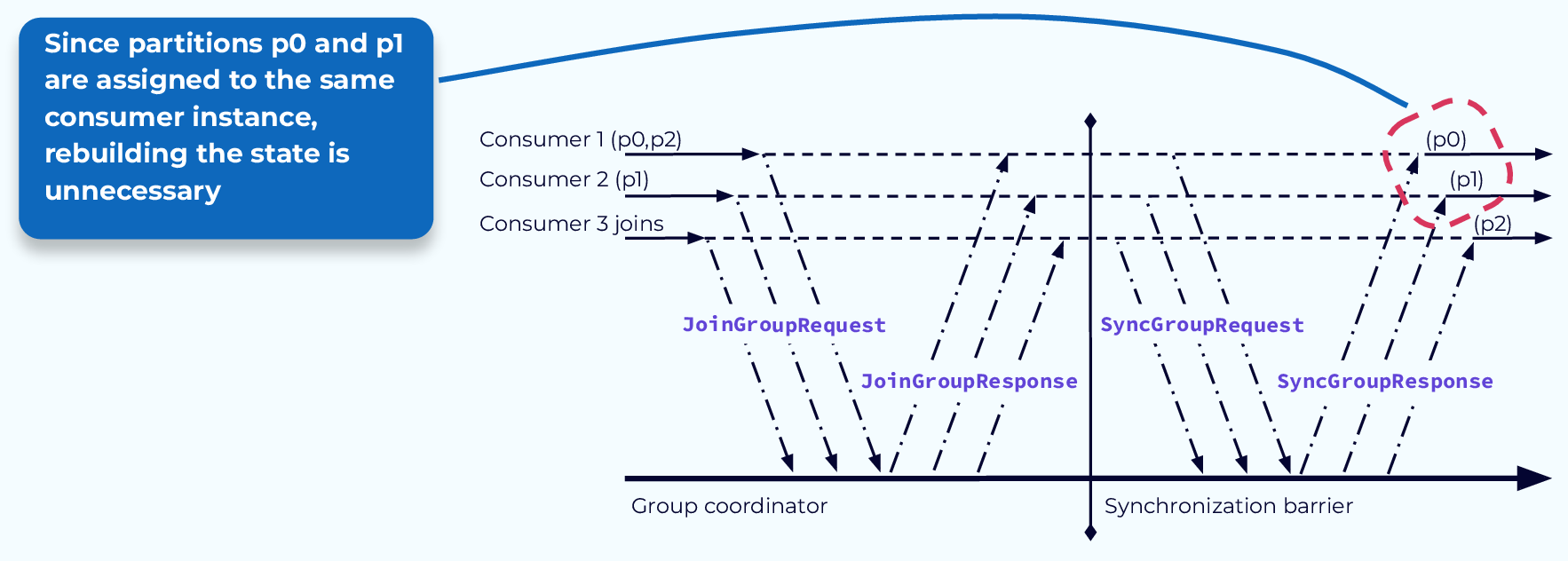
The first problem is the need to rebuild state. If a consumer application was maintaining state based on the events in the partition it had been assigned to, it may need to read all of the events in the partition to rebuild that state after the rebalance is complete. As you can see from our example, sometimes this work is being done even when it is not needed. If a consumer revokes its assignment to a particular partition and then is assigned that same partition during the rebalance, a significant amount of wasted processing may occur.
