Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Hands On: Process Messages with KafkaStreams and Spring Boot



Viktor Gamov
Developer Advocate (Presenter)
Hands On: Process Messages with Kafka Streams and Spring Boot
Note: This exercise is part of a larger course. You are expected to have completed the previous exercises.
In this exercise, you will process your “Hobbit” quotes, like you did in the previous exercises, and count the number of words in each. You can see the code for modules 1–10 in a combined GitHub repo and you can also refer there for a list of imports as well as a sample build.gradle file.
Configure KafkaStreams
-
Use @EnableKafkaStreams for your main application class (use the code from the previous exercises):
@SpringBootApplication @EnableKafkaStreams public class SpringCcloud3Application { -
Add a new class: Processor. In order to create a topology, use StreamsBuilder. Annotate with @Component and @Autowired.
@Component class Processor { @Autowired public void process(StreamsBuilder builder) { } -
Add SerDes as well as a KStream to specify the topic to read from:
@Component class Processor { @Autowired public void process(StreamsBuilder builder) { final Serde<Integer> integerSerde = Serdes.Integer(); final Serde<String> stringSerde = Serdes.String(); final Serde<Long> longSerde = Serdes.Long(); KStream<Integer, String> textLines = builder.stream("hobbit", Consumed.with(integerSerde, stringSerde)); } }
Add a KTable to Process Your Data
-
Next, add a KTable to process your streamed data, splitting each message into words with flatMapValues, grouping, and then counting:
@Component class Processor { @Autowired public void process(StreamsBuilder builder) { final Serde<Integer> integerSerde = Serdes.Integer(); final Serde<String> stringSerde = Serdes.String(); final Serde<Long> longSerde = Serdes.Long(); KStream<Integer, String> textLines = builder.stream("hobbit", Consumed.with(integerSerde, stringSerde)); KTable<String, Long> wordCounts = textLines .flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+"))) .groupBy((key, value) -> value, Grouped.with(stringSerde, stringSerde)) .count(); } }Note that you also added a serializer and deserializer for grouping (in groupBy).
Convert Your KTable into a KStream
-
Now convert your KTable into a new KStream to write to the output topic:
@Component class Processor { @Autowired public void process(StreamsBuilder builder) { final Serde<Integer> integerSerde = Serdes.Integer(); final Serde<String> stringSerde = Serdes.String(); final Serde<Long> longSerde = Serdes.Long(); KStream<Integer, String> textLines = builder.stream("hobbit", Consumed.with(integerSerde, stringSerde)); KTable<String, Long> wordCounts = textLines .flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+"))) .groupBy((key, value) -> value, Grouped.with(stringSerde, stringSerde)) .count(); wordCounts.toStream().to("streams-wordcount-output", Produced.with(stringSerde, longSerde)); } }
Establish a New Topic
-
You also need a new topic counts, which you’ll establish using TopicBuilder (see Create Apache Kafka Topics with TopicBuilder).
@Bean NewTopic counts() { return TopicBuilder.name("streams-wordcount-output").partitions(6).replicas(3).build(); }
Set a Replication Factor for Kafka Streams and Run Your Application
-
Specify a replication factor for Kafka Streams in your application.properties (this is a Confluent Cloud specified default) and also an application-id:
spring.kafka.streams.replication-factor=3 spring.kafka.streams.application-id=spring-boot-streams -
Run your application.
Inspect Your Data on Confluent Cloud
- When you switch to Confluent Cloud, you should see your newly created topics, including streams-wordcount-output:
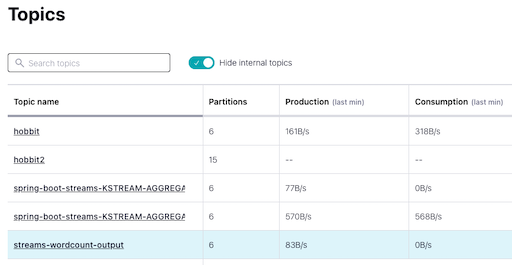-
Click on streams-wordcount-output, then Messages, then on the icon in the upper-right-hand corner:

You can see each word as a key:
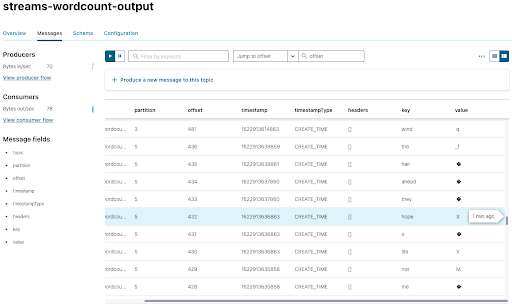
The values aren’t able to be parsed by JavaScript because we are using a Long serializer, which is Java specific, and it adds some bytes that aren’t standard. Fortunately, you can modify your consumer to read the data in your console.


