Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Transactions



Jun Rao
Co-Founder, Confluent (Presenter)
Why Are Transactions Needed?
Earlier we learned about Kafka’s strong storage and ordering guarantees on the server side. But when multiple events are involved in a larger process and a client fails in the middle of that process, we can still end up in an inconsistent state. In this module we’ll take a look at how Kafka transactions provide the exactly-once semantics (EOS) which form the basis for the transactional functionality that will solve this problem.
Databases solve this potential problem with transactions. Multiple statements can be executed against the database, and if they are in a transaction, they will either all succeed or all be rolled back.
Event streaming systems have similar transactional requirements. If a client application writes to multiple topics, or if multiple events are related, we may want them to all be written successfully or none.
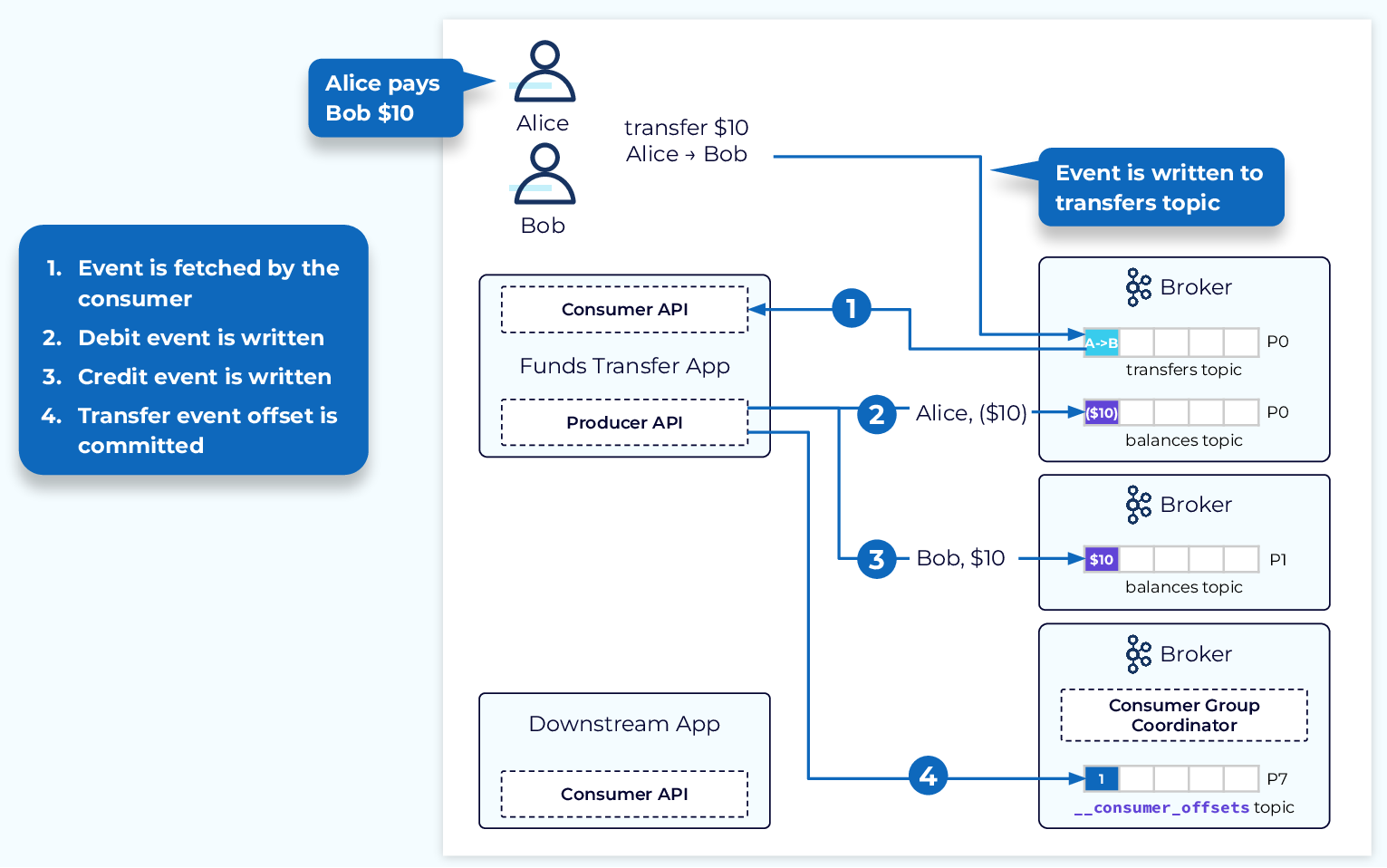
An example of this might be processing a funds transfer from one account to another and maintaining the current account balances in a stream processor. Offsets will be committed back to Kafka for the topic partitions that feed the topology, there will be state in a state store to represent the current balances, and the updated account balances will be output as events into another Kafka topic. For accurate processing, all of these must succeed together, or not at all.