Stop-the-World Problem #2 – Paused Processing
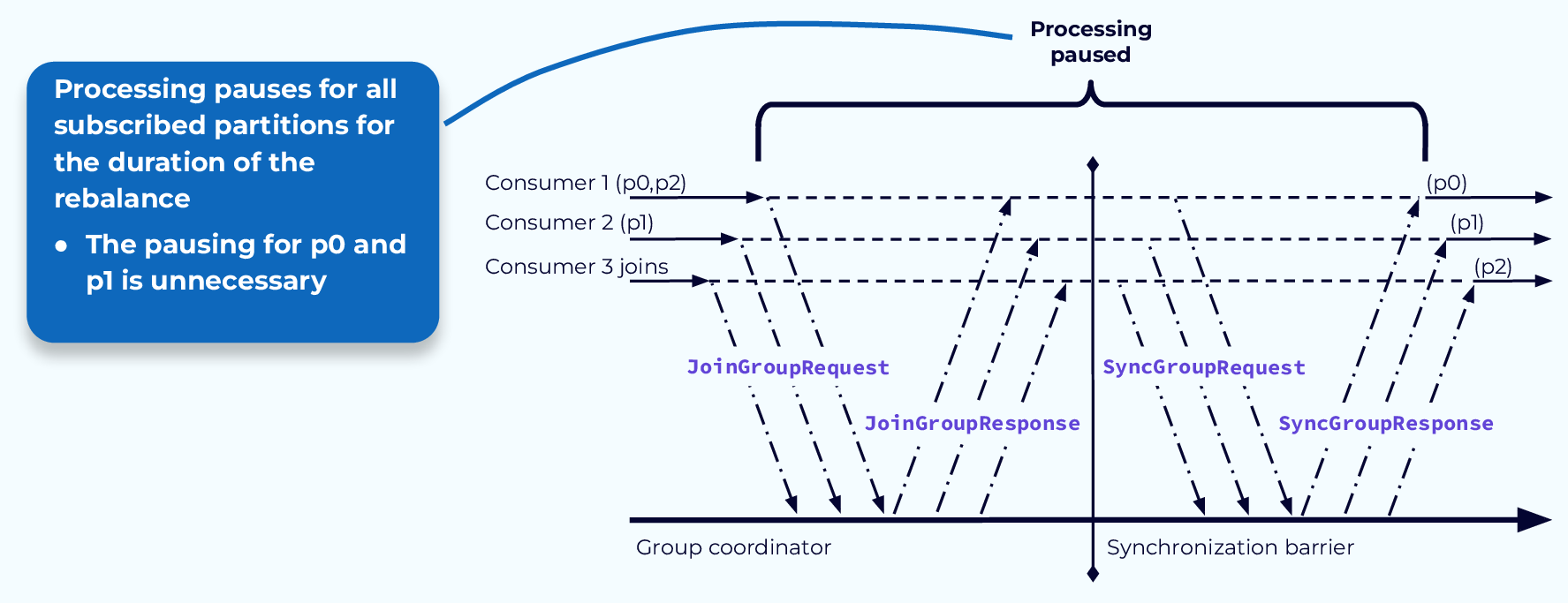
The second problem is that we’re required to pause all processing while the rebalance is occurring, hence the name “Stop-the-world.” Since the partition assignments for all consumers are revoked at the beginning of the process, nothing can happen until the process completes and the partitions have been reassigned. In many cases, as in our example here, some consumers will keep some of the same partitions and could have, in theory, continued working with them while the rebalance was underway.
Let’s see some of the improvements that have been made to deal with these problems.
Avoid Needless State Rebuild with StickyAssignor
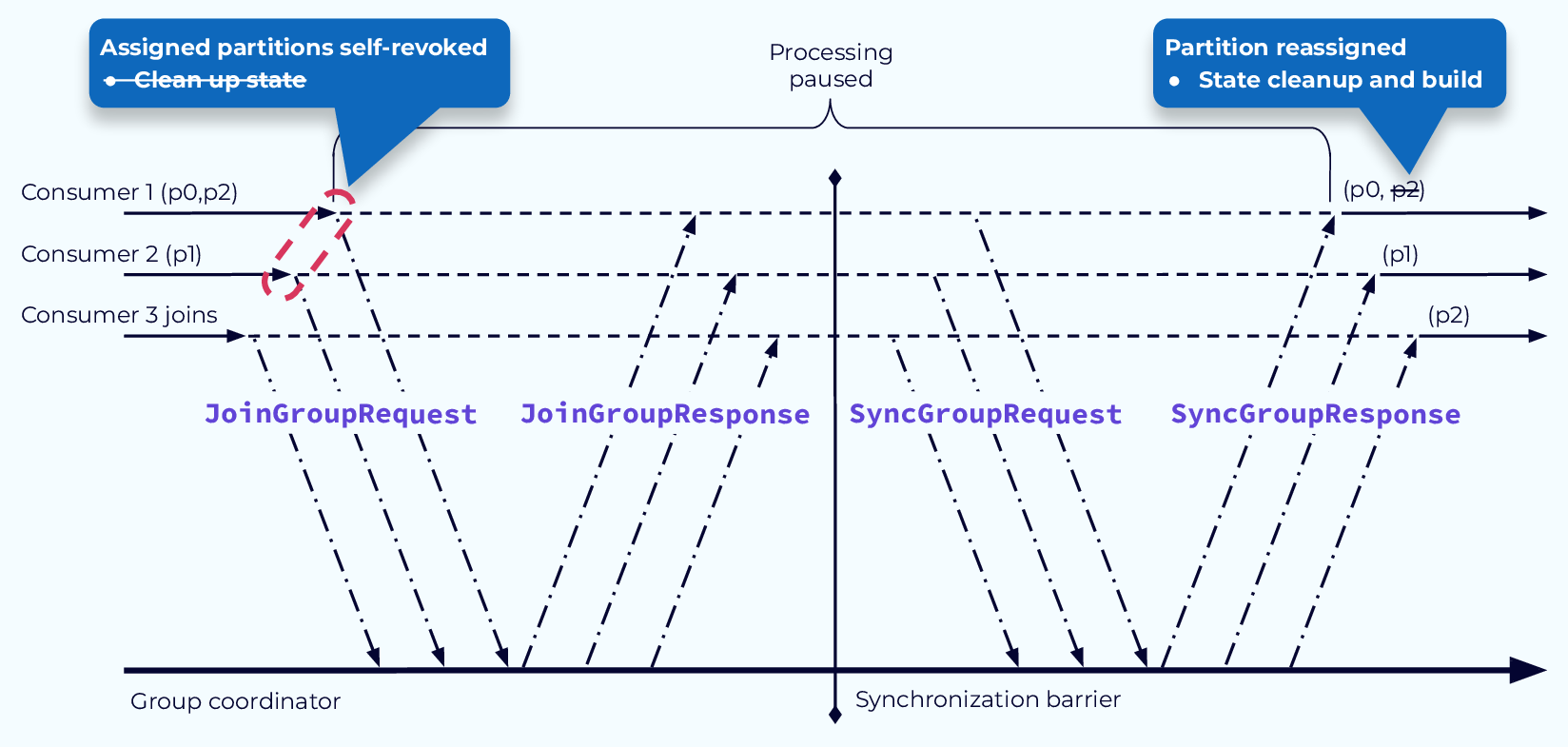
First, using the new StickyAssignor we can avoid unnecessary state rebuilding. The main difference with the StickyAssignor, is that the state cleanup is moved to a later step, after the reassignments are complete. That way if a consumer is reassigned the same partition it can just continue with its work and not clear or rebuild state. In our example, state would only need to be rebuilt for partition p2, which is assigned to the new consumer.
Avoid Pause with CooperativeStickyAssignor Step 1
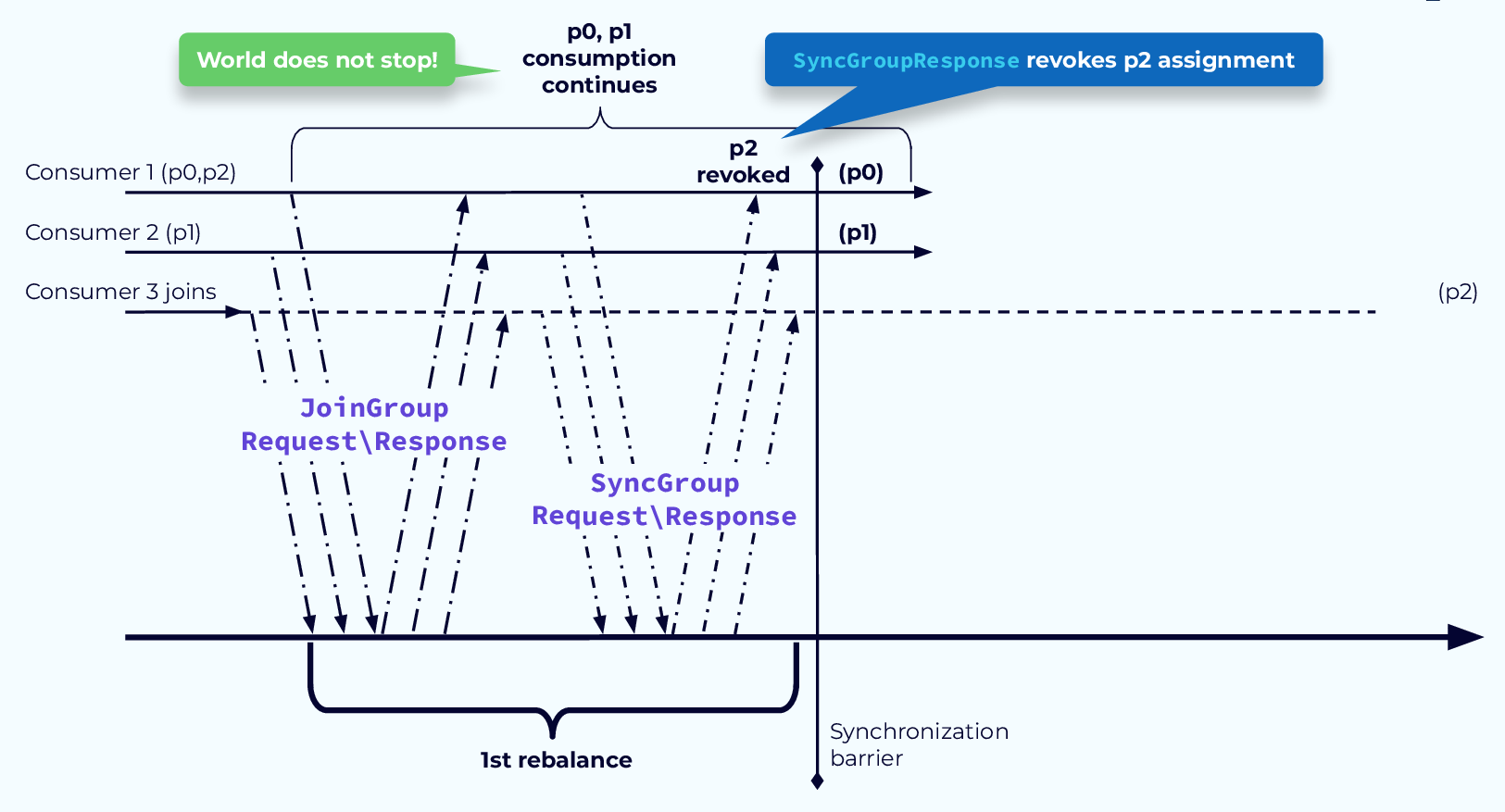
To solve the problem of paused processing, we introduced the CooperativeStickyAssignor. This assignor works in a two-step process. In the first step the determination is made as to which partition assignments need to be revoked. Those assignments are revoked at the end of the first rebalance step. The partitions that are not revoked can continue to be processed.
Avoid Pause with CooperativeStickyAssignor Step 2
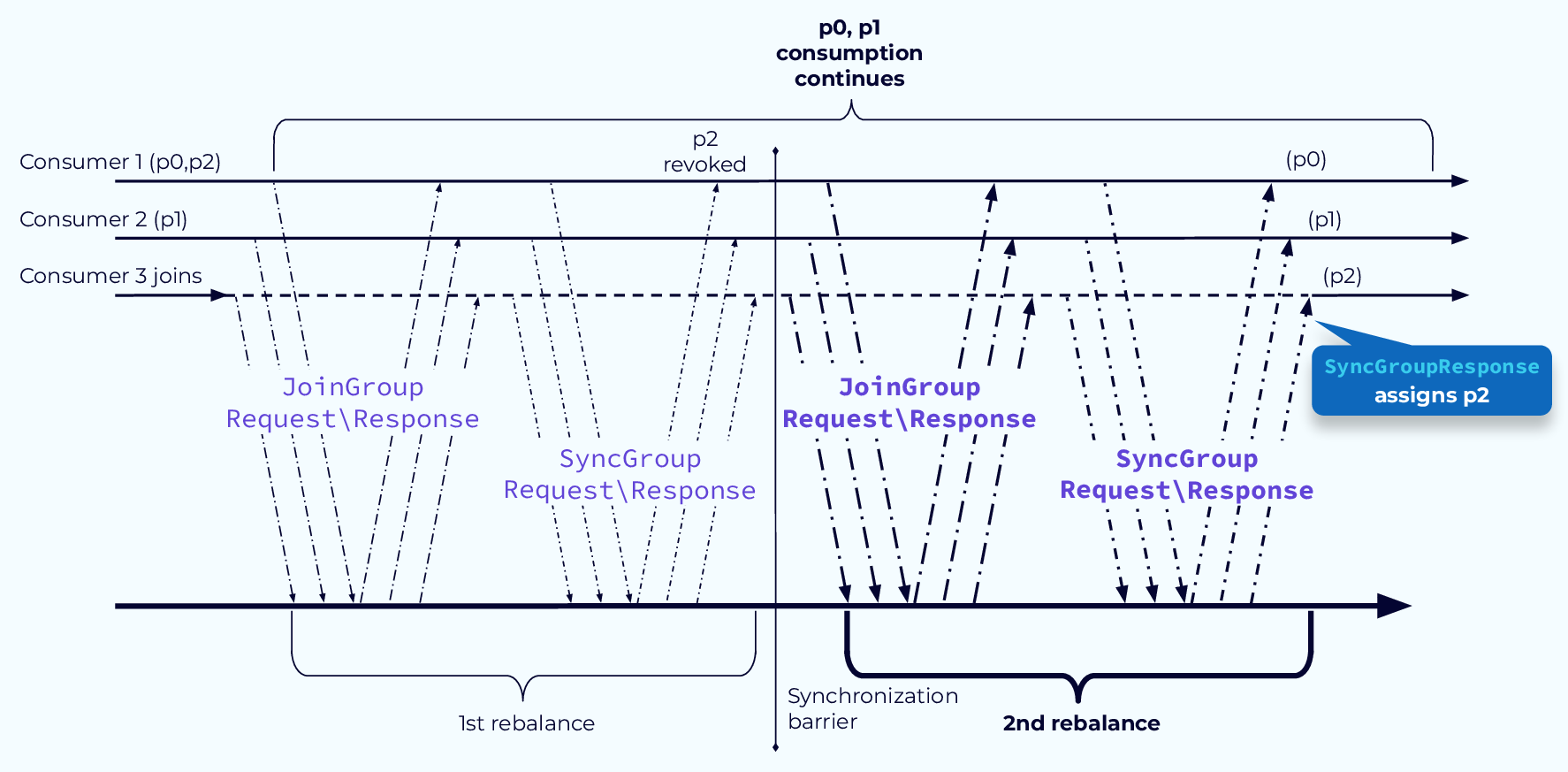
In the second rebalance step, the revoked partitions will be assigned. In our example, partition 2 was the only one revoked and it is assigned to the new consumer 3. In a more involved system, all of the consumers might have new partition assignments, but the fact remains that any partitions that did not need to move can continue to be processed without the world grinding to a halt.
Avoid Rebalance with Static Group Membership
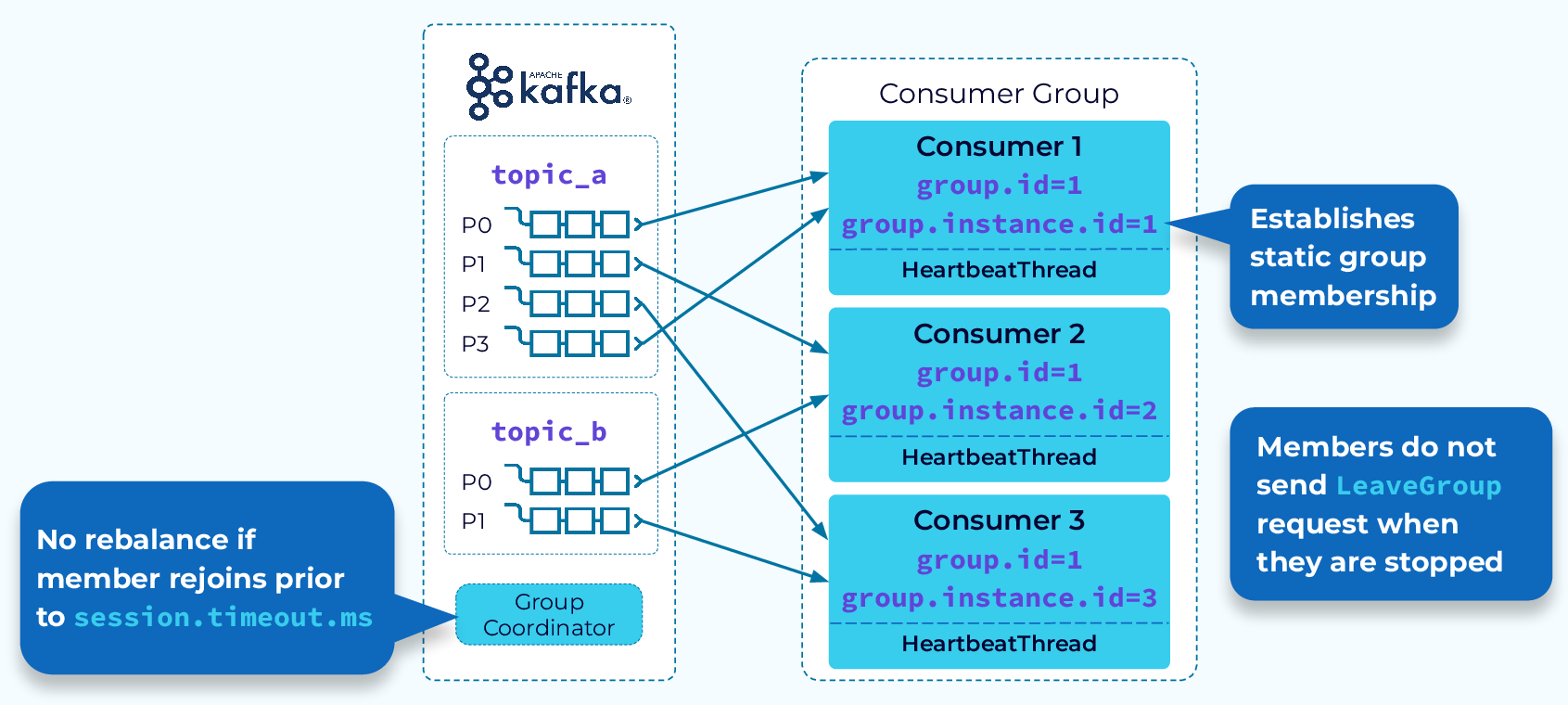
As the saying goes, the fastest rebalance is the one that doesn’t happen. That’s the goal of static group membership. With static group membership each consumer instance is assigned a group.instance.id. Also, when a consumer instance leaves gracefully it will not send a LeaveGroup request to the coordinator, so no rebalance is started. When the same instance rejoins the group, the coordinator will recognize it and allow it to continue with its existing partition assignments. Again, no rebalance needed.