Modify Your Data for the Console
-
In your consumer, change the name of the topic to streams-wordcount-output and the ConsumerRecord types to String and Long:
@Component class Consumer { @KafkaListener(topics = {"streams-wordcount-output"}, groupId = "spring-boot-kafka") public void consume(ConsumerRecord<String, Long> record) { System.out.println("received = " + record.value() + " with key " + record.key()); } } -
You also need to change your consumer deserializers in application.properties:
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.LongDeserializer -
Run the program to see the word counts.
Create a REST Service
Kafka Streams and Spring Boot are particularly powerful when you use a REST endpoint where the application’s state store can be accessed.
-
Begin by creating a class RestService that will expose some of the information about the state store from within the Kafka Streams application. You’ll use a streamsBuilderFactoryBean that lets you get access to the Kafka Streams instance.
@RestController @RequiredArgsConstructor class RestService { private final StreamsBuilderFactoryBean factoryBean; @GetMapping("/count/{word}") public Long getCount(@PathVariable String word){ final KafkaStreams kafkaStreams = factoryBean.getKafkaStreams(); final ReadOnlyKeyValueStore<String, Long> counts = kafkaStreams.store(StoreQueryParameters.fromNameAndType("counts", QueryableStoreTypes.keyValueStore())); return counts.get(word); } } -
You now have the REST endpoint but not the store. So you need to add the following to your KTable to create the local state store that will be available for querying:
KTable<String, Long> wordCounts = textLines .flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+"))) .groupBy((key, value) -> value, Grouped.with(stringSerde, stringSerde)) .count(Materialized.as("counts")); wordCounts.toStream().to("streams-wordcount-output", Produced.with(stringSerde, longSerde)); -
Now you can go to localhost:8080/count/dragon,for example, and see a count of the appearances of the word “dragon.”
You now know how to use Spring Boot with Kafka Streams as an API server, not just as a processing application!
Look at Data Lineage on Confluent Cloud
-
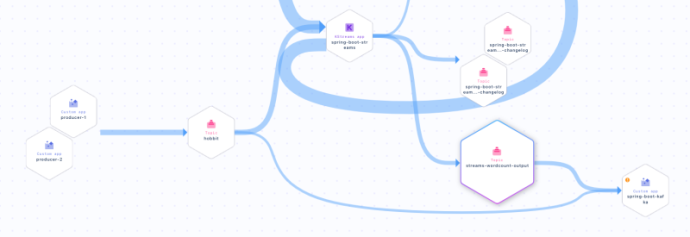
Finally, take a look at the Data Lineage for your topic streams-wordcount-output on Confluent Cloud (go to Topics > streams-wordcount-output > Data Lineage). You can see your producers feeding your hobbit topic, which flows into your Kafka Streams app spring-boot-streams, then through to your streams-wordcount-output topic, and finally to your spring-boot-kafka consumer.