Kafka Transactions Deliver Exactly Once
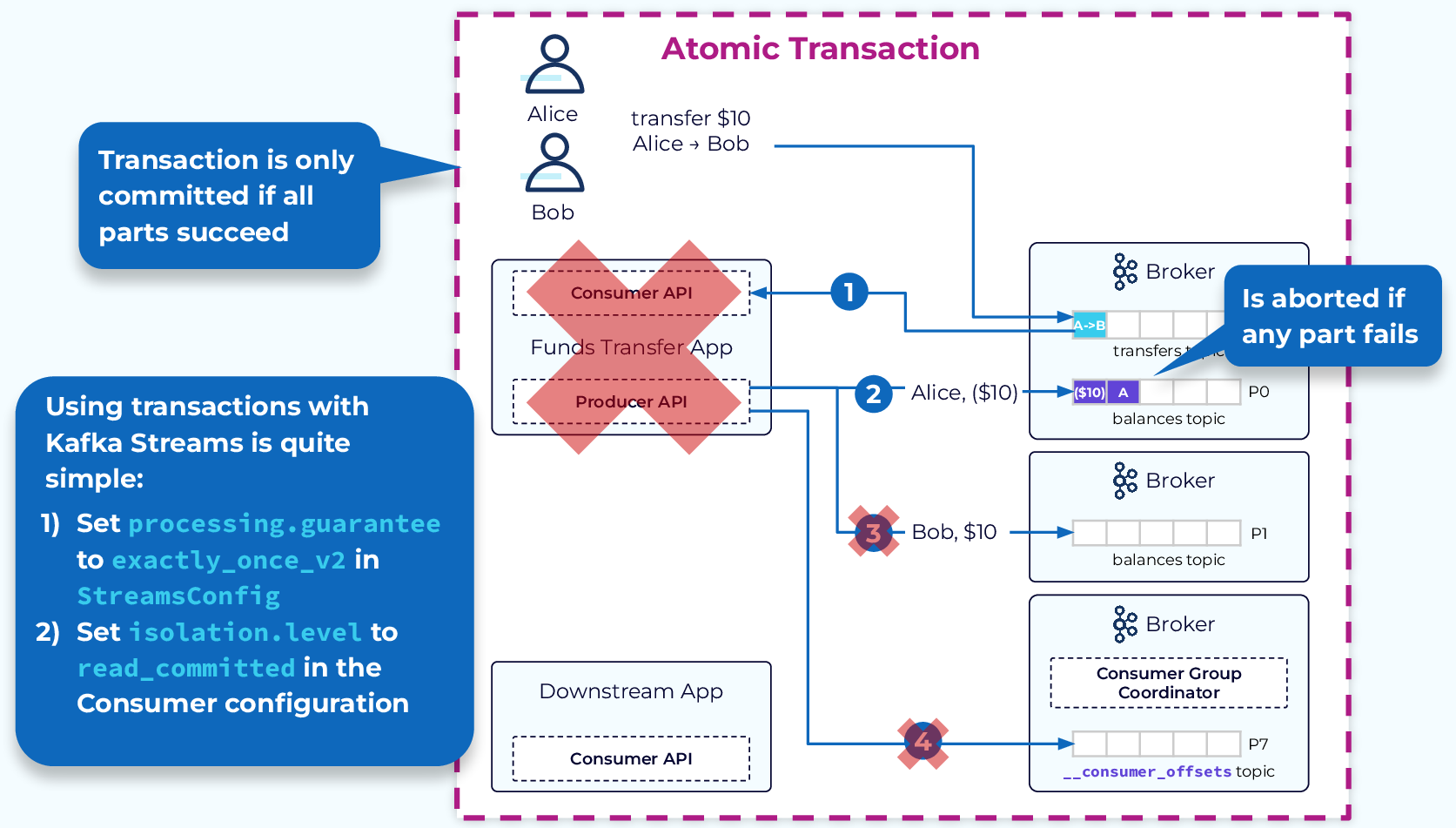
With transactions we can treat the entire consume-transform-produce process topology as a single atomic transaction, which is only committed if all the steps in the topology succeed. If there is a failure at any point in the topology, the entire transaction is aborted. This will prevent duplicate records or more serious corruption of our data.
To take advantage of transactions in a Kafka Streams application, we just need to set processing.guarantee=exactly_once_v2 in StreamsConfig. Then to ensure any downstream consumers only see committed data, set isolation.level=read_committed in the consumer configuration.
System Failure Without Transactions
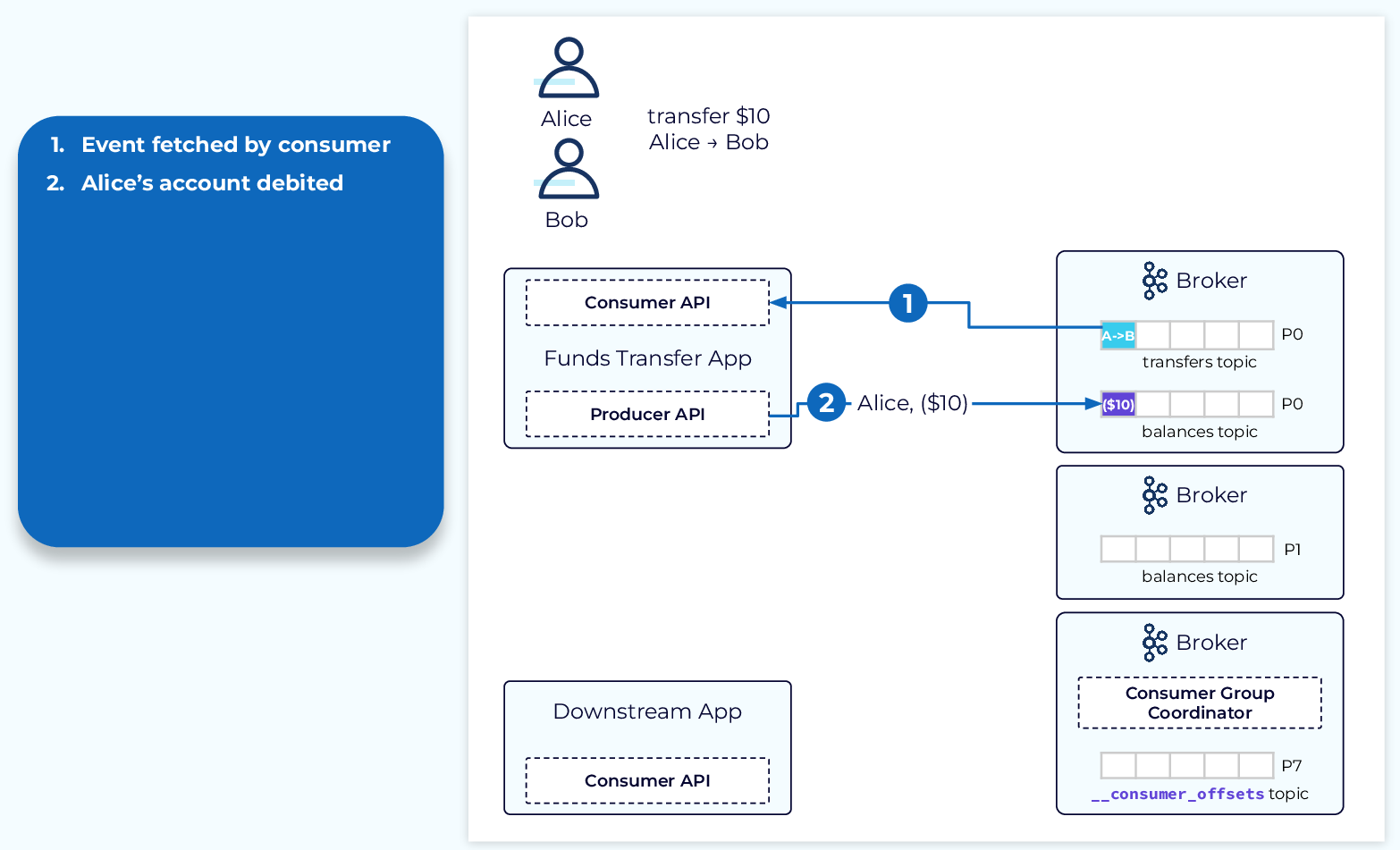
To better understand the purpose and value of transactions, let’s take a look at an example of how a system without transactions might handle a failure.