Likewise, if a consumer instance fails but is restarted before its heartbeat interval has timed out, it will be able to continue with its existing assignments.
Use the promo code INTERNALS101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Consumer Group Protocol
Welcome back, everyone. Jun Rao from Confluent here. In this module, we're going to talk about how consumer groups work in Kafka. In Kafka, we separated the way we store data from the processing of data. And then the processing is typically done in the consumer applications. And consumer groups are a great way to scale out those consumer instances. Kafka Consumer Group Once you define a consumer group, the load of the data you are subscribing to can be divided evenly among those consumers and then they can be processing those records or events in parallel. The unit of distributing a load is a partition. So for a given partition here you are subscribing to, we are only going to give that to one of the instances of the consumer in this consumer group. Defining a consumer group is pretty simple. You just need to define a consumer group and then you make a subscription to the set of topics that you want to consume. Once you start the consumer group, the load will be evenly divided among those instances of the members in the group. And then if a new member joins or an existing member leaves, the load can be rebalanced among the remaining members. The workhorse behind a consumer group is a concept called group coordinator. Group coordinator is responsible for coordinating the combination among all the members in the consumer group and is also responsible for coordinating assignment of the workload to those members. In a typical Kafka cluster, there will be a multiple of these group coordinators. And this allows the load from different consumer groups to be evenly distributed among those different coordinators. Now let's look at how a consumer group is started. Find Group Coordinator So in this case, we have a consumer group. Let's say we have two members in this consumer group and they are starting at the same time in parallel. The first thing each of these consumer instances needs to do is to identify the group coordinator for this group. So on the broker side, we use an