Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Tiered Storage



Jun Rao
Co-Founder, Confluent (Presenter)
Current Kafka Storage
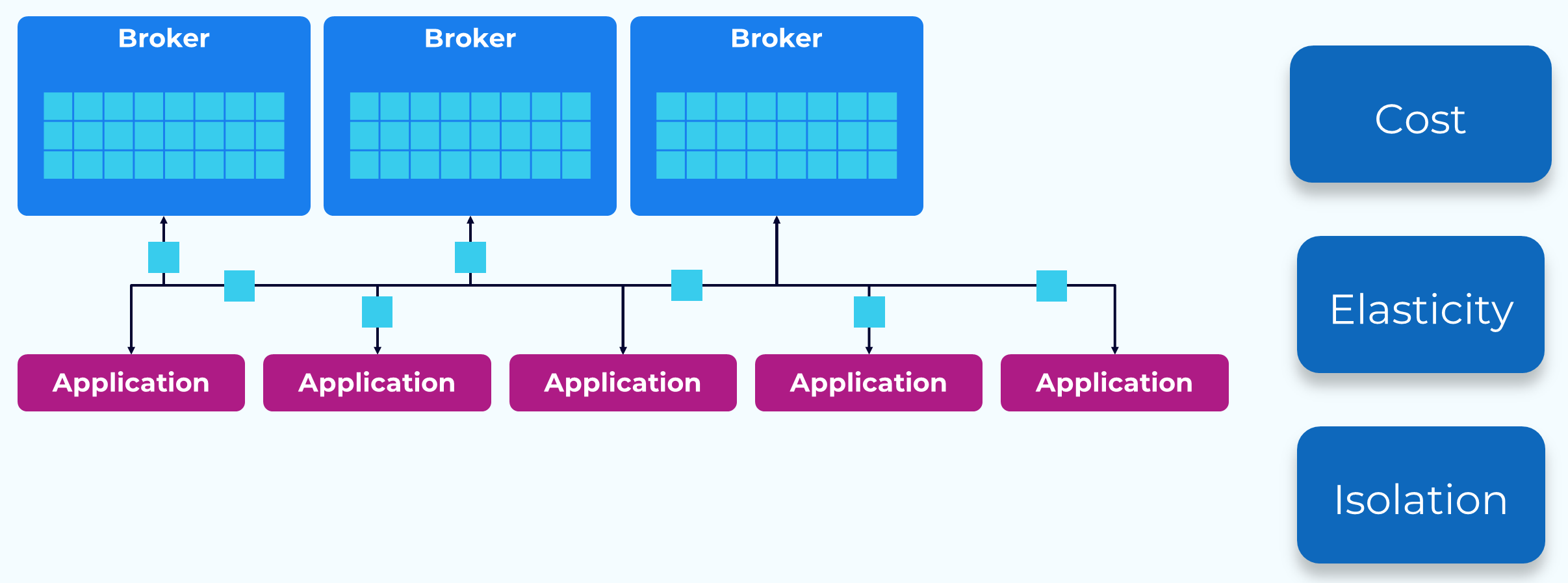
Before we dig into the wonders of Tiered Storage, let’s take a look at Kafka’s traditional storage model and some of its drawbacks.
Storage Cost – Kafka is intended to be fast and to help make it faster we usually use expensive but fast storage. This is great for the recent data that we are normally working with in a real-time streaming environment. But if we also want to retain historical data for later use, we end up using a lot more of this expensive storage than we need to satisfy our real-time streaming needs.
Elasticity – Local storage is tightly coupled with the brokers, which makes it difficult to scale compute and storage independently. If we need more storage we often end up adding brokers even though we don’t need more compute.
Isolation – Most real-time data is read shortly after it is written and is still in the page cache, but when we need to read older data, it must be fetched from disk. This takes longer and will block other clients on that network thread.