In our example, a funds transfer event lands in the transfers topic. This event is fetched by a consumer and leads to a producer producing a debit event to the balances topic for customer A (Alice).
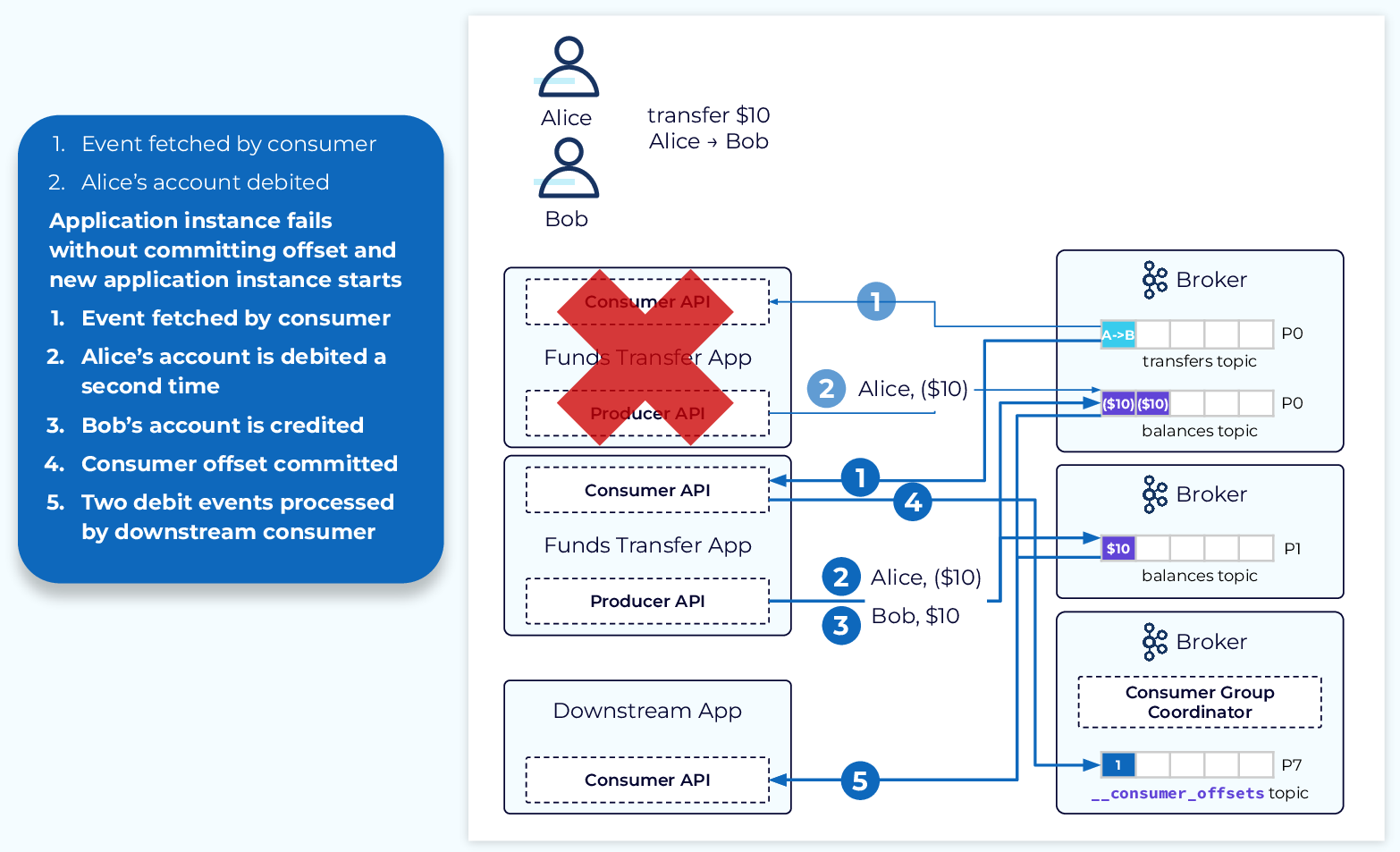
Now if the funds transfer application unexpectedly fails at this point, a new instance is started and takes up where it left off based on the last committed offset.
- Since the transfer event associated with Alice paying Bob was not committed prior to the failure of the initial application instance, the new application instance begins with this same event.
- This means that Alice’s account will be debited a second time for the same transfer event.
- Bob’s account is credited as expected.
- The transfer completes with the consumed event being committed.
- The downstream consumer will then process both debit events.
The end result is a duplicate debit event and an unhappy Alice.
