Enhance your career, get your certificate as a Data Streaming Engineer | Get your Certificate
Aggregating Flink Data using Windowing (Exercise)



Wade Waldron
Principal Software Practice Lead
Aggregating Flink Data using Windowing (Exercise)
Note: This exercise is part of a larger course. You are expected to have completed the previous exercises.
In this exercise, we are going to start implementing a new Flink Job. This new job will consume the data from our flightdata topic and use it to aggregate some statistics about individual users.
Once we have collected, and calculated the necessary statistics, we will push them out onto a new topic named userstatistics.
The basic flow of this new job is illustrated below:
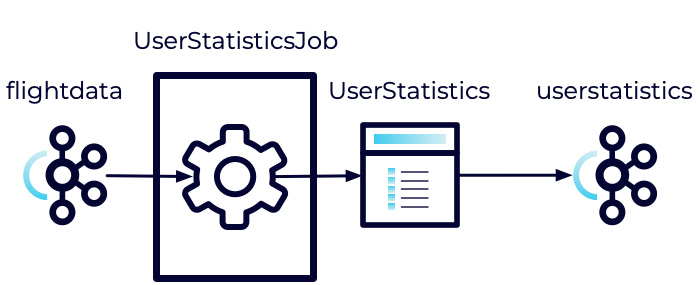
The UserStatistics class will consist of three fields including emailAddress, totalFlightDuration, and numberOfFlights.

Essentially, as each flight record passes through our system, we'll accumulate data for each individual user to determine the totalFlightDuration and the numberOfFlights.
We've taken the liberty of implementing some of this for you. Most of the boilerplate for the UserStatistics and UserStatisticsJob classes has been created. Both will be made available when you stage the exercise.
Stage the Exercise
Stage the exercise by executing:
./exercise.sh stage 18Create a new Kafka topic
Our first step is to create a new Kafka topic to hold our User Statistics.
- In Confluent Cloud, create a new topic named userstatistics.
- Use the default settings.
- Skip creating a schema.
Add a merge function to the UserStatistics
Next, we are going to add a merge function to our UserStatistics model. The purpose of this function is to take two different UserStatistics objects and merge them into one. This merge will add the flight durations and the number of flights together to produce a single total for each.
- Open the UserStatistics class.
- Define a new public function named merge that takes a single parameter of type UserStatistics and returns a new UserStatistics.
- Define the function as follows.
- Verify that the current (this) object and the incoming object have the same email address. If they don't, throw an AssertionError.
- Hint: You can use assert.
- Create a new UserStatistics object.
- Set the emailAddress for the new UserStatistics to equal either the current one, or the incoming one (they should be the same).
- Set the totalFlightDuration for the new UserStatistics to equal the sum of the current totalFlightDuration and the incoming totalFlightDuration.
- Hint: You can use Duration.plus.
- Set the numberOfFlights for the new UserStatistics to equal the sum of the current numberOfFlights and the incoming numberOfFlights.
- Return the new UserStatistics object.
- Verify that the current (this) object and the incoming object have the same email address. If they don't, throw an AssertionError.
Implement the defineWorkflow function.
Next, we will implement the defineWorkflow function to create our stream.
The layout of the stream we are creating looks something like this:
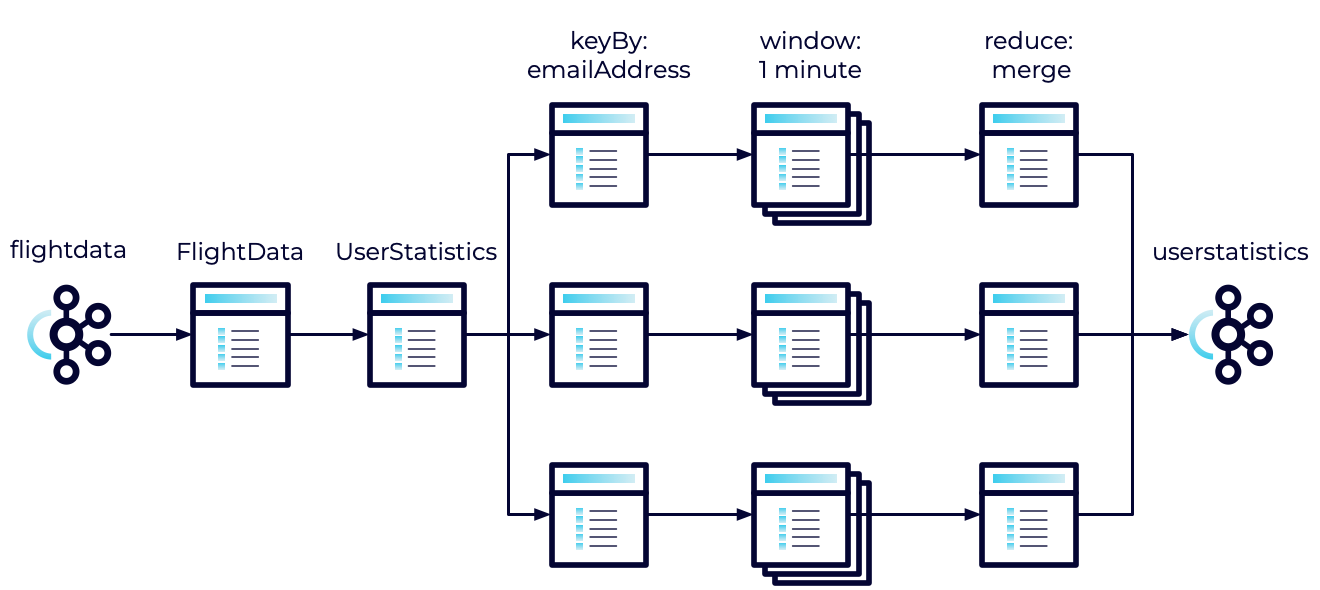
We'll take the incoming FlightData, convert it to UserStatistics, use keyBy to partition it into streams based on the email address, accumulate records in a one-minute tumbling window, use reduce to aggregate those statistics, and finally send them back to Kafka.