Tiered Storage – Cost-Efficiency
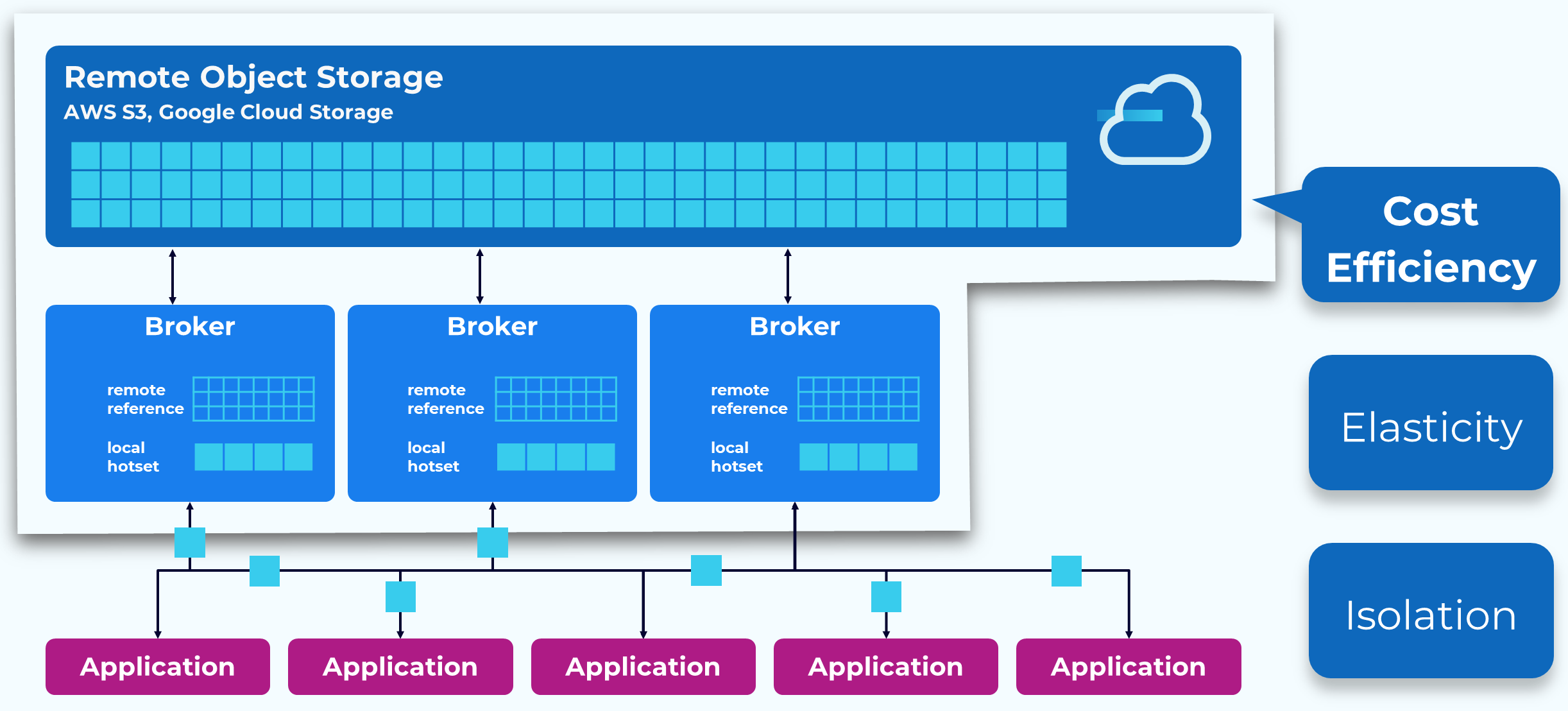
With Tiered Storage we only store recent data, up to a configurable point, in local storage. Older data that we still want retained, is moved to a much less expensive object store, such as S3 or Google Cloud Storage. This can represent a significant cost reduction.