System Failure with Transactions
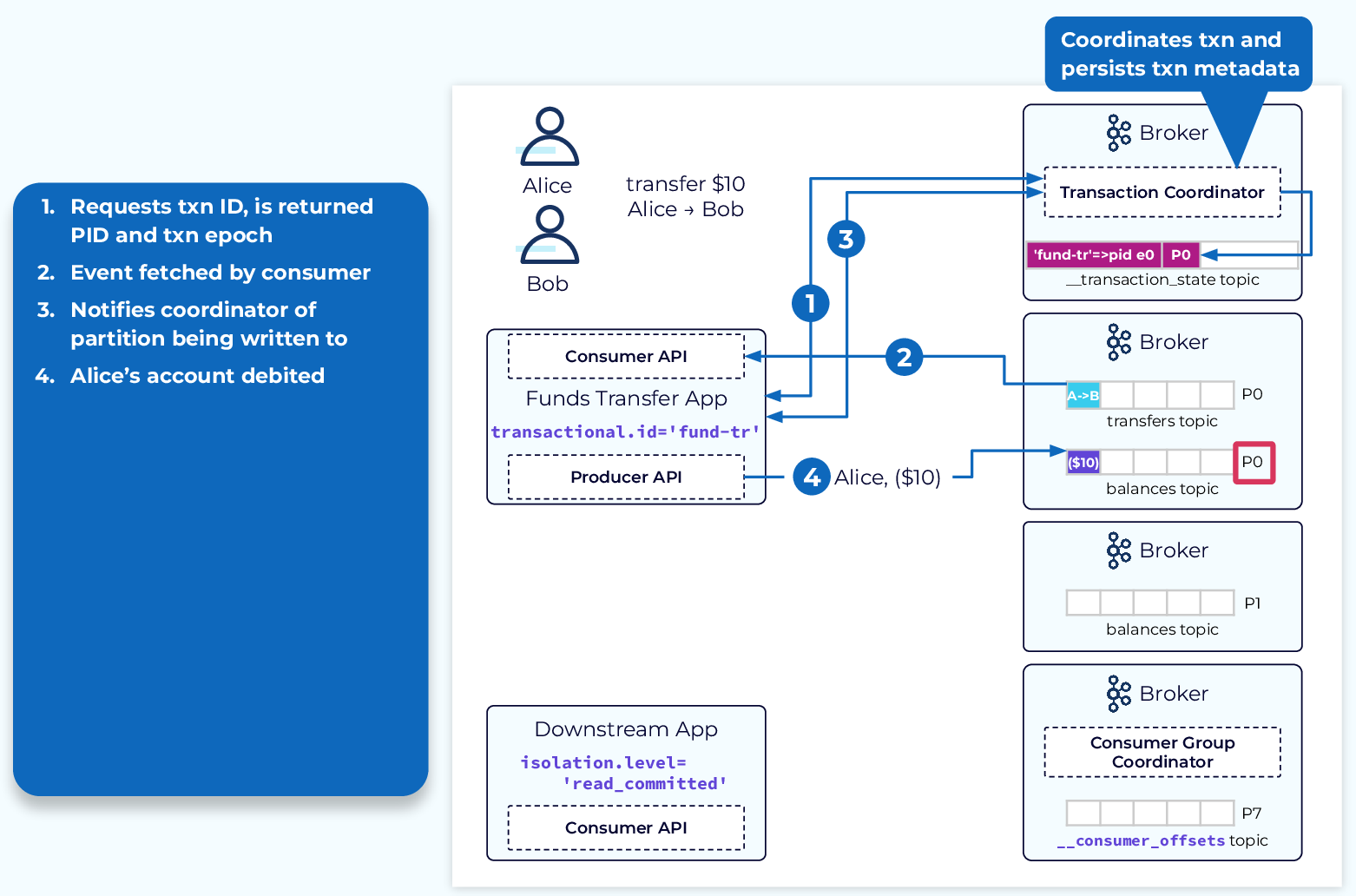
Now let’s see how this would be handled with transactions. First off, let’s discuss two new pieces of the puzzle, the transactional.id and the transaction coordinator. The transactional.id is set at the producer level and allows a transactional producer to be identified across application restarts. The transaction coordinator is a broker process that will keep track of the transaction metadata and oversee the whole transaction process.
The transaction coordinator is chosen in a similar fashion to the consumer group coordinator, but instead of a hash of the group.id, we take a hash of the transactional.id and use that to determine the partition of the __transaction_state topic. The broker that hosts the leader replica of that partition is the transaction coordinator.
With that in mind, there are a few more steps involved:
- First, the application sends an initialization request with its transactional.id to the coordinator that it maps to a PID and transaction epoch and returns them to the application.
- Next, the transfer event is fetched from the transfers topic and notifies the coordinator that a new transaction has been started.
- Before the producer writes the debit event to the balances topic, it notifies the coordinator of the topic and partition that it is about to write to. (We’ll see how this is used later.)
- The debit event of $10 for Alice is written to the balances topic.
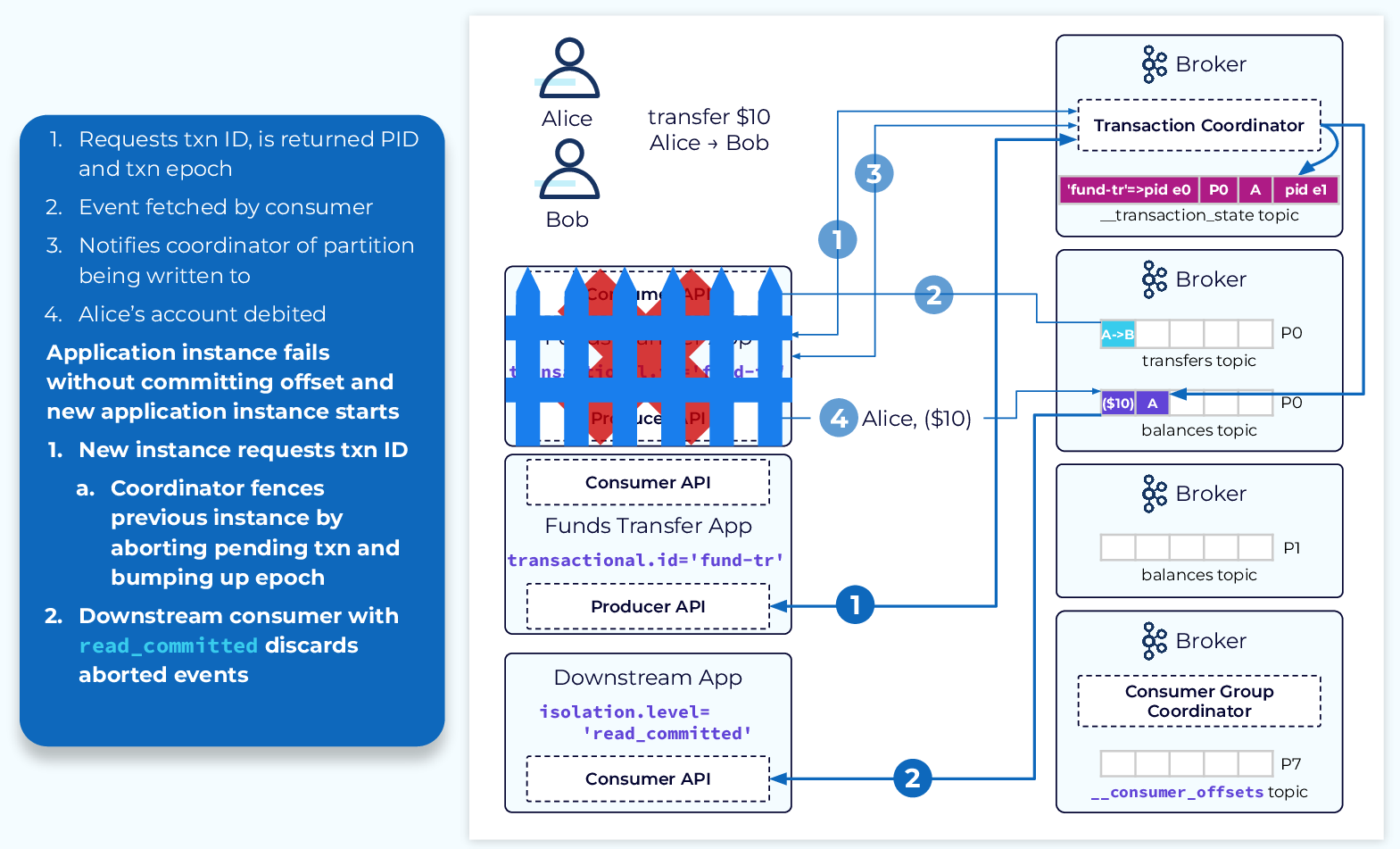
Now if the application fails and a new instance is started, the following steps will take place:
- The new instance will start in the same manner as the previous instance by sending an initialization request for a PID from the coordinator, but the coordinator will see that there is a pending transaction. In this case it will increase the transaction epoch and add abort markers to any partitions affected by the old transaction. This effectively fences off the failed instance, in case it is lurking out there and tries to continue processing later. The new instance will receive the PID and new epoch and continue normal processing.