Use the promo code SPRING101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Hands On: Process Messages with KafkaStreams and Spring Boot
Hi, this is Viktor Gamov of confluent. KafkaStreams is a Java library that allows you to write stream processing applications. Spring Boot and Spring Kafka includes support for KafkaStreams. So you can include this capabilities and write your event driven microservices using spring boot, and the KafkaStreams. So let's take a look how we can do this. For the purpose of today Exercise, we're gonna be using this classic example of all possible data processing frameworks. We're gonna be using workouts since we already have some information from book. In this particular case we have information from our Hobbit book. We're gonna process this, and get the count of words, how many words, and how often they occur in this quote. So let's get to it. For the sake of this exercise. I'm not gonna start writing this KafkaStreams from scratch, even though it's pretty simple to do I will use a use a quick-start that's available on the confluent website. That already have everything that I need. So if you want to learn a little bit more about KafkaStreams, go to our YouTube channel, or on developer.confluent.io. You can find materials about KafkaStreams. In this case. I want to show you some of the integration bits that available for you in spring boot and spring Kafka let's create another Class called processor. And now processor class, we will have a methods called public void process. In order to use, or create a topology in our application we need to use streams builder that's class that will be used to instantiate KafkaStreams instance. In spring boot already have support to this. so it can inject streams builder in our code. So we don't need to do this manually. So let's just do this one. Call it builder and this is gonna be implementation. Now in order to do so. We need to say, it's going to be out to wired. Also I need to say this is a component. And also I need to tell this spring boot application that enable KafkaStreams. In this case, it will start looking for certain configurations. We're gonna be talking about, in a few seconds. In our Spring StreamsBuilder we're gonna be using all these kind of things here. This is where we initialize our serializers. That's what we would, next thing is that we need to specify, where we need to read this data. So since we already have this data in our Hobbit topic, we're gonna be using this one. So next thing is that, in this particular case we don't specify. So we were gonna be doing the split. We're gonna be splitting all these sentences, all these quotes into words. And after that, we group by key. In this particular key would be word. I know for a fact that we need to also specify a serializer and deserializer here, for grouping. So in this case, we will be group as a string serde, And as a value, we are gonna be using string string. So we are gonna be using string as our key. We're gonna be grouping by key. So in this case, we need to specify those serde. And another thing that we consuming this message not from the string string, we consume in this message from serdes dot Integer. I'll create the variable intergerSerde. And we consume this as an integerSerde over here and integer over here. So we've fixed our types. Our builder was injected here. We're creating a stream here. And next thing is that we do have these streams word count topic. Now on the previous lessons we'll learn how we can create a new topic. So in this case, we're gonna say, new topic counts. Return topic builder, name and with a number of partitions. It's gonna be six, and replication factor is three. And we're on the build method and we'll make it as a bean. So in our application configuration we'll also need to specify couple of things. So Kafka streams, replication factor. For all internal topics that Kafka streams will create, for repartitioning, for state store. All these topics also needs to have a replication factor. We need to set this here in the configuration because it will not allow me to create the topics with default replication factor which is one. That's what I need to do. It's a confluent cloud specific, or if you have a cluster that runs on certain defaults. Confluent cloud, always enforcing some of the good defaults that you as a user, needs to be aware. And basically don't need to think about this. And also I need to do Kafka streams, application ID we'll call it spring boot streams. So in this case it will be using this as our application ID. It's also mandatory field that we need to create for our application. And once again, let's see what we're doing here. We're reading these messages from our hobbit. We are doing some parsing in our application side of things. And after that, we do grouping. We do count. And after that, we writing the result back to topics. So in this case, we will be able to see some of them alright. Go ahead and run this application. We'll be looking for running state. So it's going into states that topic was not created. So it created this topic. Now applications should be up and running. And we should be able to see application state translation from rebalancing to running. So application is up and running. Now, when I switch from my application code into my confluent cloud UI. I should be able to see all these topics that were created. And there's a topic called a word count output that we created programmatically. We also can see that some of the data is actually arriving to this topic. So let's take a look. What do we have here. In messages UI we will be able to see the counts in this case. We're gonna be using key is our string, as our word, and our count would be our value. That's we supposedly should be able to see in a few seconds. So let's take a look in a different view. So what we see here, our key is actually our word. And our value is something that JavaScript UI will not be able to read. Why is that? Because we're using long serializer which is a Java specific. So it puts some bytes that not standard since we use using string and the