internal topic called consumer_offsets to store all the metadata about this particular group. And then it typically has multiple partitions. And then the group coordinator for this consumer group is determined by the leader of the partition this consumer group will be hashed into. Later on, you will see this concept of an internal topic will be used multiple times to manage various other things. So once the broker identifies the group coordinator for this consumer group, it will send its endpoint including the host and port back in the response. The next thing Members Join that the consumer instance will need to do is to send a joint group request to this group coordinator. In the joint group request, it'll include the subscription it has. One of the tricky things we have to deal with is we want assignment of the load to those consumer members to be pluggable. To be determined by the consumer instances in separate brokers. Because we want to provide more flexibility to the application. Because of that, the group coordinator actually doesn't know how to assign the load. So instead, what it does is to pick one of the group members, typically the first member who joined the group as the group leader. And it will allow the group leader to make the decision of assigned work among those members. So what it'll do is it will include all of the member information, including member ID and the subscription back to this group coordinator. For the rest of the non-group leader consumer instances, it'll just send its member ID. Once the group leader has received the complete member list Partitions Assigned and its subscription, it will use it pluggable assignor to assign the topic partitions among those member instances. And then we will be sending the response in the results in the separate request called a SyncGroupRequest to the group coordinator. Every other member will also be sending a similar request including its memberId. And the group coordinator will take the data it received from the group leader and will send the assignment for each of the members back to each of the consumer instances. Now let's look at some of the assignment strategies. One assignment strategy is called a range partition. Range Partition Assignment Strategy In this case, how it works is it will distribute a partition at each individual topic level. So it will look at the first topic and divide up its partitions among consumer members and it will go through the next topic and then do the