- Downstream consumers that have their isolation.level set to read_committed will disregard any aborted events. This, effectively, eliminates the chance of duplicated or corrupted data flowing downstream.
System with Successful Committed Transaction
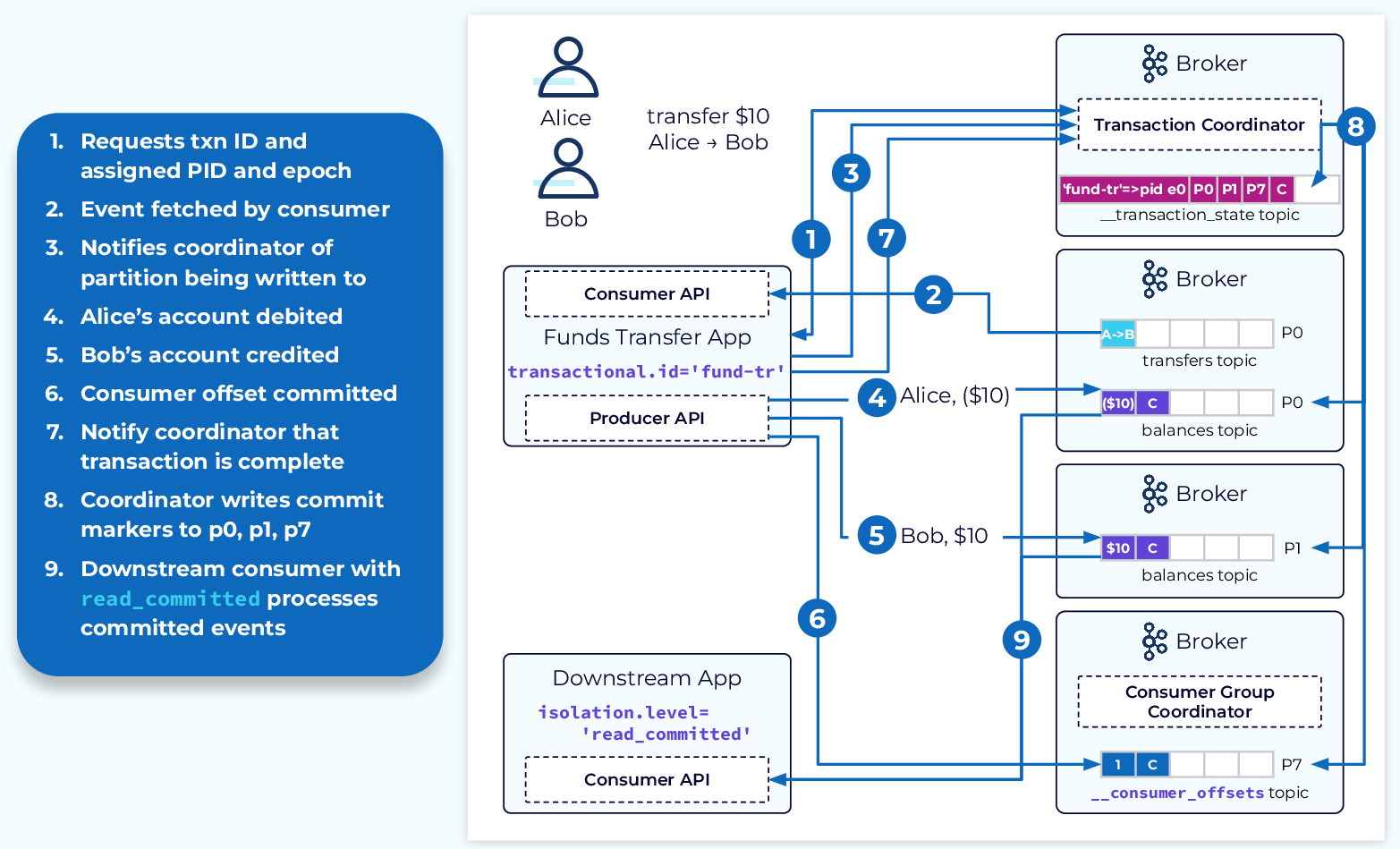
In a transaction where we successfully go through each of the steps described above, the transaction coordinator will add a commit marker to the internal __transaction_state topic and each of the topic partitions involved in the transaction, including the __consumer_offsets topic. This will inform downstream consumers, who are set to read_committed that this data is consumable. It’s truly a beautiful thing!