Tiered Storage – True Elasticity
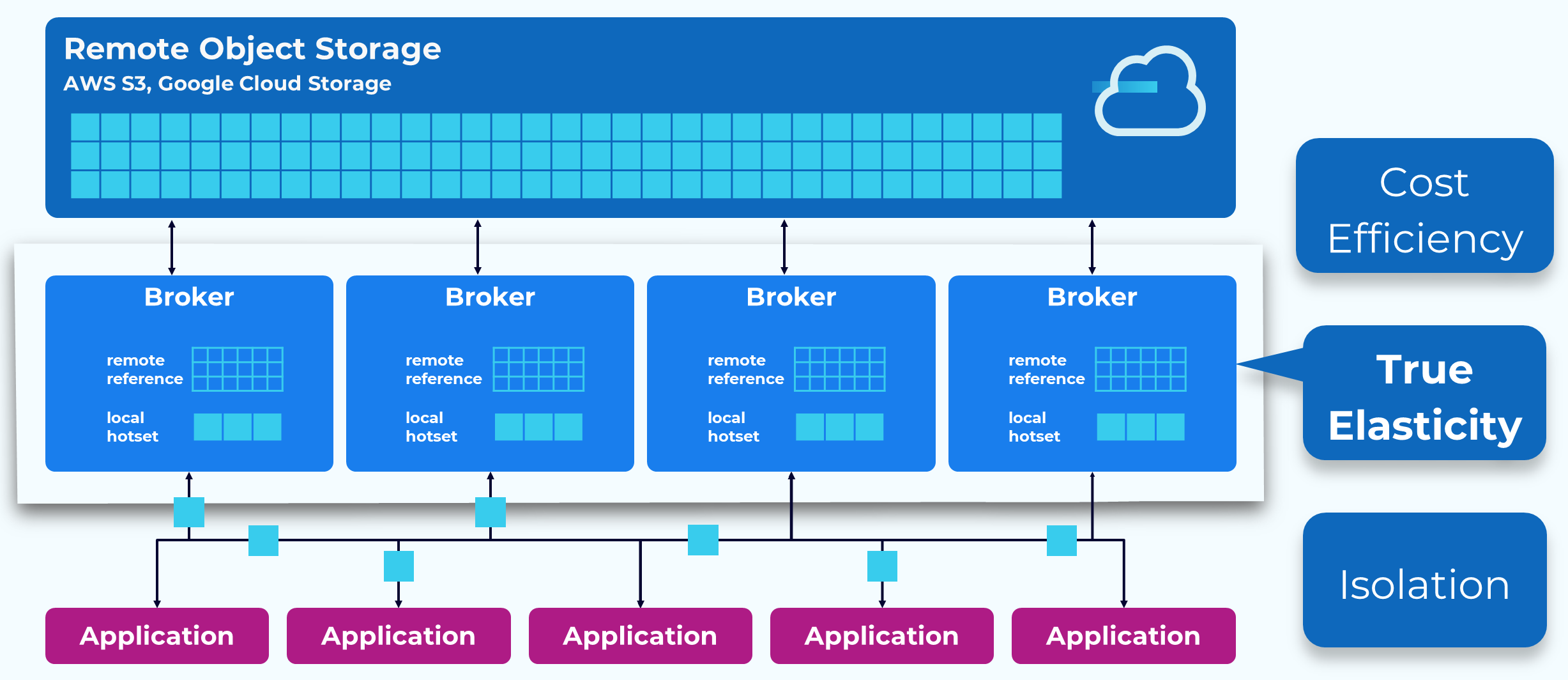
By decoupling the majority of the data storage from the brokers we gain significant elasticity. Now we should never be forced to add brokers because we need more storage, and when we do need to add brokers to increase compute, we will have a small subset of the amount of data to redistribute. Also, Kafka has always had infinite storage, in theory, but with Tiered Storage it’s also quite practical.