same thing. As you can see in this case, the partition 0 from both topics will be assigned to consumer 1. And similarly, partition 1 from both topics will be assigned to consumer 2. But the rest of the consumers will be idle because there's no work for them. Now for the range partition, there's a particularly important use case for that. It's pretty important for doing colocating, colocating the joins. For example, you may have these topics with shared keys. So all records with the same key will be assigned to the same partition by having the same partition assigned to the consumer, they can easily do joining across these two topics locally. Another commonly used partition assignment strategy is called round robin. In this case, we just tear down topic boundaries. We just line up all of the topic partitions no matter which topic they're coming from. And then we'll just assign them uniformly across those consumer instances. The benefit is that this actually allows more degrees of parallelism because all of the partitions across all the topics can be used but you just don't get colocation. Another variant of round robin is the sticky partitioner. Round Robin and Sticky Partition So this improves round robin a little bit by trying to do its best effort of sticking to the previous assignment during the next reassignment. So it tries to reduce the number of partitions that need to be moved around across those consumer instances. In Kafka, we also provide a way for the consumer Tracking Partition Consumption to keep track of where they have consumed. In Kafka keeping track of consumers is very easy. Because a given partition is always given to a single consumer and all the records within a partition are always given to the consumer in offset order. So the consumer really needs to track the last offset it has consumed for each of the partitions. In order to keep track of the position, the consumer can issue a CommitOffsetRequest to the group coordinator. The coordinator will then persist that information in the underlying internal topic. If the consumer group instance is restarted, Determining Starting Offset to consume the first thing it can do is to make a request to the coordinator to retrieve its last committed offset. And once it has the offset, it can resume the consumption from that particular offset. If this consumer instance is started for the very first time and there's no saved position for this consumer group, then you can either start consuming from