Consuming Transactions with read_committed
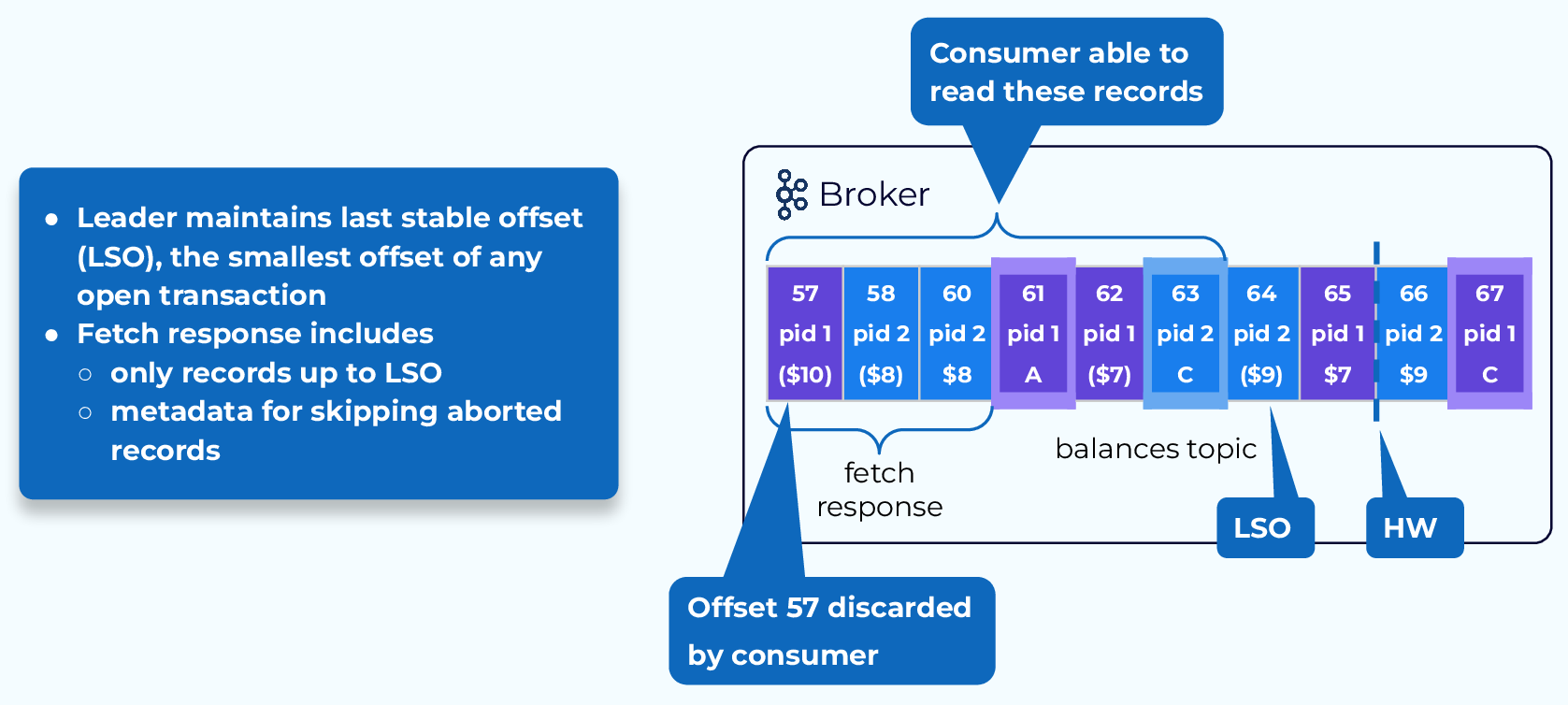
When a consumer with isolation.level set to read_committed fetches data from the broker, it will receive events in offset order as usual, but it will only receive those events with an offset lower than the last stable offset (LSO). The LSO represents the lowest offset of any open pending transactions. This means that only events from transactions that are either committed or aborted will be returned.
The fetch response will also include metadata to show the consumer which events have been aborted so that the consumer can discard them.
Transactions: Producer Idempotency
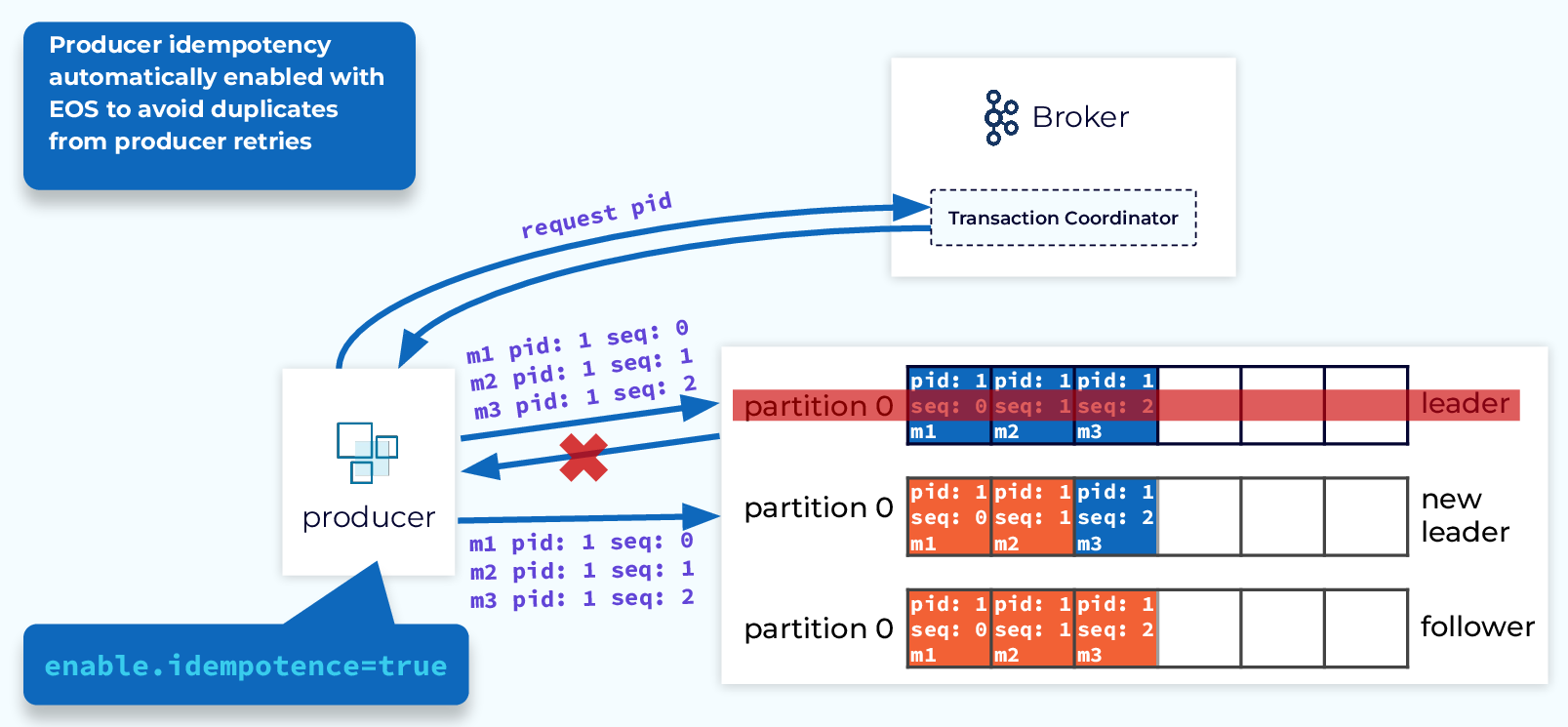
Producer idempotency, which we talked about earlier, is critical to the success of transactions, so when transactions are enabled, idempotence is also enabled automatically.
Transactions: Balance Overhead with Latency
One thing to consider, specifically in Kafka Streams applications, is how to set the commit.interval.ms configuration. This will determine how frequently to commit, and hence the size of our transactions. There is a bit of overhead for each transaction so many smaller transactions could cause performance issues. However, long-running transactions will delay the availability of output, resulting in increased latency. Different applications will have different needs, so this should be considered and adjusted accordingly.