Tiered Storage – Complete Isolation
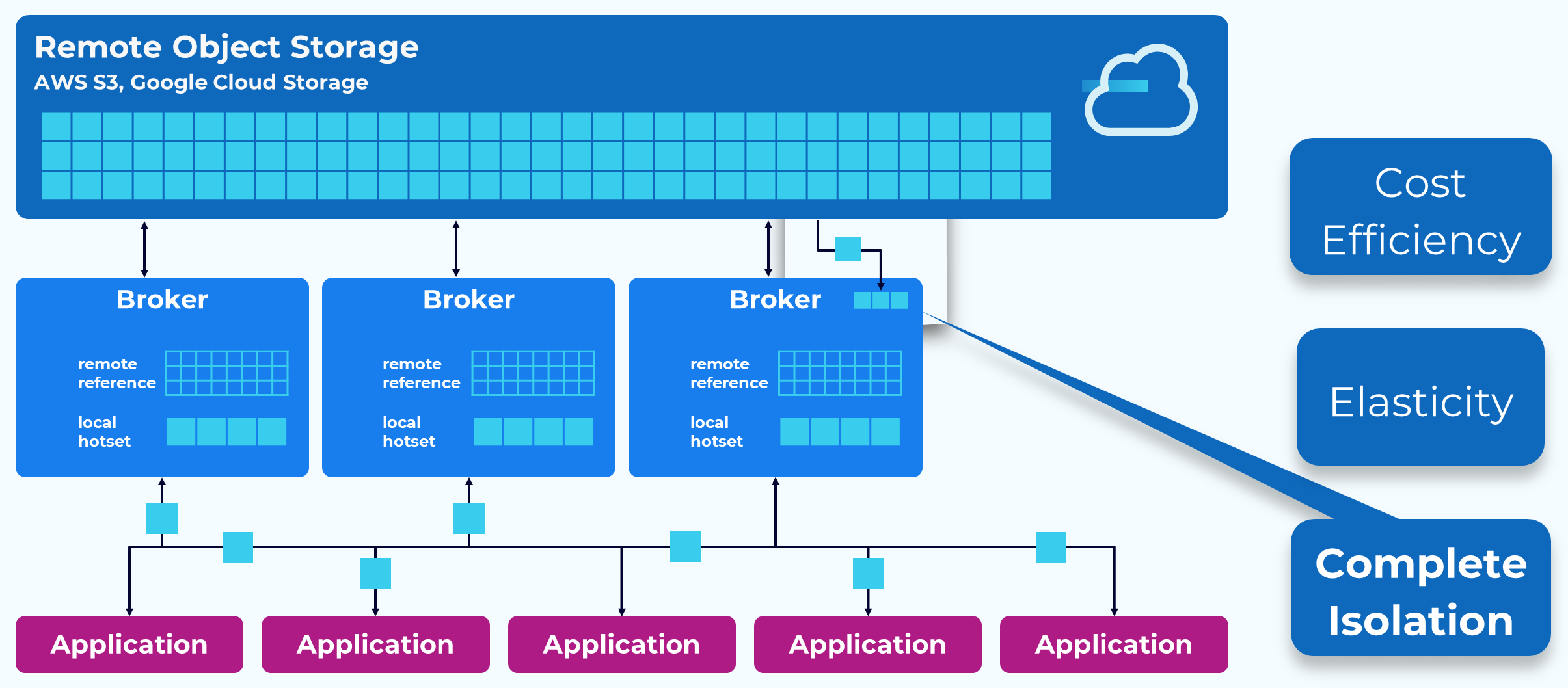
Any historical data stored in the remote object store is accessed through a different path so it does not interfere with the retrieval of the recent data. When data is needed from the object store, it is streamed asynchronously into an in-memory buffer. Then the network thread just has to take it from memory and send it to the client, thus removing the need for blocking.
Writing Events to a Tiered Topic
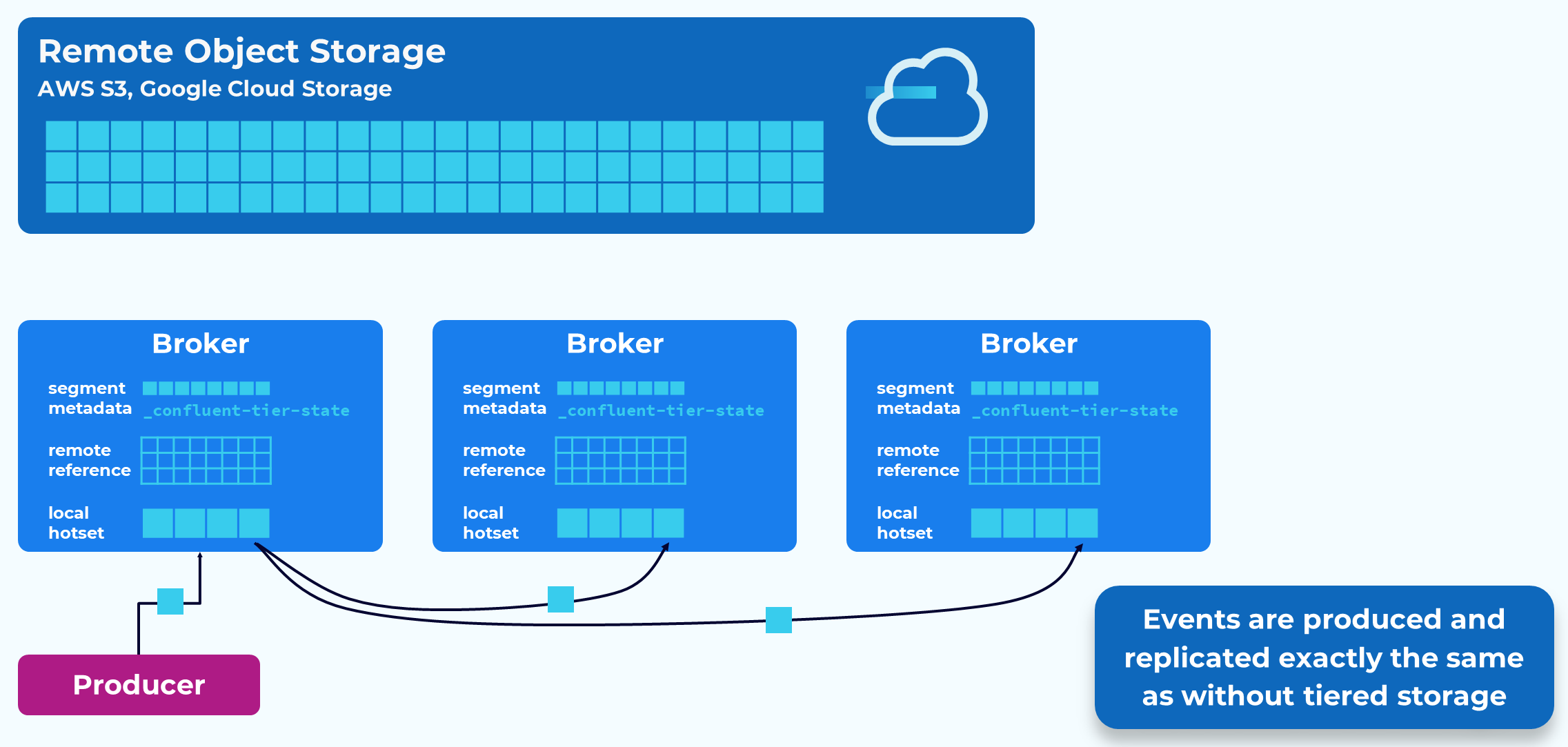
Producing events to a topic that is using Tiered Storage is exactly the same as usual. Events are written to the leader replica and the follower replicas will fetch the events to keep in sync. In fact, producers are not even aware that they are producing to a tiered topic.
Tiering Events to the Remote Object Store