the very beginning of this topic partition or from the very latest offset. Group Coordinator Failover The group coordinator of course, can fail. But because the internal offset commit topic is replicated, the group coordinator, if it fails can easily fail over as the new leader for this internal topic partition. So we can handle failure in a pretty resilient way as well. Sometimes, a rebalance will be needed Consumer Group Rebalance Triggers among the consumer instances within the same group. This can happen because one of the instances fails to heartbeat with the group coordinator which indicates this consumer instance has failed. Or a new consumer instance has joined the group or maybe a new partition has been added to the subscribed topic, and if you are using a wild card subscription some of the new topics being created couldn't match the subscriptions that you are making. So all those can trigger a rebalance so that the consumers can be rebalanced. Now let's look at the rebalance process. Consumer Group Rebalance Notification Once the group coordinator notices that rebalance is needed, the first thing it will do is to send a response, piggybacking on the heartbeat to indicate to each of the consumer instances that a rebalance is needed. Once a consumer receives this rebalance notification, Stop-the-world Rebalance it will go through a rebalancing process. Some people may be familiar with this stop-the-world rebalance process. This is actually an issue we used to have and I will explain what some of the issues are in our old rebalance protocol. And what some of the improvements are we have made since. Let's say in this example, initially, we have only two consumers and a new consumer, which is consumer three, joins, which triggers a rebalance among all the three consumers. So the first thing the existing two consumers have to do is to revoke the assigned partitions they have. And sometimes, the consumers may have maintained some internal states for each of the assigned partitions. In that case, it will also clear up the state associated with those assigned partitions. Then all the consumer instances will go through the process of sending a join request and then a sync request to the group coordinator. In the end, the new partition assignment will be received by each of the consumer instances. Then the consumer instances, if they have state, will need to rebuild their state corresponding to the newly assigned partitions. Now, what are some of the issues