Interacting with External Systems
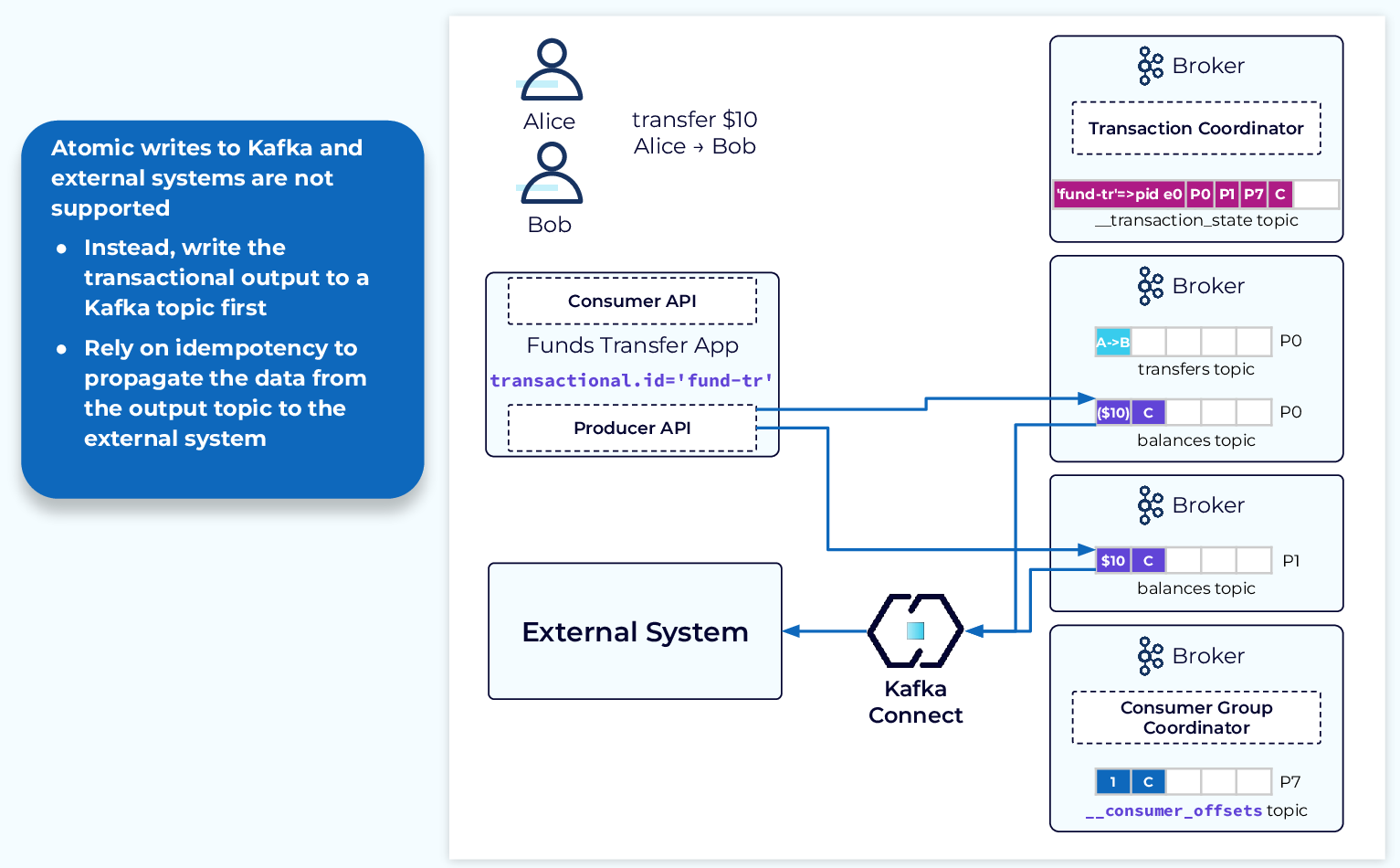
Kafka’s transaction support is only for data within Kafka. There is no support for transactions that include external systems. The recommended way to work with a transactional process that includes an external system is to write the output of the Kafka transaction to a topic and then rely on idempotence as you propagate that data to the external system.
Use the promo code INTERNALS101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Transactions
Hi, everyone. Welcome back to this session. This is Jun Rao, I'm from Confluent. In this module, I want to talk about transactions in Apache Kafka. Well, first of all, why do we need transactions? Why Are Transactions Needed? Well, people may be familiar with transactions in the database world. So typically, in the database world, if you want to write to multiple tables, having transactions gives you the ability to achieve this all or nothing behavior. So either have the writes to all tables succeed or have none of them succeed. Well, we probably need the same thing in Kafka land as well. So let's take a look at this example. For example, let's say you have this, you can see the application is called the transfer fund. So the input would be this transfer table which recorded the intention of transferring money from one person to another. In this case, Alice to Bob. What you want to do in this application is to take this event, which includes the transfer, and we will add two output records into the output topic. We're going to add a debit event for Alice and we want to add a credit event for Bob. That completes the transaction. Once this is done, we'll be committing the input offsets by either balancing the offset for the input topic and this will translate to a write into the internal consumer offset topic as we mentioned earlier. So for a lot of applications, it would be nice to have all those three writes. For the two output topics and then this internal topic to be done in the all or nothing way. So that will make the development of the application easier to understand. That's exactly what a Kafka transaction provides. Kafka Transactions Deliver Exactly Once It's a feature that allows this kind of application to do the processing and the write to the output topic once and only once even when the application can fail and can get restarted in the middle. Before I talk about the details of transactions enabling transactions is pretty easy in Kafka. Typically, the way you do it is to do enable it through a Kafka Streams application. So there's only one configuration you need to set in the Kafka Streams configuration which is processing guarantee to exactly once. And we have a version two now for some added performance improvement. Then if you produced some output in this transactional application, to read that output topic, you can set the isolation to be read committed. Then only the committed data will be exposed to this reader. System Failure Without Transactions Now let's first look at some of the issues without transactions. Let's still continue with that example where you read the input from the intention topic and then you try to add some of the credit events and the debit event to an output topic. Let's say you finished reading the input event and then you wrote a first debit event for Alice. Now let's say at exactly this point, the application fails. Now, what do you do in this case? Well, typically, when it fails, you just restart the application, and the application will resume from where it left off. Since previously, we didn't really finished processing the first event, so we didn't really commit an offset in the consumer offset topic. So when this application is restarted, it'll pick up this event again and it will try to do the same steps as you did before. Try to add a debit event for Alice and add a credit event for Bob. And eventually, it will commit the offset into this commit offset topic. Now, the application's steps are done. But notice that now, if you have applications reading this output topic, it will see the account for Alice is debited twice. This is actually annoying because it's very hard for applications to reason about this and deal with it. Now let's take a look of how this issue is solved with Kafka transactions. System Failure with Transactions If you have configured, let's say this is a streaming application with exactly one semantic, then the stream processing will automatically set an internal configuration called transaction ID to uniquely identify this particular application. When this application is started, the first thing it will do is to find a transaction coordinator to coordinate for this transaction. Now, how is the coordinator determined? It's actually determined the same way as it is for the consumer coordinator, if you remember that. So what's happening is there's a internal topic we use for storing all the transactional related information. It has multiple partitions and the leader of the partition, this transactional ID passes into is the transaction coordinator for this application. Once the coordinator is determined, then the coordinator can generate a unique produce ID for this transaction application and a corresponding epoch and will send this information back to the application. The next thing the application will do is to start reading from the input event. And then it's about to write the output. But before it writes that, it needs to inform the coordinator that it intends to update or write to an output topic. So it sends this information to the coordinator and the coordinator will persist the partition that will be part of this transaction into this internal topic. Once this is recorded, then the application can start writing the event to the output topic. Notice that at this point, even though we have written this debit event for Alice, the data hasn't been exposed to the consumer yet because it's still in this pending state. Let's say now that at exactly same point, the application fails and is restarted. So when the application is restarted, it will do exactly the same thing as it did before. The first thing is it will try to request a producer ID through the transaction coordinator. The coordinator will notice that, it actually already knows there is a pending transaction for the previous instance of this application. And then since this one is trying to register a producer ID again, it must be a new instance of this particular application. So what a transaction coordinator will do first, is to try to abort all of the pending transactions from the previous instance of this application. It does that by adding an abort marker to the internal transactional log. And it will also add an abort marker to each of the partitions this