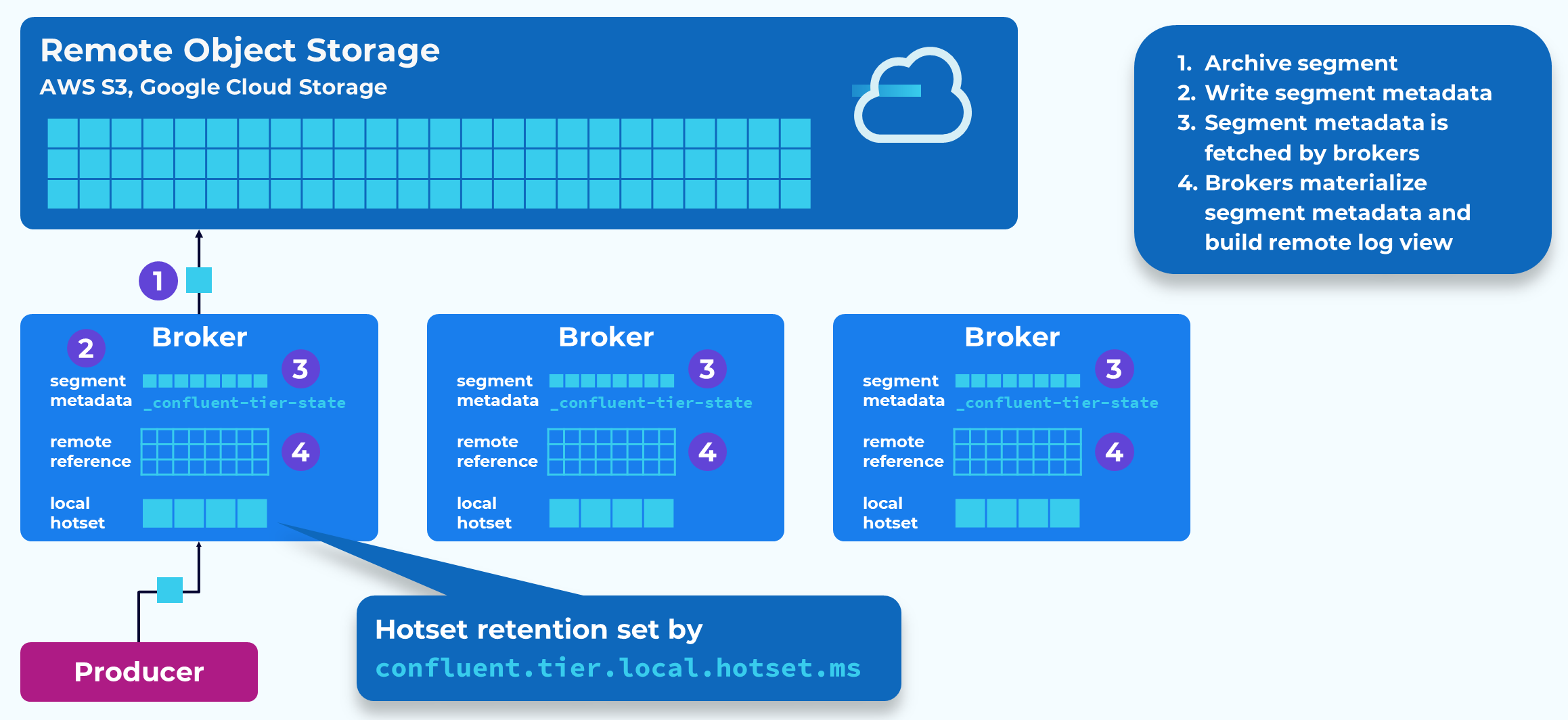
Earlier we learned about how topic partition data is stored on disk in segment files. These files are the unit of transfer with Tiered Storage. The active segment is never tiered, but once a segment has rolled and been flushed to disk, it is available for tiering.
The partition replica leader is responsible for moving the segments to the remote store. As it writes that segment data it will record references to the data’s new location in an internal topic called _confluent-tier-state. Followers will fetch and replicate that metadata.
The tiered segments will remain on disk until reaching the threshold configured by confluent.tier.local.hotset.ms. After this point they will be removed from local storage.
They will remain in the remote object store until either the segment.ms or segment.bytes threshold is reached.