Java usually produce UTF-8 a unicode string. So it will be able to consume the string anywhere. So in this case, including the JavaScript so we see something is going out here. But the way how we can read this data we can modify our consumer, and read this data from the console. So let's get to it. At start, stop my application go to my consumer code. I will change the name of the topic, to streams, word count. This is gonna be what we're gonna be consuming here. And consumer record, in this case is gonna be string and long Also, we need to modify consumer code. So in this case, it will be using as a key string deserializer. And that we'll be using as a value long deserializer. And now I should be able to see all this messages in my console. So once again, my producer will create the quotes for the Hobbit. My KafkaStreams application, we'll try to do word count. And my consumer now we'll be writing this down in our console. So let's get to it and let's see how it works. We should be able to see those messages in a few seconds. So this is our key. Let's see if it enhances baggings a dragon. All right. So some dragons here, and we know getting the count of this. Now, all this is very interesting and it's very cool. But really a place where the KafkaStreams and spring boot really shine together. When we need to build a restaurant point to access this state store for this application. So in this case, instead of reading through all this topic and the reading all this messages here we'll try to get access to those on demand. So that's the next thing that we're gonna to be doing here. So let's create another class. We're gonna call it a rest controller that will expose some of the information about the state store. From within Kafka streams application to a rest API. Rest service. And it's going to be a rest controller. We're gonna be using this streams builder, factory bean that allows us to get access to KafkaStreams instance, and KafkaStreams instance allows us to get access to a state store. So that's gonna be, what we're gonna be using here. And a it's gonna be a private final. We're gonna be using a required argument constructor as well to generate this. So that we'll be using this, in the next thing is the public say, we need to get counts and it's gonna be long and get count. We're gonna be using string as our word that we need to get access word, and that's gonna be our code return something. Now it's gonna be, get mapping. We're gonna be using this say slash count slash word. And in this case we're gonna be using this path very able as a word. Now from the factory bean, we can get a KafkaStreams instance. So KafkaStream instance this is all your like KafkaStreams API, that's your instance of KafkaStreams. So from this, I can do store query parameter for names and type. So we need to have a store name. We'll get back to it counts. Next thing is that style is a key value store. What's the queryable store types dot and it's key value store. Now we're getting these store where our counts end will be string, and it's gonna be a long. And when I do counts dot get by key, I put the word. And this is what I will be returning to my application. Now, So we have this REST endpoint, but we don't have the store name. So in order to do so, we need to get back to our word counts, and materialized as counts. So in this case, it will create the local state store of the name counts that will be available for querying. If you want to learn more about how does it work? We have a materials in our developer.confluent.io website. Where you can learn all about KafkaStreams and how the state store works. Also, you can check out this confluent YouTube channel. With the live streams play list, where you can find all things around materialized view. I always talk about this in a lot in the details in the past. So let's see how this will work. So now I will restart my application. So now what I can do here, I can do HTTP to my 8080. And in this case, I'm gonna do what was the end point? Count slash corporate? So three times a hobbit was appearing here. So maybe something like, I dunno like dragon. 11 times dragon. So in this case, my application my KafkaStreams spring boot applications, not only a processing application, but also is API server. In this case, my instance of my application also exposes some of the internal information to outside world. Now let's recap what we learned today. So you can use KafkaStreams applications inside spring boot. You need to just enable integration by enabling this, this annotation. You will be able to, just inject the streams builder, and the KafkaStreams instance will be managed by spring. Also from this bean stream builder factory bean, you will be able to get access to instance of this application. In case you need to get access to state stores like this one. I'm getting the state store for name counts. And for the type is the key value store that allows you to expose this store to outside world, and make it your application is API server. And once again, so let's take a look what do we have here. So we have a topic with these data that generated. We do have a streams counts, and the data is processing here. Let's use this very nice data lineage, thing. So we will see that there's some bunch of applications producing this data, into my topic with hobbit. We have a KStreams application that processes data and writes data inside this streams count topic. This topic also consumed by spring boot Kafka application, which is my consumer now. And there's bunch of other things we're using some of the topics to save the state for this application. All right, so now you have it. Now you know how we can use KafkaStreams, together with spring boot and spring Kafka you can use powerful state full stream processing library that allows us not only to do processing but also expose state and intermediate computation through the rest API that available in Spring Boot. Stick around for a new learnings. And don't forget to check out developer.confluent.io and the confluent YouTube channel.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.