with this whole process? Well, there are a couple of issues. The first issue is the need to rebuild some of the states. Stop-the-world Problem 2 As I mentioned, I think in the earlier slide, that you want to rebalance the consumer instance first, revoke partitions and then clear up the state. And only rebuild some of those when the new partitions are assigned. And in this case, you can see partition 0 and partition 1 they actually are assigned back to the same consumer instance. So rebuilding their state is actually wasteful. And sometimes, if you have large state, this can take some time. So this is the first problem: unnecessary rebuilding some state for the consumer applications. The second issue is what we call paused processing. As you can see, since each of the consumers revokes those partitions immediately, the processing of all of the records for all of the partitions has stopped. And it only resumes when the new partitions have been assigned, which can take a little bit of time. At least in this particular case, you can see the pausing for all the processing of records in partition 0 and partition 1 is unnecessary because they are actually assigned back to the same consumer instance. In theory, they could have just continued processing during this rebalance process. Now let's look at some of the improvements we have made to address these two issues. The first thing is we are using an improved version of the sticky partition assignor to address the first issue where the states need to be rebuilt unnecessarily. So the improvement is, in this case, during the rebalance, initially, we won't be cleaning up the state during the beginning of the rebalance. Instead, we try to rebuild state only when the new partition assignment has been reached. So in this case, since partition 0 and partition 1 are assigned back to the same instance, they actually don't need to have their states rebuilt. Because we know that they are the same as the previous assignments. Avoid Processing Pause with CooperativestickyAssignor Another improvement we made is through what we call the cooperative sticky partition assignor. This is used to solve the second issue which is the soft processing issue. So what this will do is at the beginning of the rebalance, each of the consumers will not immediately revoke the previously assigned partitions. Instead, they would just include those previous assigned partitions as part of the JoinGroup to the coordinator. During the rebalance, the