Logical View of Tiered Partition

Brokers create a logical view of the partition using the metadata stored in the _confluent-tier-state topic along with the current state of the partition in local storage.
When a consumer fetch request is received, the broker will use this logical view to determine from where to retrieve the data. If it’s available in local storage, then it is probably still in the page cache and it will retrieve it from there. If not, then it will asynchronously stream if from the remote store, as described above.
There may be some overlap so that some events are in both local and remote storage, but the broker will retrieve it from local storage first.
Fetching Tiered Data
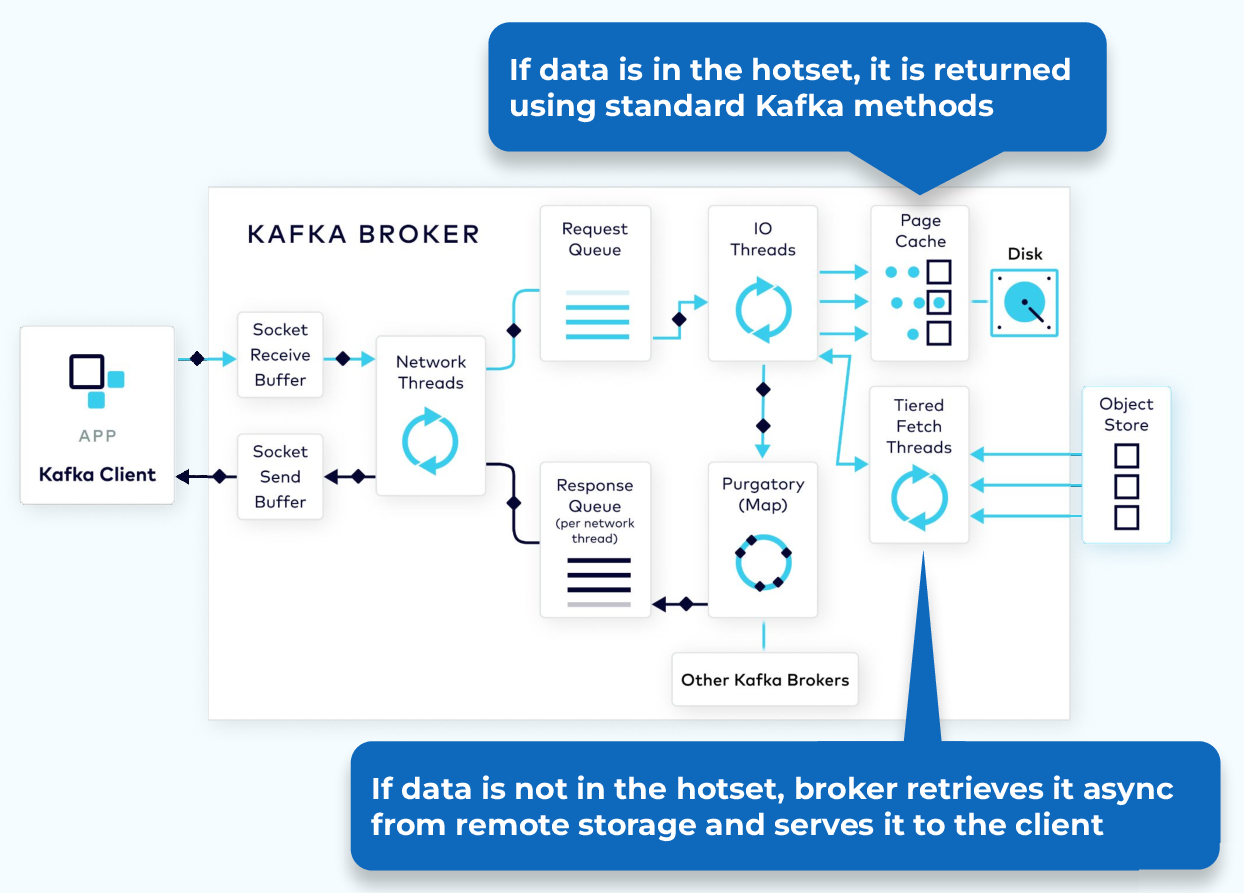
Let’s take a closer look at the fetch request when using Tiered Storage. For data in the hotset, the request process will be the same as if we were not using Tiered Storage. But if the data is not in the hotset, a separate thread will retrieve the data from the object store and stream it into an in-memory buffer. From there it will be returned to the client, all without impacting any other requests.
Once the tiered data is returned to the client it is discarded by the broker. It is not stored locally.
Tiered Storage Portability
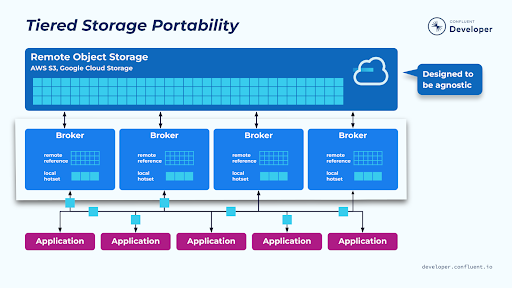
Tiered Storage is designed to be object store agnostic. Out of the box there is support for the major cloud object stores, but it is possible to use other cloud stores and even on-prem stores. Also, note that while Tiered Storage is currently only available with Confluent, work is being done to add it to Apache Kafka, as part of the KIP-405 efforts.