transaction has written data into. In this case, it's just this particular partition. Once this is done, the transaction coordinator will bump up the epoch for this producer ID. This will be used to fence off the old instance of this application. So in case this application didn't really die completely and mysteriously comes back, it cannot do any more writes for the new transaction because it will notice that its epoch is too old as compared with the latest epoch associated with this application. So after all this is done, if you see now that the consumer is trying to read this output topic, it actually will ignore this debit event because it's marked as aborted and it shouldn't be exposed to the application. At this point, we have avoided this issue of exposing aborted data to the application. System with Successful Committed Transaction Now let's look at what happens to a successful transaction. So you go through pretty much the same steps as before. When the application is started, it requests a producer ID from the transaction coordinator. Then it will read the input but before it writes to output topic, it will send to the coordinator, the set of partitions that it needs to add data into. In this case, there will be three partitions. These two partitions and the internal partition for the offset topic. The coordinator will record all those partitions in the transactional log. After that, the application can start writing the new records, those three output topics, including the offsets. Once this is done, the application can send a commit request to the transaction coordinator and the transaction coordinator will write the commit marker within its internal commit log, within its internal transaction log. At that point, that decision is made and can be changed. After that, it will be adding the same committed marker to each of the output topics based on the information it has recorded. At this point, all the committing information will be exposed to the consumer application if it is reading in this read committed mode. Consuming Transactions with read_committed So let's take a detailed look at how we expose transactional data for consumers with this read committed mode. In general, we still want to expose records in offset order, but notice that at this point, the high watermark is before offset 66. But the record whose offset is at 64 is actually not committed yet because there's no commit or abort marker for this particular transaction. So its state is pending. So in this case, we don't want to expose this data to the consumer yet. So what a broker does is to maintain a new position called last stable offset. This is the offset of all the first open pending transactions. All records whose offset is before this mark, their state has been determined. Which means they are either aborted or committed, and they can be exposed to the consumers and we can return those. Another thing that's a bit tricky is if we are returning, let's say the first three records in this picture back to the consumer, some records like the record at offset 57 are aborted and the consumer should ignore them. So what we do is when the broker sends these records back to the consumer, it also returns a little metadata so that the consumer application can ignore the aborted records like this. So since in general, abortion is relatively rare, there's actually very little overhead to the application. Transactions: Producer ldempotence Earlier, we talked about producers enabling idempotency to avoid issues of introducing duplicates or out of ordering when the application fails. So if your application is set with exactly one semantic, idempotency is automatically enabled. So in this case, let's say if you are sending some events to the leader, the first thing you will do is you will get your producer ID back. And then as you are sending the events, each of the records will be tagged with the corresponding producer ID and a sequence ID. And the broker will be storing those records with those producer IDs and sequence IDs and will remember what's the last sequence ID it has seen for a particular producer ID. Now, if the leader fails in the middle, then when the producer tries to send the same data to the new leader, the new leader will notice that some of the records are really duplicated and they can ignore those. So by enabling exactly once capability in a streaming application, we automatically enable idempotency. And together, they can guarantee this exactly once semantic for the processing of the data. Transactions: Balance Overhead with Latency Now let's talk about some of the considerations with transactions. One of the things about transaction is you have to decide how often you want to commit those transactions. There's some trade off there. Earlier, you have seen that there's a little bit of overhead to set up with the coordinator every time when you try to send the very first record to a particular partition. If you are committing only like one record per transaction, then that overhead could be significant. On the other hand, if you are including too many records within the transaction, that tends to delay the exposing of the data to the downstream applications. So you want to balance the two. By default, the commit interval is set to be 100 milliseconds but you may want to tune that based on the application Interacting with External Systems and the performance you want to have. The last thing I want to talk about is caveats for using transactions. So far, all we have talked about with transactions only covers the interactions within the land of Kafka. But sometimes, you may want to do some processing, generate some output and eventually, you want that output to be exposed to some external systems, maybe like an external database. Now, how do you coordinate between these two separate systems? In Kafka, we don't really support two-phase commit. So the transactional support we have is only within Kafka. So to support interactions with two systems, the typical way you do it is to turn that into two separate single transactions. You will first design your application so that you can generate output in the transaction application within Kafka. And you want to design this such that the transactional output can be idempotent. Then you will read this output and then write the data records from this output into the external system, like a database. If the output of the topic is idempotent, then you can apply the same changes potentially more than once to the external database, but you'll get the same effect. So that way, you can bridge the two systems better without introducing too much overhead like the two-phase commit would do. And that's it for this module. Thanks for listening.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.