This seems fairly complicated. But as you will see, Flink makes it easy.
- Open the UserStatisticsJob.
- Take a moment to review the code. It isn't doing anything new. It's just pulling data from a KafkaSource and pushing it to a KafkaSink.
- Locate and update the values of <INPUT_TOPIC> and <OUTPUT_TOPIC>. The input topic will be flightdata and the output topic will be userstatistics.
- Locate the defineWorkflow function. Currently, it returns null.
- Implement the function as follows:
- Use map to convert each of the FlightData objects in the flightDataSource to a new UserStatistics object
- Hint: Have a look at the constructors for UserStatistics.
- Use keyBy to partition the stream by the emailAddress.
- Use window to create a tumbling event time window of one minute.
- Use reduce to merge each UserStatistics object with the previous one.
- Return the resulting stream.
- Use map to convert each of the FlightData objects in the flightDataSource to a new UserStatistics object
Run All Tests
As always, you can run the tests to verify your application is behaving as expected.
mvn clean testExecute the Jobs
We'll be executing an extra job this time. You may need to open an additional terminal.
- Build and package the jar file:
- Execute the DataGeneratorJob.
- Execute the FlightImporterJob.
- Execute the UserStatisticsJob.
Note: Feel free to use the start-datagen.sh, start-flightimporter.sh, and start-userstatistics.sh shell scripts here.
Inspect the Messages
Inspect the messages in Confluent Cloud.
- Navigate to the userstatistics topic.
- Select the Messages tab.
Note: Because messages are windowed over a 1 minute period, we wouldn't expect to see results until about one minute after starting the application. However, even if you wait longer than this you still won't see any messages. What happened?
Enable Watermarks
The problem we've encountered is that Windowing functions require watermarks in order to operate properly. Essentially, the watermarks are used to measure when a window starts and ends. However, we haven't enabled any watermarks in our stream. As a result, the stream can't produce any new windows. So let's go ahead and fix that.
- Open the UserStatisticsJob.
- Locate the code that sets the watermarks to WatermarkStrategy.noWatermarks().
- Change this to WatermarkStrategy.forMonotonousTimestamps().
We've now said that our events will contain timestamps that continuously increment. These timestamps are automatically defined inside the Kafka events. This should be enough to get our stream working.
Execute the Jobs
- Cancel the UserStatisticsJob.
- Build and package the jar file:
- Execute the UserStatisticsJob.
Inspect the Messages
Now, take another look at the messages in Confluent Cloud.
- Navigate to the userstatistics topic in Confluent Cloud.
- Select the Messages tab.
After about a minute you should start to see messages that look something like this:
{
"emailAddress": "HFRQC@email.com",
"totalFlightDuration": 21000,
"numberOfFlights": 1
}Note: You should see a few records that have the numberOfFlights higher than 1. However, it's unlikely you will see numbers much higher than 2 or 3. This is because the likelihood of two records having the same email address within the same minute is quite low, and we reset the total with each new window. But what if we didn't want to reset the total for each new window? What if we wanted to accumulate the total across windows? That's what we will learn next.
Finish
This brings us to the end of this exercise.
Use the promo codes FLINKJAVA101 & CONFLUENTDEV1 to get $25 of free Confluent Cloud usage and skip credit card entry.
Be the first to get updates and new content
We will only share developer content and updates, including notifications when new content is added. We will never send you sales emails. 🙂 By subscribing, you understand we will process your personal information in accordance with our Privacy Statement.