Use the promo code INTERNALS101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Tiered Storage
Hi, everyone, welcome back. Jun Rao from Confluent here. In this module, I'm going to go through the Tiered Storage within Kafka. This is actually a feature that's available in Confluent right now, but it's being developed in Apache Kafka as well. (upbeat music) Current Kafka Storage So, before I talk about Tiered Storage, let's first review the current Kafka storage and talk about some of its limitations. So this is how Kafka stores data now. Each broker has some local attached storage and all of the data in those topic partitions will be stored among those local storage in those brokers. Now, what are some of the issues with this? The first potential issue is in terms of cost. Kafka is really designed for real-time applications, so for the most recent data, it makes sense for them to use a fast type, potentially more expensive local storage. But for some of the historical data, it's a bit wasteful to use the same type of storage because that can add up costs. So, that's the first potential issue. The second issue is in terms of elasticity because we have coupled the storage with the broker computation. Now, if we want to scale out the storage and the computation, we can't scale them out independently. For example, if we need more storage capacity within the whole system, since the local storage capacity is limited, the only way we can do that is to add more brokers. That means those brokers are just adding some new computing resources that are unneeded. The last part is in terms of isolation. So earlier I mentioned that we use zero copy transfer to transfer the data in the local storage all the way to remote sockets. Now, if the local data is not in the page cache, this can be expensive because it needs to load the data into the socket, and that can take time that can block network threads, which means this can impact some real-time consumers that are assigned to the same network thread. So, the isolation is also a potential issue here. Now let's look at how Tiered Storage is designed and how it solves some of the issues. Tiered Storage So with tiered storage, we no longer have a single type of storage associated with the broker. Instead, the broker storage is tiered. For the most recent data, we can continue to keep it in the local fast storage, but for the historical data, we can potentially archive it into remote object stores, and there are quite a few from various vendors. And then we only need to keep the references of those remote objects in each of the brokers. Now, what's the benefit of this new architecture? First of all, in terms of cost, because we only keep the most recent data in the local store, we only need to pay the high-end, fast storage for a small portion of the more recent local data. For the vast majority of historical data, we can use potentially the cheaper object store, but they can still provide pretty good throughput for our usage. The second thing is benefit is in terms of elasticity. Now, since we have separated the storage from the compute of the brokers, we can now scale them out independently. For example, if we only need more storage, we don't need to add more brokers because the object store is potentially infinite, it can keep expanding with the storage space. If we do need some more computing resources by adding new brokers, this process can be done much more efficiently because we only need to physically copy just a small portion of the local set of data, the more recent data amount to the brokers. For the rest of the historical data, we only need to copy some references, which is much faster. Better Isolation Lastly, this also provides a good opportunity for us to provide better isolation because since now the historical data will be stored in a different remote object store, we can serve them in a completely different path from the local data, which will potentially provide much better isolation between the real-time consumers and the consumers that access historical data. Now, let's look at in a little bit more detail how Tiered Storage works. How Tiered Storage Works When you publish data to a Tiered Storage enabled topic, the producer doesn't change. You still write data to the leader and the data will be replicated to all of the followers. That stays the same as before. But over time, as new segments are being rolled what a broker will do is to start archiving those rolled segments into the remote object store. Once the segment is uploaded into the remote object store, the leader of that partition will also be writing the metadata of that remote object into an internal topic. And all the other replicas will be reading this remote metadata information from this internal topic, and then they will be using that to build their internal in-memory view of the remote references. Once the data has been successfully archived to the remote object store, the local data can be removed because we don't need that redundantly in the local log. And how long you want to keep the data in the local log can be configured by this retention time. And typically, maybe an hour, or maybe 10, 15 minutes is enough to keep the local data. From the remote references and the locally stored log segments, each broker has a holistic view of all the segments it has in its log. Some of them will be only in the remote store. Some of them will be only in the local storage. Some segments could be in both places, but the broker will have the exact view, so when the consumer wants to fetch a particular offset, it knows from which part to give the data back to the consumer application. Now let's take a look, a closer look, at how the fetch request is served with Tiered Storage enabled. When the consumer issues a fetch request with a particular offset, if that offset falls into the local storage, the data will be served in the same way as before. And in this case, since we can configure a roughly small local retention storage, the chances are that all the local data will still be in the page cache. If the data is only in the remote store, what the broker will do is, it will first stream the remote objects data from the object store all the way into an in-memory buffer within the broker. And from there, it will stream the in-memory data back to the remote socket in the network thread. This way, the network thread is no longer blocked, even when the consumer is accessing some historical data. This actually makes it very convenient to mix applications that access both real-time and historical data in the same Kafka cluster, because they won't be impacting each other. Portability Tiered Storage is also designed to be portable. It supports the object store in all of the major public clouds, but it also supports some of the object stores even for some of the on-premise use cases. So, it provides the ability for you to leverage the feature, whether you're in a public cloud, or in the private cloud. And that's it for this session, and thanks for listening.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.