group leader will try to only send back the revoked partition for each of the consumer instances. In this case, only partition two will be revoked from consumer 1. And for partition 0 and partition 1's data, they can continue to be processed by consumer 1 and consumer 2 because they're never revoked. So the processing for those records doesn't stop at this point. And in the second round of rebalancing, what it will do is the group coordinator where now, hasn't given a chance to the consumer instance to revoke some of the unneeded partitions, it will then assign the revoked partition back to the new instance. In this case, it will reassign the previously revoked partition 2 to the new consumer. As you can see in the whole process, the processing for partition 0 and partition 1 never stopped. It's actually a big improvement from the previous case. Avoid Rebalance with Static Group Membership The last thing we can consider to improve this is to avoid rebalance completely. Because in some of the common cases, the reason we need to rebalance is a consumer instance is restarted. Because they maybe want to restart a consumer instance for upgrading, or for picking up some new configuration. In this case, you know the consumer instance will come back pretty quickly. So you can actually choose not to move the partitions around in this phase. And then just wait for this new consumer to come back. To achieve this, what we are introducing is a new capability called static group membership. In this model, you'll be assigning a static member ID for each of the consumer instances in the group. Then the group leader will deterministically assign the partitions to the consumer instances with the same group member ID. And in this case, if you stop the consumer and then restart it, when you stop the consumer, the consumer instance won't be sending the leave group request to the group coordinator. So there's no rebalances triggered. Instead, the group coordinator just waits for this consumer instance to come back. As long as it can come back before the session timeout, then the group coordinator just thinks this consumer instance has never gone away, and it will give back the same partition assignment to this consumer instance. This actually is much more convenient because the consumer never needs to participate in a rebalance and then do things like rebuilding state. So that's the end of this module. Thanks for listening.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.